

GLM 4.6V 在 Novita AI 上以无服务器多模态模型的形式提供,适用于需要通过托管 API 实现原生工具调用的视觉 AI 团队。截至 2026 年 6 月 24 日,Novita AI 列出了模型 ID zai-org/glm-4.6v、兼容 OpenAI 的 API 访问、131,072 令牌的上下文窗口、32,768 最大输出令牌、函数调用、结构化输出、推理支持,以及每百万输入令牌 $0.30、每百万缓存读取输入令牌 $0.055、每百万输出令牌 $0.90 的定价。
核心要点
- GLM 4.6V 是一个具备视觉能力的模型,适用于构建截图分析、文档图像理解、视觉问答、多模态支持和智能体工作流的团队。
- Novita AI 将 GLM 4.6V 列为无服务器模型,支持文本、图像和视频输入,文本输出,兼容 OpenAI 的聊天补全访问,以及兼容 Anthropic 的 API。
- 当前的 Novita AI 模型和定价页面列出
zai-org/glm-4.6v拥有 131,072 令牌的上下文窗口、32,768 最大输出令牌,以及按输入、缓存读取输入和输出令牌细分的逐令牌定价。 - 本文是一个模型发布和信息页面。用它来判断 GLM 4.6V 是否适合你的工作负载;在实现生产环境时,使用 Novita API 参考获取精确的请求语法。
什么是 GLM 4.6V?
GLM 4.6V 是一个专为视觉-语言任务构建的多模态 GLM 模型变体。从实际开发者的角度来看,当提示需要将自然语言指令与视觉证据(例如截图、文档页面、图表、仪表盘、表单或视频衍生上下文)结合时,它非常有用。
与纯文本聊天模型不同,GLM 4.6V 专门设计用于视觉输入会改变答案的场景。支持工作流可能需要检查客户截图后才能提出修复建议。产品团队可能希望模型将 UI 截图与预期行为进行比较。文档自动化流程可能需要推理布局、表格和可见标签,而这些在纯 OCR 提取后往往难以保留。
在 Novita AI 上,GLM 4.6V 被定位为一个无服务器 API 选项。这为团队提供了一种直接的方式来评估和集成模型,无需管理 GPU 基础设施、模型服务、扩展或推理运行时设置。实际路径是从 Novita AI 模型页面和 API 文档开始,然后通过兼容 OpenAI 的 API 接口进行连接。
在 Novita AI 上访问 GLM 4.6V API
Novita AI 在其模型库中列出了 GLM 4.6V,API 模型 ID 为 zai-org/glm-4.6v。对于已经使用兼容 OpenAI 的聊天补全的团队,主要的集成信息是 Novita AI API 密钥、Novita AI 基础 URL 和 GLM 4.6V 模型 ID。
当前的 GLM 4.6V 模型页面 标识了模型特定的可用性、模态、限制、功能标志和定价。Novita 聊天补全 API 参考 记录了 API 调用的聊天补全端点和响应格式。
在高层面上,GLM 4.6V API 集成的使用方式如下:
| API 项目 | 当前值 |
|---|---|
| API 模型 ID | zai-org/glm-4.6v |
| 兼容 OpenAI 的基础 URL | https://api.novita.ai/openai |
| 聊天补全 REST 路径 | https://api.novita.ai/openai/v1/chat/completions |
| 典型输出 | 聊天补全格式的文本响应 |
| 认证 | 作为 Bearer 令牌传递的 Novita AI API 密钥 |
本文聚焦于开发者通常首先需要的发布级事实:可用性、API 访问、定价、限制和适用性。对于精确的请求字段、流式行为、工具语法和结构化输出参数,请在交付生产代码前使用当前的 API 参考。
GLM 4.6V 规格与定价摘要
下表总结了在决定是否在 Novita AI 上评估该模型时最重要的 GLM 4.6V 事实。
| 字段 | 详情 |
|---|---|
| 显示名称 | GLM 4.6V |
| API 模型 ID | zai-org/glm-4.6v |
| 访问路径 | 无服务器 API |
| 基础 URL | https://api.novita.ai/openai |
| 聊天补全端点 | https://api.novita.ai/openai/v1/chat/completions |
| 输入模态 | 文本、图像、视频 |
| 输出模态 | 文本 |
| 上下文窗口 | 131,072 令牌 |
| 最大输出令牌 | 32,768 令牌 |
| 功能标志 | 函数调用、结构化输出、推理 |
| 定价 | 每百万输入令牌 $0.30;每百万缓存读取输入令牌 $0.055;每百万输出令牌 $0.90 |
| 最佳适用场景 | 需要从视觉证据中获取文本答案的视觉-语言 API 工作流 |
定价可能会变化,因此在进行生产部署或面对客户的成本承诺前,请确认当前的 Novita AI 定价页面。列出的费率可用于初步预算,但实际花费仍取决于提示长度、图像或视频使用量、生成输出的长度、重试、缓存行为以及应用程序处理长上下文的方式。
GLM 4.6V 基准测试与性能信号
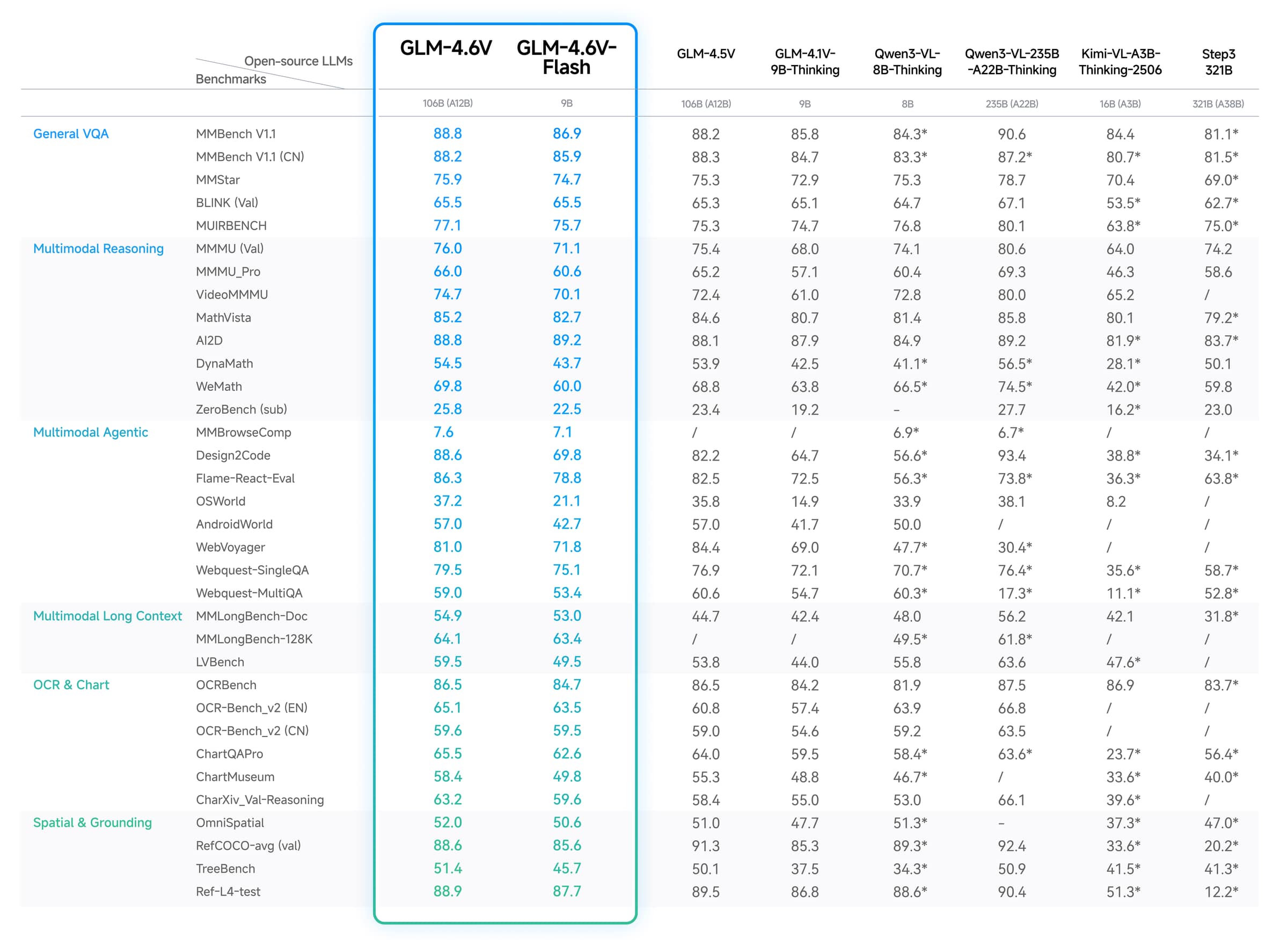
该图表来自 Z.ai 发布的官方 GLM-4.6V 模型材料,并在公开的 GLM-V 仓库中进行了镜像。主要结论是其广度:GLM-4.6V 被定位为一个通用视觉-语言模型,适用于 OCR、图表阅读、空间推理、文档理解和智能体式多模态任务。
但该图表只是一个起点。它并不能说明 GLM-4.6V 将如何遵循你的 schema,或者它将如何在你确切的截图和文档组合上表现。在部署前,请检查:
- 来自实际工作流的代表性截图和文档页面,
- 必须通过你的解析器的结构化输出或工具调用场景,
- 在典型上下文大小下的延迟和成本。
使用官方图表作为证据,表明 GLM-4.6V 具有广泛的多模态目标,然后根据你自己的准确性、延迟和成本测试做出最终决定。
开发者的关键能力
用于截图和文档工作流的视觉输入
当你的应用程序需要对视觉输入而不是仅文本进行推理时,GLM 4.6V 非常有用。产品团队可以总结 UI 截图。支持团队可以对视觉错误报告进行分类。文档工作流可以保留布局提示,这些提示通常在页面过早转换为纯文本时丢失。
这并不消除验证的必要性。对于高风险的文档、私人客户截图或受监管数据,请确保工作流在将视觉输入发送到外部 API 之前符合你的隐私和数据处理要求。
用于丰富多模态提示的长上下文
131,072 令牌的上下文窗口为团队提供了将指令、对话历史、检索到的文本、文档摘录和视觉参考结合起来空间。这适用于答案依赖于多个上下文片段而不仅仅是单个孤立图像的任务。
但仍应将长上下文视为预算和延迟资源。不要默认发送无限制的对话历史或所有可用文件。根据任务修剪、总结和路由上下文。
函数调用与结构化输出
Novita AI 列出了 GLM 4.6V 具有函数调用和结构化输出支持。这使得该模型适用于智能体式应用程序,其中视觉理解需要连接到受控的应用程序逻辑,例如创建支持工单、选择检索工具或返回 JSON 分类对象。
应用程序应保持权威性。它仍然需要验证工具参数、检查权限、强制 schema 规则,并在采取影响用户数据、计费或外部系统的操作前要求确认。
何时使用 GLM 4.6V
视觉支持分类
当用户提交截图以及文本描述时,使用 GLM 4.6V。该模型可以帮助总结可见的 UI 状态,提取可能的问题类别,并为人工审核人或下游工作流生成简洁的笔记。
文档和图表解释
当视觉布局很重要时,使用 GLM 4.6V。示例包括扫描表单、报告截图、包含大量表格的图像、仪表盘图表以及答案依赖于可见结构的设计工件。
多模态智能体工作流
当智能体需要检查视觉状态然后选择结构化的下一步时,使用 GLM 4.6V。视觉 QA 智能体、浏览器式工作流或运营助手可能受益于将视觉上下文与函数调用和结构化输出结合起来。
何时不使用 GLM 4.6V
不要仅仅因为它多模态就选择 GLM 4.6V。如果你的路线是纯文本、短文本、对延迟敏感且高容量,那么专注于文本的模型可能是更好的默认选择。在 Novita AI 模型库 中比较模型,并在你自己的提示上评估成本、延迟和输出质量。
避免发送敏感图像或文档,直到工作流具有明确的隐私、保留和访问控制规则。如果它处理机密客户记录、医疗信息、财务文件或截图中可见的内部凭证,请在模型调用之前添加编辑和策略检查。
对于视频也要谨慎。Novita AI 列出了 GLM 4.6V 的视频输入模态,但生产视频工作流取决于文件访问、时长、大小、延迟和请求格式。在将其作为面向用户的核心功能之前,请验证你的确切视频路径。
GLM 4.6V 如何融入你的 API 工作流
GLM 4.6V 最适合作为受控应用程序接口背后的多模态推理层。典型的架构将 API 密钥保留在后端服务中,接受用户文本和经批准的视觉输入,使用 zai-org/glm-4.6v 调用 Novita AI API,验证响应,然后将结果路由到产品体验中。
对于纯文本的冒烟测试,兼容 OpenAI 的聊天补全 API 是主要路径。对于视觉工作流,应用程序应仅在认证、路由、日志记录和超时行为正常工作后才添加视觉输入。对于工具或 JSON 工作流,模型输出应在任何下游操作前通过确定性验证。
已经使用兼容 OpenAI 的客户端的团队通常可以重用相同的客户端模式,使用 Novita AI 基础 URL。正在构建新集成的团队应从 Novita AI LLM API 指南 和聊天补全 API 参考开始。
结论
当你的应用程序需要通过无服务器 API 实现视觉-语言理解,特别是用于截图分类、文档图像推理、图表解释、视觉问答或多模态智能体工作流时,Novita AI 上的 GLM 4.6V 是最合适的。经过验证的 Novita AI 列表提供了足够的模型、定价、限制和端点信息,以证明结构化评估的合理性。
如果工作负载是纯文本、对延迟极其敏感、或者由低成本高容量请求主导且视觉输入不会实质性地改变答案,请选择其他模型。在这些情况下,将 GLM 4.6V 与专注于文本的选项进行比较,并仅将视觉任务路由到多模态模型。
下一步是使用模型 ID zai-org/glm-4.6v、当前的 Novita AI 定价以及 API 参考中的精确请求语法,在一个小的、特定工作负载的测试集上尝试 GLM 4.6V。
常见问题
什么是 GLM 4.6V?
GLM 4.6V 是一个用于视觉-语言任务的多模态 GLM 模型变体。在 Novita AI 上,它被列为无服务器模型,支持文本、图像和视频输入以及文本输出。
GLM 4.6V 在 Novita AI 上可用吗?
是的。截至 2026 年 6 月 24 日,Novita AI 在其模型页面上列出了 GLM 4.6V,提供无服务器 API 访问,模型 ID 为 zai-org/glm-4.6v。
Novita AI 上 GLM 4.6V 的模型 ID 是什么?
在 Novita AI 请求和模型网关配置中使用 zai-org/glm-4.6v 作为 API 模型 ID。
GLM 4.6V 在 Novita AI 上的费用是多少?
截至 2026 年 6 月 24 日,Novita AI 列出了 GLM 4.6V 的价格为:每百万输入令牌 $0.30,每百万缓存读取输入令牌 $0.055,每百万输出令牌 $0.90。
GLM 4.6V 最适合用于什么?
GLM 4.6V 最适合用于视觉输入重要的 API 工作流,包括截图分类、文档图像解释、图表分析、视觉问答以及需要从图像或视频上下文中获取文本输出的多模态智能体工作流。
GLM 4.6V 支持函数调用吗?
是的。当前的 Novita AI 模型页面列出了 GLM 4.6V 的函数调用支持。在基于模型输出采取任何操作之前,请在应用程序中验证工具参数和权限。



