

H200 SXM и RTX 5090 от NVIDIA входят в число самых мощных GPU своего класса, однако они служат совершенно разным целям в экосистеме ИИ. RTX 5090 превосходит других в задачах высокоскоростного инференса и тонкой настройки моделей небольшого масштаба, в то время как H200 SXM оптимизирован для крупномасштабного обучения и развертывания нескольких GPU в дата-центрах.
В этой статье мы сравниваем обе GPU по архитектуре, памяти, производительности и стоимости, чтобы помочь вам определить, действительно ли ваши рабочие нагрузки требуют GPU для дата-центра, или одной RTX 5090 уже достаточно для достижения ваших целей в области ИИ.
H200 против 5090: Подробные спецификации
| Параметр | H200 SXM | RTX 5090 |
| Дата выпуска | 18 ноября 2024 | 30 января 2025 |
| Архитектура | Hopper | Blackwell |
| Объем GPU памяти | 141 ГБ HBM3e | 32 ГБ GDDR7 |
| Интерфейс памяти | 6144-битный | 512-битный |
| Пропускная способность памяти | 4,8 ТБ/с | 1,792 ТБ/с |
| Декодер NVIDIA | 7x NVDEC и 7x JPEG | 3x 9-го поколения |
| Ядра CUDA | 16896 | 21760 |
| Тензорные ядра | 528 | 680 |
| Общая тепловыделение графического процессора | до 700 Вт | 575 Вт |
H200 против 5090: Подробный обзор производительности
H200 SXM и RTX 5090 от NVIDIA служат двум принципиально разным рынкам. В то время как RTX 5090 разработана для вывода рабочих нагрузок потребителей и создателей контента на новый уровень, H200 SXM создана специально для ИИ масштаба дата-центра, где критически важны пропускная способность, объем памяти и развертывание кластеров.
Чтобы сделать правильный выбор, необходимо оценить, как их сильные стороны соответствуют требованиям ваших реальных рабочих нагрузок.
🟩 RTX 5090: Флагманская потребительская GPU
Разработанная для энтузиастов, разработчиков и создателей контента, RTX 5090 ориентирована на сырую скорость, гибкость и широкий охват приложений. Она позволяет быстро итерировать и экспериментировать с ИИ, пока модель помещается в бюджет памяти потребительской GPU.
- Максимальная пропускная способность для локального прототипирования
Благодаря сверхширокой пропускной способности памяти и мощным тензорным ядрам и ядрам RT, она превосходит других в быстрой итерации моделей, рендеринге и смешанных рабочих процессах творческого ИИ.- Доступный вход в высококлассный ИИ
Как потребительская GPU, она обеспечивает исключительное соотношение цены и производительности для пользователей, которые хотят получить передовые вычислительные мощности без корпоративной инфраструктуры.- Стабильная отзывчивость в реальном времени
Высокие тактовые частоты RTX 5090 и эффективная архитектура обеспечивают стабильную генерацию кадров и быстрые циклы инференса, что идеально подходит для тестирования или живых творческих сессий, где важна задержка.- Оптимизированная разработка и развертывание ИИ
RTX 5090 позволяет эффективно выполнять локальную тонкую настройку, инференс и оптимизацию моделей, позволяя разработчикам бесшовно итерировать и масштабировать рабочие нагрузки ИИ без необходимости полагаться на сложную облачную инфраструктуру.
🟦 H200 SXM: Высококлассная корпоративная GPU для ИИ
Созданная для критически важных развертываний в дата-центрах, H200 делает акцент на объеме памяти, эффективности пропускной способности и масштабируемости нескольких GPU для современных систем генеративного ИИ.
- Огромный объем памяти для производственных моделей
Оснащенная 141 ГБ HBM3e, она обрабатывает большие языковые модели, плотное извлечение информации и инференс с длинным контекстом с минимальными накладными расходами на шардирование.- Высоконадежная корпоративная производительность
Разработана для стабильного времени безотказной работы, тепловой эффективности и строго контролируемого исправления ошибок для критически важных рабочих нагрузок.- Максимизированная эффективность кластеров
NVLink и NVSwitch пятого поколения поддерживают высокоскоростное соединение между несколькими GPU, что идеально подходит для распределенного обучения и масштабирования больших языковых моделей (LLM).- Оптимизация под FP8 и Transformer Engine
Ускоряет передовой генеративный ИИ, обеспечивая выдающуюся пропускную способность обучения и инференса в оптимизированных фреймворках (NVIDIA NIM, TensorRT-LLM).
Ключевые выводы
- RTX 5090 → Лучший выбор для отдельных пользователей или небольших команд, для которых важны скорость, гибкость и экономическая эффективность в локальных рабочих процессах — идеально подходит для быстрого прототипирования и творческого ИИ.
- H200 SXM → Лучший выбор для корпоративных сред ИИ, требующих масштабируемости, огромного объема памяти и ультранадежных вычислительных мощностей для крупномасштабных развертываний и стабильной работы 24/7.
Какую GPU выбрать?
Выбор между RTX 5090 и H200 SXM в конечном итоге зависит от вашей среды развертывания, бюджета и масштаба ваших моделей — а не только от показателей производительности на бумаге.
Какого размера модели вы планируете запускать локально?
Если веса вашей модели (плюс кэш KV и активации) помещаются в 32 ГБ видеопамяти (или могут быть квантованы для этого), RTX 5090 — отличное локальное решение.
Если они превышают этот лимит или требуют распределенных вычислений с высокой пропускной способностью, H200 SXM создана специально для такого масштаба.
🔍 Краткое руководство по выбору
| Ваша потребность / Сценарий использования | Рекомендуемая GPU | Почему |
|---|---|---|
| Быстрая итерация, локальное прототипирование ИИ, творческие рабочие нагрузки | RTX 5090 | Отличное соотношение цены и производительности + поддержка широкого спектра рабочих нагрузок |
| Модели 7B–14B в FP16 или 30B в квантованном виде | RTX 5090 | 32 ГБ видеопамяти достаточно для большинства LLM среднего масштаба |
| LLM объемом ≥70B, инференс с длинным контекстом | H200 SXM | 141 ГБ HBM3e обеспечивает полное размещение модели + кэша KV в памяти |
| Критически важные производственные развертывания | H200 SXM | Корпоративная надежность, память с ECC, контроль температуры |
| Масштабирование нескольких GPU через NVLink и кластеры | H200 SXM | Разработана для параллельного обучения и распределенных рабочих нагрузок |
| Высокая параллельность и пропускная способность | H200 SXM | Оптимизирована для рабочих нагрузок дата-центра |
H200 против 5090: Цены
| GPU | Типичная цена | Примечания |
|---|---|---|
| RTX 5090 | ~ 1999 долларов США (MSRP, рекомендуемая розничная цена) | Потребительская видеокарта, 32 ГБ памяти GDDR7, ориентирована на геймеров и создателей контента. |
| H200 SXM (одна GPU) | 30 000 ~ 40 000 долларов США за штуку | GPU класса дата-центра, 141 ГБ памяти HBM3e, создана для крупномасштабных развертываний ИИ. |
| Серия H200 (плата/система) | 4-GPU плата ≈ 175 000 долларов США, 8-GPU плата ≈ 308 000 ~ 315 000 долларов США |
Цельная многопроцессорная система, включающая несколько модулей H200, плату NVLink/NVSwitch, серверную инфраструктуру. |
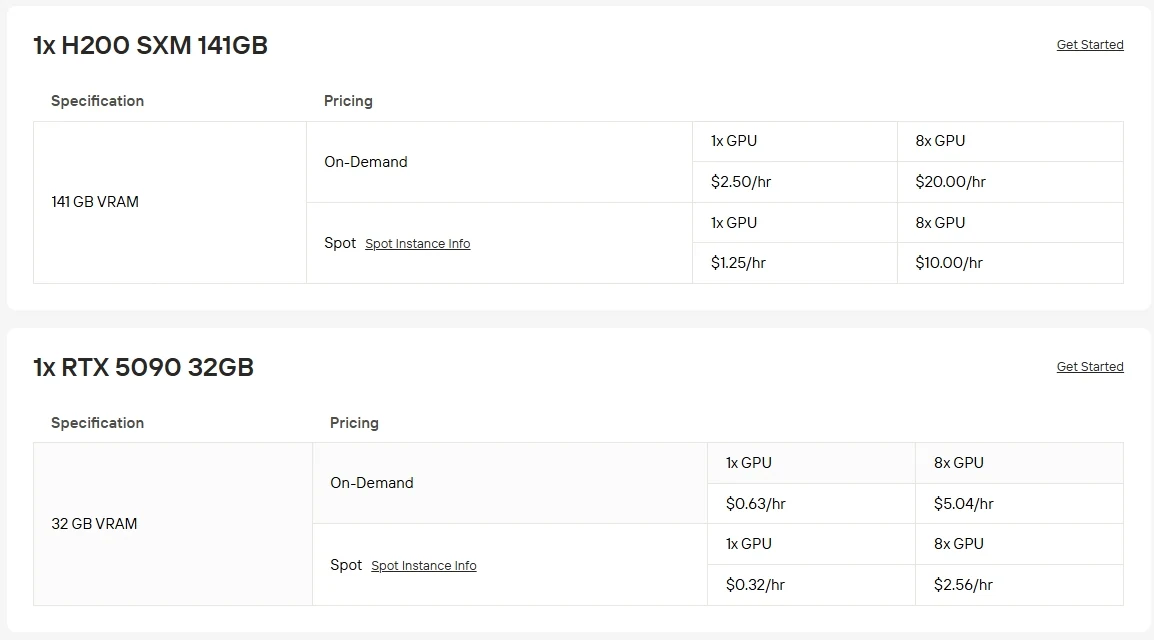
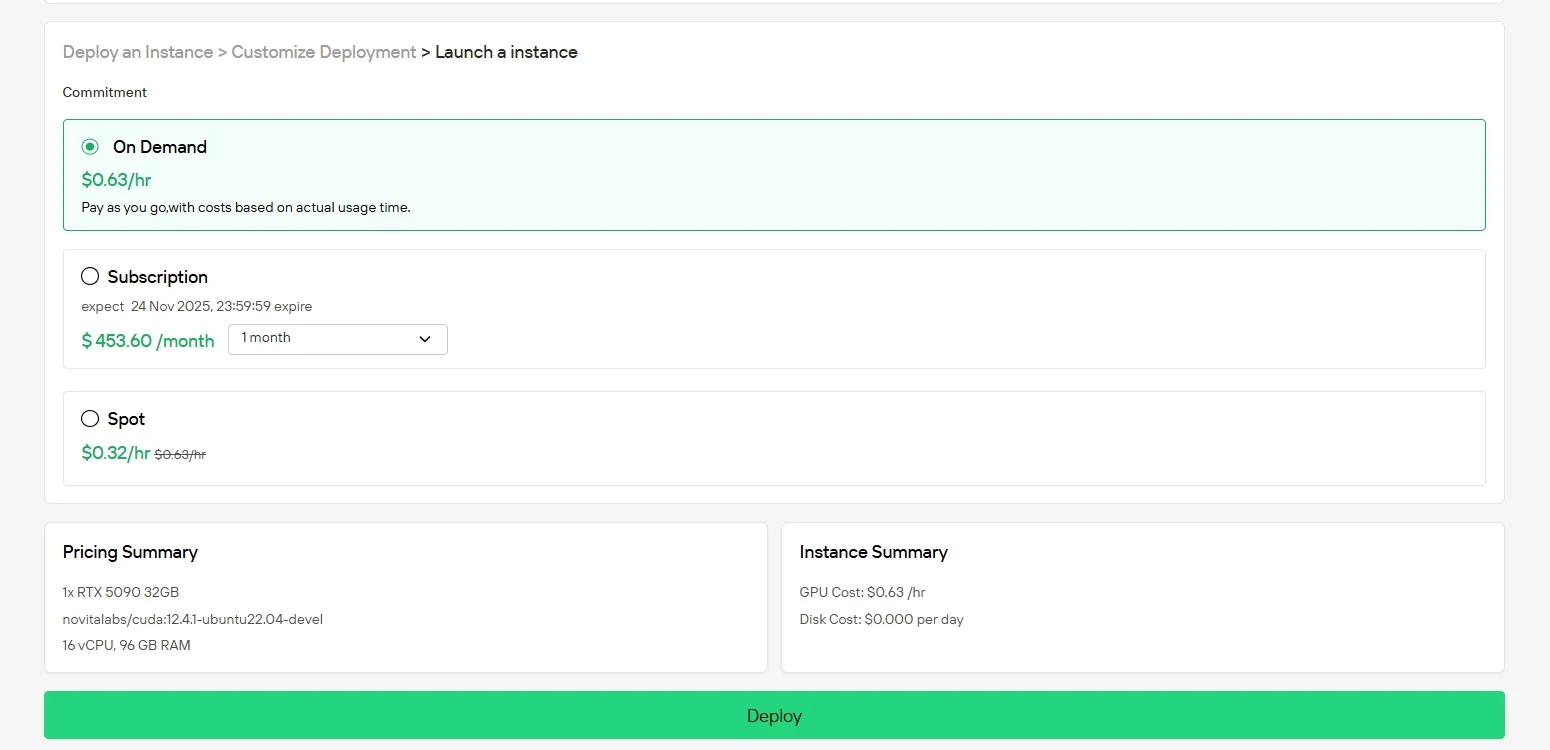
Эксплуатация флагманских GPU на собственном оборудовании может быть дорогой и сложной в обслуживании. С сервисом GPU-инстансов Novita AI вы можете быстро получить облачный доступ к RTX 5090 всего за 0,63 доллара США в час или к H200 SXM за 2,5 доллара США в час без необходимости локальной настройки. Вы также можете выбрать один из нескольких вариантов оплаты: спотовые инстансы Spot instances предлагают более низкие цены при изменяющейся доступности, инстансы On-Demand позволяют платить только за фактическое использование, а подписочные планы Subscription plans обеспечивают стабильную экономию для стабильных долгосрочных рабочих нагрузок.
Начните работу с гибкими GPU-инстансами на Novita AI
Novita AI предлагает масштабируемые ресурсы RTX 5090 и H200 в облаке, избавляя от необходимости покупать и обслуживать дорогое оборудование для интенсивных вычислительных рабочих нагрузок.
Шаг 1:Зарегистрируйте учетную запись
Создайте учетную запись Novita AI на нашем сайте. После регистрации перейдите на вкладку «GPUs», чтобы просмотреть доступные ресурсы и начать работу.
Попробуйте RTX 5090 и H200 сейчас
Шаг 2:Выберите вашу GPU
Мы предлагаем множество предварительно настроенных шаблонов для удовлетворения разнообразных потребностей, а также даем вам возможность создавать собственные. Благодаря доступу к мощным GPU RTX 5090 и RTX 6000 Ada с большим объемом видеопамяти и оперативной памяти, наш сервис позволяет эффективно обучать даже очень сложные модели ИИ.
Библиотека предварительно настроенных шаблонов
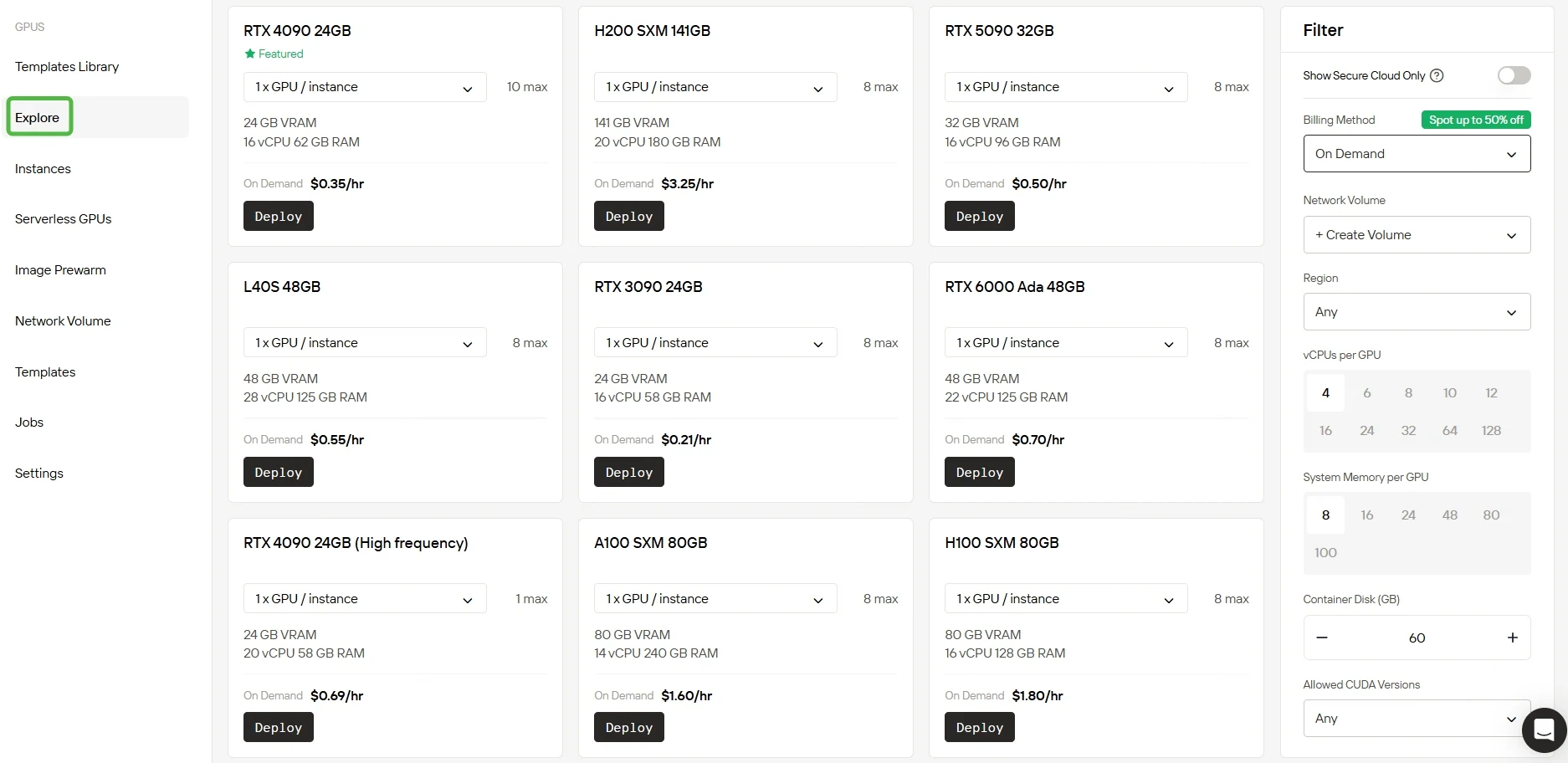
Изучите разнообразные варианты GPU
Шаг 3:Настройте ваше развертывание
Настройте среду с операционной системой и конфигурацией, которые соответствуют вашим вычислительным требованиям, оптимизируя пропускную способность для рабочих нагрузок ИИ. При запуске вы получите 60 ГБ бесплатного дискового пространства для контейнеров, с простым масштабированием до дополнительного хранилища по мере роста вашего проекта.
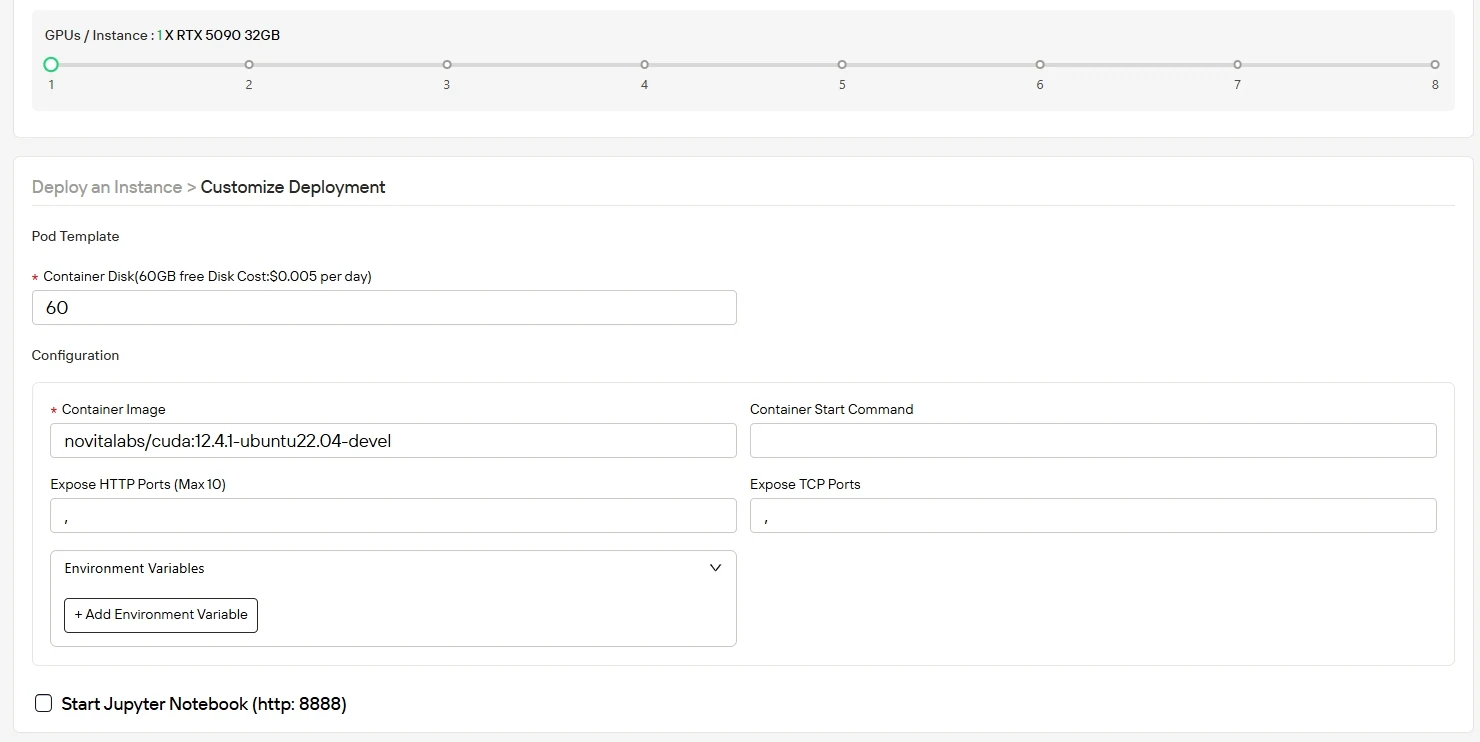
Шаг 4:Запустите ваш инстанс
Нажмите «Развернуть», чтобы начать развертывание. В течение нескольких минут ваша высокопроизводительная GPU-среда будет готова, что позволит вам сразу же начать проекты в области машинного обучения, рендеринга или вычислительных задач.
Часто задаваемые вопросы
В чем основное отличие между RTX 5090 и H200 SXM?
RTX 5090 — это потребительская GPU, разработанная для высокопроизводительных настольных компьютеров; в отличие от нее, H200 SXM — это GPU класса дата-центра, созданная для крупномасштабных развертываний ИИ, с корпоративной надежностью, масштабируемостью NVLink и огромным объемом памяти HBM3e для поддержки больших моделей и рабочих нагрузок с высокой пропускной способностью.
Какие рабочие нагрузки ИИ действительно требуют H200 SXM?
Рабочие нагрузки, связанные с моделями объемом 70B и выше, инференсом с длинным контекстом, распределенным обучением или высокой параллельностью, значительно выигрывают от объема памяти и пропускной способности interconnect H200.
Достаточно ли RTX 5090 для локального запуска больших языковых моделей?
Да — при условии, что модель помещается в 32 ГБ видеопамяти или может быть квантована. Модели с объемом около 7B–14B параметров работают плавно; 30B могут работать при агрессивной оптимизации.
Novita AI — это облачная платформа ИИ, которая предлагает разработчикам простой способ развертывать модели ИИ с использованием нашего простого API, а также предоставляет доступное и надежное облако GPU для построения и масштабирования решений.



