

- Principais Conclusões
- O que é o GLM 4.6V?
- Acesso à API GLM 4.6V na Novita AI
- Especificações e Resumo de Preços do GLM 4.6V
- Benchmark e Sinais de Desempenho do GLM 4.6V
- Principais Capacidades para Desenvolvedores
- Quando Usar o GLM 4.6V
- Quando Não Usar o GLM 4.6V
- Como o GLM 4.6V se Encaixa no Seu Fluxo de API
- Conclusão
- FAQ
- Artigos Recomendados
O GLM 4.6V está disponível na Novita AI como um modelo multimodal serverless para equipes que precisam de IA de visão com chamada nativa de ferramentas por meio de uma API hospedada. Em 24 de junho de 2026, a Novita AI lista o ID do modelo como zai-org/glm-4.6v, acesso à API compatível com OpenAI, uma janela de contexto de 131.072 tokens, máximo de 32.768 tokens de saída, chamada de funções, saídas estruturadas, suporte a raciocínio e preços de US$ 0,30 por 1M de tokens de entrada, US$ 0,055 por 1M de tokens de entrada lidos em cache e US$ 0,90 por 1M de tokens de saída.
Principais Conclusões
- O GLM 4.6V é um modelo com capacidade de visão na Novita AI para equipes que trabalham com análise de capturas de tela, compreensão de documentos e imagens, QA visual, suporte multimodal e fluxos de agente.
- A Novita AI lista o GLM 4.6V como um modelo serverless com suporte a entrada de texto, imagem e vídeo, saída de texto, acesso a chat completions compatível com OpenAI e suporte a API compatível com Anthropic.
- As páginas atuais de modelo e preços da Novita AI listam
zai-org/glm-4.6vcom janela de contexto de 131.072 tokens, máximo de 32.768 tokens de saída e preços por token divididos entre entrada, entrada lida em cache e saída. - Este artigo é uma página de lançamento e informações do modelo. Use-o para decidir se o GLM 4.6V se adequa à sua carga de trabalho; use a referência da API Novita quando precisar da sintaxe exata da requisição para implementação em produção.
O que é o GLM 4.6V?
O GLM 4.6V é uma variante do modelo GLM multimodal, construída para tarefas de visão e linguagem. Em termos práticos para desenvolvedores, ele é útil quando o prompt precisa combinar instruções em linguagem natural com evidências visuais, como capturas de tela, páginas de documentos, gráficos, painéis, formulários ou contexto derivado de vídeo.
Diferente de um modelo de chat apenas textual, o GLM 4.6V foi projetado para casos onde a entrada visual altera a resposta. Um fluxo de suporte pode precisar inspecionar uma captura de tela do cliente antes de sugerir uma correção. Uma equipe de produto pode querer que um modelo compare uma captura de tela da interface com o comportamento esperado. Uma rota de automação de documentos pode precisar raciocinar sobre layout, tabelas e rótulos visíveis que são difíceis de preservar após extração simples de OCR.
Na Novita AI, o GLM 4.6V é posicionado como uma opção de API serverless. Isso oferece às equipes uma maneira direta de avaliar e integrar o modelo sem gerenciar infraestrutura de GPU, servindo o modelo, escalonamento ou configuração de runtime de inferência. O caminho prático é começar pela página do modelo e documentação da API Novita AI e depois conectar-se por meio da superfície da API compatível com OpenAI.
Acesso à API GLM 4.6V na Novita AI
A Novita AI lista o GLM 4.6V na biblioteca de modelos com o ID de modelo de API zai-org/glm-4.6v. Para equipes que já usam chat completions compatível com OpenAI, os principais detalhes de integração são a chave de API da Novita AI, a URL base da Novita AI e o ID do modelo GLM 4.6V.
A página atual do modelo GLM 4.6V identifica a disponibilidade específica do modelo, modalidades, limites, flags de recurso e preços. A referência da API de chat completions da Novita documenta o endpoint e a forma da resposta para chamadas de API de chat completions.
Em alto nível, uma integração com a API GLM 4.6V usa:
| Item da API | Valor atual |
|---|---|
| ID do modelo de API | zai-org/glm-4.6v |
| URL base compatível com OpenAI | https://api.novita.ai/openai |
| Caminho REST de chat completions | https://api.novita.ai/openai/v1/chat/completions |
| Saída típica | Resposta em texto no formato chat completions |
| Autenticação | Chave de API Novita AI passada como token Bearer |
Esta página foca nos fatos de lançamento que desenvolvedores geralmente precisam primeiro: disponibilidade, acesso à API, preços, limites e adequação. Para campos exatos de requisição, comportamento de streaming, sintaxe de ferramentas e parâmetros de saída estruturada, use a referência atual da API antes de enviar código de produção.
Especificações e Resumo de Preços do GLM 4.6V
A tabela a seguir resume os fatos do GLM 4.6V que mais importam ao decidir se deve avaliar o modelo na Novita AI.
| Campo | Detalhes |
|---|---|
| Nome de exibição | GLM 4.6V |
| ID do modelo de API | zai-org/glm-4.6v |
| Caminho de acesso | API Serverless |
| URL base | https://api.novita.ai/openai |
| Endpoint de chat completions | https://api.novita.ai/openai/v1/chat/completions |
| Modalidades de entrada | Texto, imagem, vídeo |
| Modalidade de saída | Texto |
| Janela de contexto | 131.072 tokens |
| Máximo de tokens de saída | 32.768 tokens |
| Flags de recurso | Chamada de funções, saídas estruturadas, raciocínio |
| Preços | US$ 0,30 por 1M de tokens de entrada; US$ 0,055 por 1M de tokens de entrada lidos em cache; US$ 0,90 por 1M de tokens de saída |
| Melhor adequação | Fluxos de trabalho de API de visão-linguagem que precisam de respostas em texto a partir de evidências visuais |
Os preços podem mudar, então confirme a página de preços atual da Novita AI antes de lançar em produção ou assumir compromissos de custo voltados ao cliente. As taxas listadas são úteis para orçamento inicial, mas o gasto real ainda depende do tamanho do prompt, uso de imagem ou vídeo, comprimento da saída gerada, tentativas repetidas, comportamento do cache e da forma como sua aplicação lida com contexto longo.
Benchmark e Sinais de Desempenho do GLM 4.6V
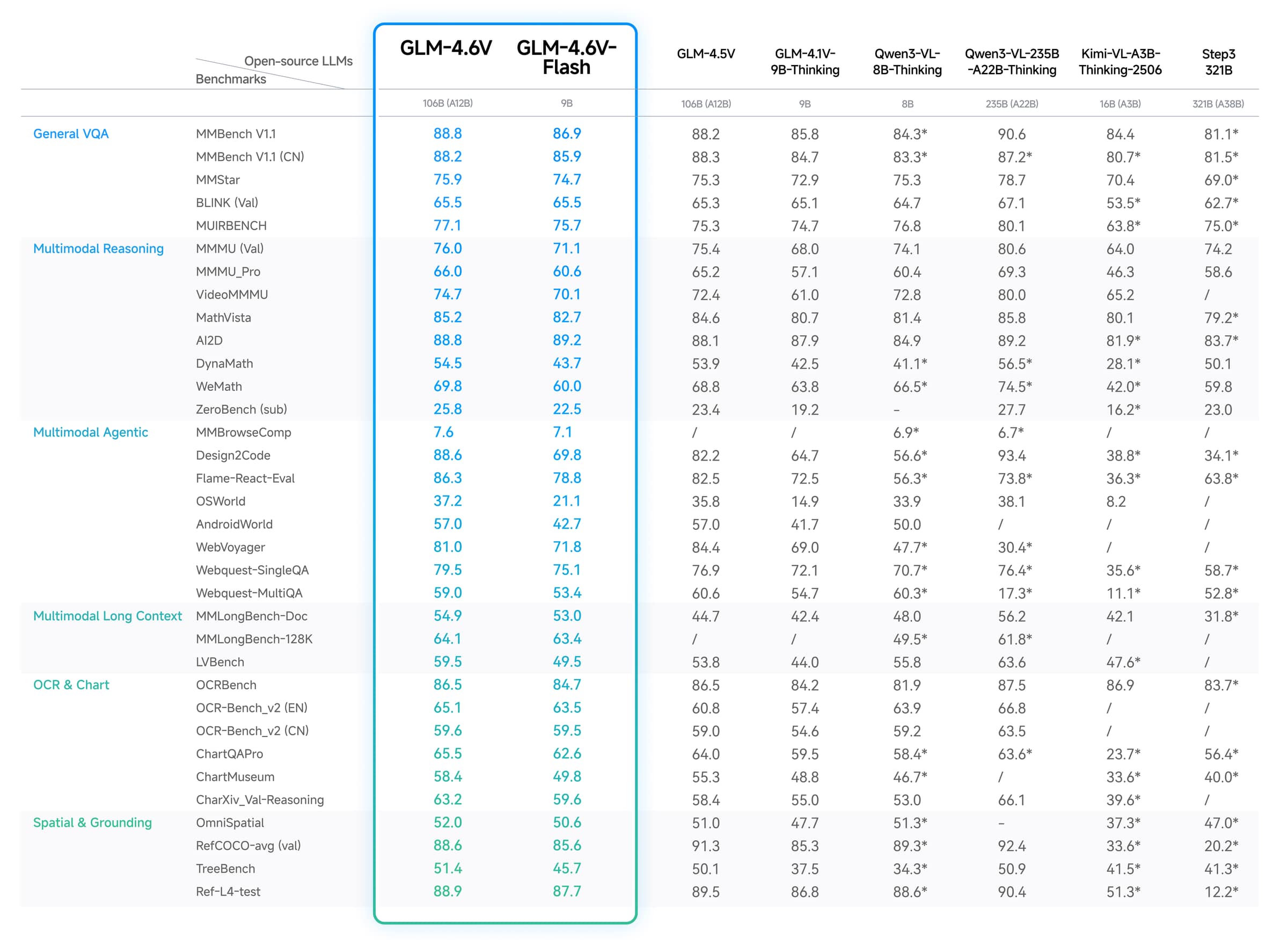
Este gráfico vem dos materiais oficiais do modelo GLM-4.6V publicados pela Z.ai e espelhados no repositório público GLM-V. A principal conclusão é a amplitude: o GLM-4.6V está sendo posicionado como um modelo de visão-linguagem de uso geral em OCR, leitura de gráficos, raciocínio espacial, compreensão de documentos e tarefas multimodais de agente.
O gráfico ainda é apenas um ponto de partida. Ele não informa o quão bem o GLM-4.6V seguirá seu esquema nem como se comportará em sua mistura exata de capturas de tela e documentos. Antes do lançamento, verifique:
- capturas de tela e páginas de documentos representativos do seu fluxo de trabalho real;
- casos de saída estruturada ou chamada de ferramentas que devem passar pelo seu analisador;
- latência e custo no tamanho de contexto típico da sua aplicação.
Use o gráfico oficial como evidência de que o GLM-4.6V tem ambições multimodais amplas e depois tome a decisão final com base em seus próprios testes de precisão, latência e custo.
Principais Capacidades para Desenvolvedores
Entrada de Visão para Fluxos de Captura de Tela e Documentos
O GLM 4.6V é útil quando sua aplicação precisa raciocinar sobre a entrada visual em vez de apenas texto. Equipes de produto podem resumir capturas de tela de interface. Equipes de suporte podem classificar relatórios visuais de bugs. Fluxos de documentos podem preservar dicas de layout que geralmente são perdidas quando uma página é convertida em texto simples muito cedo.
Isso não elimina a necessidade de validação. Para documentos de alto risco, capturas de tela privadas de clientes ou dados regulamentados, certifique-se de que o fluxo de trabalho atenda aos seus requisitos de privacidade e tratamento de dados antes de enviar entrada visual a uma API externa.
Contexto Longo para Prompts Multimodais Ricos
A janela de contexto de 131.072 tokens dá às equipes espaço para combinar instruções, histórico de conversa, texto recuperado, trechos de documentos e referências visuais. Isso é valioso para tarefas onde a resposta depende de várias partes de contexto, não de uma única imagem isolada.
Contexto longo ainda deve ser tratado como um recurso de orçamento e latência. Não envie histórico de conversa ilimitado ou todos os arquivos disponíveis por padrão. Apare, resuma e direcione o contexto com base na tarefa.
Chamada de Funções e Saídas Estruturadas
A Novita AI lista o GLM 4.6V com suporte a chamada de funções e saídas estruturadas. Isso torna o modelo relevante para aplicações no estilo agente, onde a compreensão visual precisa se conectar à lógica controlada da aplicação, como criar um ticket de suporte, selecionar uma ferramenta de recuperação ou retornar um objeto de classificação JSON.
A aplicação deve permanecer a autoridade. Ela ainda precisa validar argumentos de ferramentas, verificar permissões, aplicar regras de esquema e exigir confirmação antes de tomar ações que afetam dados do usuário, cobrança ou sistemas externos.
Quando Usar o GLM 4.6V
Triagem Visual de Suporte
Use o GLM 4.6V quando os usuários enviarem capturas de tela junto com descrições em texto. O modelo pode ajudar a resumir o estado visual da interface, extrair categorias prováveis de problemas e produzir notas concisas para um revisor humano ou fluxo de trabalho subsequente.
Interpretação de Documentos e Gráficos
Use o GLM 4.6V quando o layout visual importa. Exemplos incluem formulários escaneados, capturas de tela de relatórios, imagens com muitas tabelas, gráficos de painéis e artefatos de design onde a resposta depende da estrutura visível.
Fluxos de Agente Multimodal
Use o GLM 4.6V quando um agente precisar inspecionar o estado visual e então escolher um próximo passo estruturado. Um agente de QA visual, um fluxo de trabalho no estilo navegador ou um assistente de operações podem se beneficiar da combinação de contexto visual com chamada de funções e saídas estruturadas.
Quando Não Usar o GLM 4.6V
Não escolha o GLM 4.6V apenas por ser multimodal. Se sua rota for apenas texto, curta, sensível a latência e de alto volume, um modelo focado em texto pode ser uma escolha melhor. Compare modelos na biblioteca de modelos da Novita AI e avalie custo, latência e qualidade de saída em seus próprios prompts.
Evite enviar imagens ou documentos sensíveis até que o fluxo de trabalho tenha regras claras de privacidade, retenção e controle de acesso. Se ele lida com registros confidenciais de clientes, informações médicas, documentos financeiros ou credenciais internas visíveis em capturas de tela, adicione verificação de redação e políticas antes das chamadas ao modelo.
Tenha cuidado também com vídeo. A Novita AI lista vídeo como uma modalidade de entrada para o GLM 4.6V, mas fluxos de produção com vídeo dependem de acesso a arquivos, duração, tamanho, latência e formatação da requisição. Valide seu caminho exato de vídeo antes de torná-lo um recurso central voltado ao usuário.
Como o GLM 4.6V se Encaixa no Seu Fluxo de API
O GLM 4.6V se encaixa melhor como uma camada de raciocínio multimodal por trás de uma interface de aplicação controlada. Uma arquitetura típica mantém chaves de API em um serviço de backend, aceita texto do usuário e entradas visuais aprovadas, chama a API Novita AI com zai-org/glm-4.6v, valida a resposta e então direciona o resultado para a experiência do produto.
Para testes de fumaça com texto primeiro, a API de chat completions compatível com OpenAI é o caminho principal. Para fluxos de visão, a aplicação deve adicionar entrada visual somente após autenticação, roteamento, registro e comportamento de timeout já estarem funcionando. Para fluxos de ferramentas ou JSON, a saída do modelo deve passar por validação determinística antes de qualquer ação subsequente.
Equipes que já usam clientes compatíveis com OpenAI geralmente podem reutilizar o mesmo padrão de cliente com a URL base da Novita AI. Equipes construindo novas integrações devem começar pelo guia da API LLM Novita AI e pela referência da API de chat completions.
Conclusão
O GLM 4.6V na Novita AI faz mais sentido quando sua aplicação precisa de compreensão de visão-linguagem por meio de uma API serverless, especialmente para triagem de capturas de tela, raciocínio sobre documentos e imagens, interpretação de gráficos, QA visual ou fluxos de agente multimodal. A listagem verificada da Novita AI fornece informações suficientes sobre modelo, preços, limites e endpoint para justificar uma avaliação estruturada.
Escolha outro modelo se a carga de trabalho for apenas texto, extremamente sensível a latência ou dominada por requisições de baixo custo e alto volume onde a entrada visual não altera materialmente a resposta. Nesses casos, compare o GLM 4.6V com opções focadas em texto e direcione apenas tarefas visuais para o modelo multimodal.
O próximo passo prático é testar o GLM 4.6V em um pequeno conjunto de testes específico da carga de trabalho, usando o ID do modelo zai-org/glm-4.6v, os preços atuais da Novita AI e a referência da API para sintaxe exata da requisição.
FAQ
O que é o GLM 4.6V?
O GLM 4.6V é uma variante do modelo GLM multimodal para tarefas de visão-linguagem. Na Novita AI, ele é listado como um modelo serverless com entradas de texto, imagem e vídeo e saída de texto.
O GLM 4.6V está disponível na Novita AI?
Sim. Em 24 de junho de 2026, a Novita AI lista o GLM 4.6V em sua página de modelo com acesso API serverless e o ID do modelo zai-org/glm-4.6v.
Qual é o ID do modelo para o GLM 4.6V na Novita AI?
Use zai-org/glm-4.6v como o ID do modelo de API nas requisições e na configuração do gateway de modelo da Novita AI.
Quanto custa o GLM 4.6V na Novita AI?
Em 24 de junho de 2026, a Novita AI lista o GLM 4.6V a US$ 0,30 por 1M de tokens de entrada, US$ 0,055 por 1M de tokens de entrada lidos em cache e US$ 0,90 por 1M de tokens de saída.
Para que o GLM 4.6V é mais recomendado?
O GLM 4.6V é mais recomendado para fluxos de API onde a entrada visual importa, incluindo triagem de capturas de tela, interpretação de documentos e imagens, análise de gráficos, QA visual e fluxos de agente multimodal que precisam de saída de texto a partir de contexto de imagem ou vídeo.
O GLM 4.6V suporta chamada de funções?
Sim. A página atual do modelo Novita AI lista suporte a chamada de funções para o GLM 4.6V. Valide argumentos de ferramentas e permissões em sua aplicação antes de tomar qualquer ação com base na saída do modelo.



