

GLM 4.6V is available on Novita AI as a serverless multimodal model for teams that need vision AI with native tool calling through a hosted API. As of June 24, 2026, Novita AI lists the model ID as zai-org/glm-4.6v, OpenAI-compatible API access, a 131,072-token context window, 32,768 max output tokens, function calling, structured outputs, reasoning support, and pricing at $0.30 per 1M input tokens, $0.055 per 1M cache-read input tokens, and $0.90 per 1M output tokens.
Key Takeaways
- GLM 4.6V is a vision-capable model on Novita AI for teams building screenshot analysis, document-image understanding, visual QA, multimodal support, and agent workflows.
- Novita AI lists GLM 4.6V as a serverless model with text, image, and video input support, text output, OpenAI-compatible chat completions access, and Anthropic-compatible API support.
- The current Novita AI model and pricing pages list
zai-org/glm-4.6vwith a 131,072-token context window, 32,768 max output tokens, and per-token pricing split across input, cache-read input, and output tokens. - This article is a model launch and information page. Use it to decide whether GLM 4.6V fits your workload; use the Novita API reference when you need exact request syntax for production implementation.
What Is GLM 4.6V?
GLM 4.6V is a multimodal GLM model variant built for vision-language tasks. In practical developer terms, it is useful when the prompt needs to combine natural-language instructions with visual evidence such as screenshots, document pages, charts, dashboards, forms, or video-derived context.
Unlike a text-only chat model, GLM 4.6V is designed for cases where the visual input changes the answer. A support workflow may need to inspect a customer screenshot before suggesting a fix. A product team may want a model to compare a UI screenshot with expected behavior. A document automation route may need to reason over layout, tables, and visible labels that are hard to preserve after plain OCR extraction.
On Novita AI, GLM 4.6V is positioned as a serverless API option. That gives teams a straightforward way to evaluate and integrate the model without managing GPU infrastructure, model serving, scaling, or inference runtime setup. The practical path is to start from the Novita AI model page and API documentation, then connect through the OpenAI-compatible API surface.
GLM 4.6V API Access on Novita AI
Novita AI lists GLM 4.6V in the model library with the API model ID zai-org/glm-4.6v. For teams already using OpenAI-compatible chat completions, the main integration details are the Novita AI API key, the Novita AI base URL, and the GLM 4.6V model ID.
The current GLM 4.6V model page identifies the model-specific availability, modalities, limits, feature flags, and pricing. The Novita chat completions API reference documents the chat completions endpoint and response shape for API calls.
At a high level, a GLM 4.6V API integration uses:
| API item | Current value |
|---|---|
| API model ID | zai-org/glm-4.6v |
| OpenAI-compatible base URL | https://api.novita.ai/openai |
| Chat completions REST path | https://api.novita.ai/openai/v1/chat/completions |
| Typical output | Text response in chat completions format |
| Authentication | Novita AI API key passed as a bearer token |
This page focuses on the launch-level facts developers usually need first: availability, API access, pricing, limits, and fit. For exact request fields, streaming behavior, tool syntax, and structured-output parameters, use the current API reference before shipping production code.
GLM 4.6V Specs and Pricing Summary
The following table summarizes the GLM 4.6V facts that matter most when deciding whether to evaluate the model on Novita AI.
| Field | Details |
|---|---|
| Display name | GLM 4.6V |
| API model ID | zai-org/glm-4.6v |
| Access path | Serverless API |
| Base URL | https://api.novita.ai/openai |
| Chat completions endpoint | https://api.novita.ai/openai/v1/chat/completions |
| Input modalities | Text, image, video |
| Output modality | Text |
| Context window | 131,072 tokens |
| Max output tokens | 32,768 tokens |
| Feature flags | Function calling, structured outputs, reasoning |
| Pricing | $0.30 per 1M input tokens; $0.055 per 1M cache-read input tokens; $0.90 per 1M output tokens |
| Best fit | Vision-language API workflows that need text answers from visual evidence |
Pricing can change, so confirm the current Novita AI pricing page before production rollout or customer-facing cost commitments. The listed rates are useful for initial budgeting, but real spend still depends on prompt length, image or video usage, generated output length, retries, cache behavior, and the way your application handles long context.
GLM 4.6V Benchmark and Performance Signals
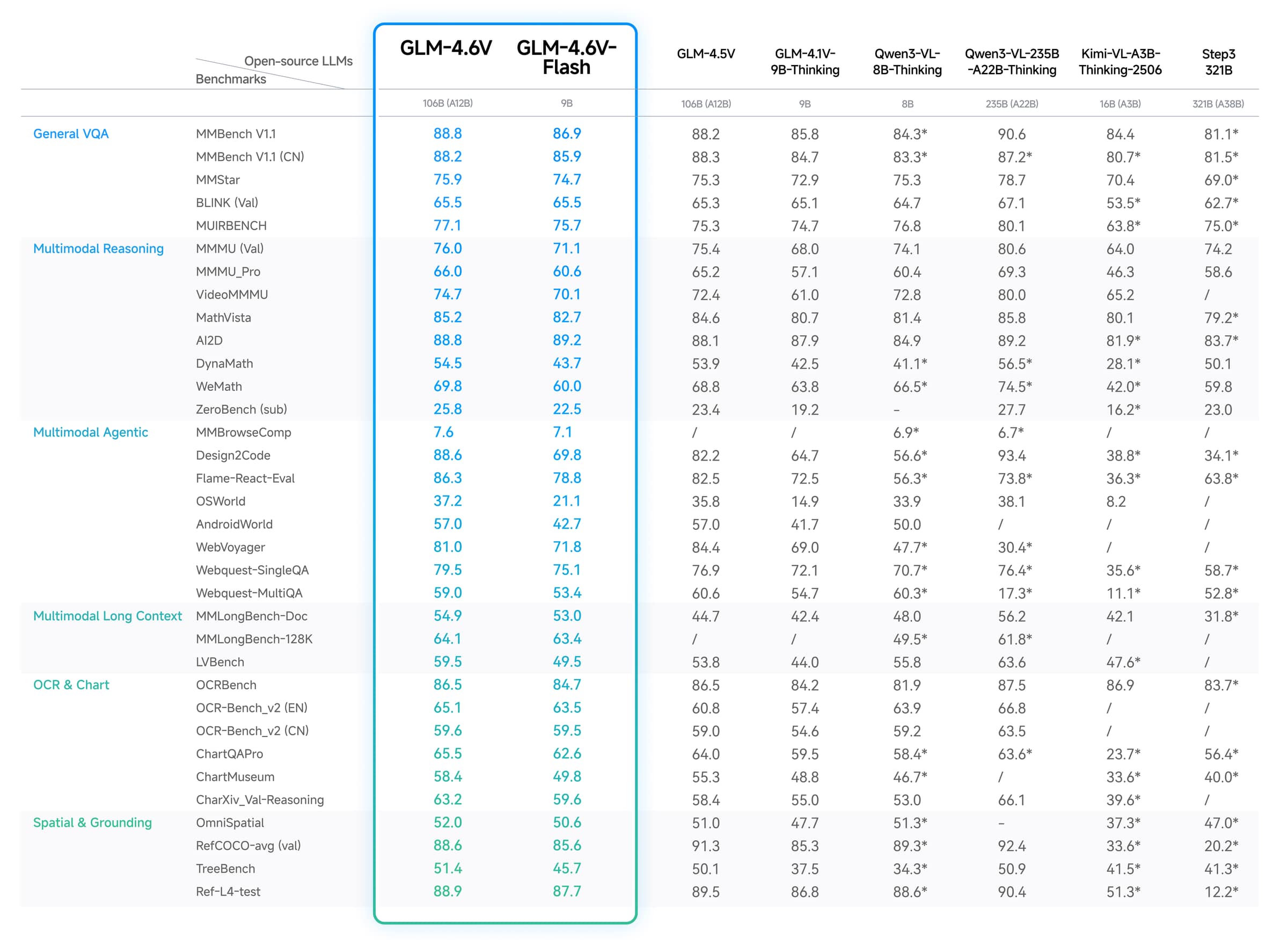
This chart comes from the official GLM-4.6V model materials published by Z.ai and mirrored in the public GLM-V repository. The main takeaway is breadth: GLM-4.6V is being positioned as a general-purpose vision-language model across OCR, chart reading, spatial reasoning, document understanding, and agent-style multimodal tasks.
The chart is still only a starting point. It does not tell you how well GLM-4.6V will follow your schema or how it will behave on your exact screenshot and document mix. Before rollout, check:
- representative screenshots and document pages from your real workflow,
- structured-output or tool-calling cases that must pass your parser,
- latency and cost at your typical context size.
Use the official chart as evidence that GLM-4.6V has broad multimodal ambitions, then make the final decision on your own accuracy, latency, and cost tests.
Key Capabilities for Developers
Vision Input for Screenshot and Document Workflows
GLM 4.6V is useful when your application needs to reason over visual input rather than only text. Product teams can summarize UI screenshots. Support teams can classify visual bug reports. Document workflows can preserve layout cues that are often lost when a page is converted into plain text too early.
This does not remove the need for validation. For high-stakes documents, private customer screenshots, or regulated data, make sure the workflow matches your privacy and data-handling requirements before sending visual input to an external API.
Long Context for Rich Multimodal Prompts
The 131,072-token context window gives teams room to combine instructions, conversation history, retrieved text, document excerpts, and visual references. That is valuable for tasks where the answer depends on several pieces of context, not a single isolated image.
Long context should still be treated as a budget and latency resource. Do not send unbounded conversation history or every available file by default. Trim, summarize, and route context based on the task.
Function Calling and Structured Outputs
Novita AI lists GLM 4.6V with function calling and structured-output support. That makes the model relevant for agent-style applications where visual understanding needs to connect to controlled application logic, such as creating a support ticket, selecting a retrieval tool, or returning a JSON classification object.
The application should remain the authority. It still needs to validate tool arguments, check permissions, enforce schema rules, and require confirmation before taking actions that affect user data, billing, or external systems.
When to Use GLM 4.6V
Visual Support Triage
Use GLM 4.6V when users submit screenshots along with text descriptions. The model can help summarize visible UI state, extract likely issue categories, and produce concise notes for a human reviewer or downstream workflow.
Document and Chart Interpretation
Use GLM 4.6V when the visual layout matters. Examples include scanned forms, report screenshots, table-heavy images, dashboard charts, and design artifacts where the answer depends on visible structure.
Multimodal Agent Workflows
Use GLM 4.6V when an agent needs to inspect visual state and then choose a structured next step. A visual QA agent, browser-style workflow, or operations assistant may benefit from combining visual context with function calling and structured outputs.
When Not to Use GLM 4.6V
Do not choose GLM 4.6V only because it is multimodal. If your route is text-only, short, latency-sensitive, and high volume, a text-focused model may be a better default. Compare models in the Novita AI model library and evaluate cost, latency, and output quality on your own prompts.
Avoid sending sensitive images or documents until the workflow has clear privacy, retention, and access-control rules. If it handles confidential customer records, medical information, financial documents, or internal credentials visible in screenshots, add redaction and policy checks before model calls.
Also be cautious with video. Novita AI lists video as an input modality for GLM 4.6V, but production video workflows depend on file access, duration, size, latency, and request formatting. Validate your exact video path before making it a core user-facing feature.
How GLM 4.6V Fits Your API Workflow
GLM 4.6V fits best as a multimodal reasoning layer behind a controlled application interface. A typical architecture keeps API keys in a backend service, accepts user text and approved visual inputs, calls the Novita AI API with zai-org/glm-4.6v, validates the response, and then routes the result into the product experience.
For text-first smoke tests, the OpenAI-compatible chat completions API is the main path. For vision workflows, the application should add visual input only after authentication, routing, logging, and timeout behavior are already working. For tool or JSON workflows, the model output should pass through deterministic validation before any downstream action.
Teams already using OpenAI-compatible clients can often reuse the same client pattern with the Novita AI base URL. Teams building new integrations should start from the Novita AI LLM API guide and the chat completions API reference.
Conclusion
GLM 4.6V on Novita AI makes the most sense when your application needs vision-language understanding through a serverless API, especially for screenshot triage, document-image reasoning, chart interpretation, visual QA, or multimodal agent workflows. The verified Novita AI listing provides enough model, pricing, limit, and endpoint information to justify a structured evaluation.
Choose another model if the workload is text-only, extremely latency-sensitive, or dominated by low-cost high-volume requests where visual input does not materially change the answer. In those cases, compare GLM 4.6V with text-focused options and route only visual tasks to the multimodal model.
The next practical step is to try GLM 4.6V on a small workload-specific test set, using the model ID zai-org/glm-4.6v, current Novita AI pricing, and the API reference for exact request syntax.
FAQ
What is GLM 4.6V?
GLM 4.6V is a multimodal GLM model variant for vision-language tasks. On Novita AI, it is listed as a serverless model with text, image, and video inputs and text output.
Is GLM 4.6V available on Novita AI?
Yes. As of June 24, 2026, Novita AI lists GLM 4.6V on its model page with serverless API access and the model ID zai-org/glm-4.6v.
What is the model ID for GLM 4.6V on Novita AI?
Use zai-org/glm-4.6v as the API model ID in Novita AI requests and model gateway configuration.
How much does GLM 4.6V cost on Novita AI?
As of June 24, 2026, Novita AI lists GLM 4.6V at $0.30 per 1M input tokens, $0.055 per 1M cache-read input tokens, and $0.90 per 1M output tokens.
What is GLM 4.6V best used for?
GLM 4.6V is best used for API workflows where visual input matters, including screenshot triage, document-image interpretation, chart analysis, visual QA, and multimodal agent workflows that need text output from image or video context.
Does GLM 4.6V support function calling?
Yes. The current Novita AI model page lists function calling support for GLM 4.6V. Validate tool arguments and permissions in your application before taking any action based on model output.



