

- Principaux enseignements
- Qu'est-ce que GLM 4.6V ?
- Accès à l'API GLM 4.6V sur Novita AI
- Récapitulatif des spécifications et tarifs de GLM 4.6V
- Benchmark et signaux de performance de GLM 4.6V
- Principales capacités pour les développeurs
- Quand utiliser GLM 4.6V
- Quand ne pas utiliser GLM 4.6V
- Comment GLM 4.6V s'intègre dans votre workflow API
- Conclusion
- FAQ
- Articles recommandés
GLM 4.6V est disponible sur Novita AI en tant que modèle multimodal serverless pour les équipes qui ont besoin d’une IA visuelle avec appel natif d’outils via une API hébergée. Depuis le 24 juin 2026, Novita AI répertorie l’ID du modèle comme zai-org/glm-4.6v, un accès API compatible OpenAI, une fenêtre de contexte de 131 072 tokens, un maximum de 32 768 tokens de sortie, l’appel de fonctions, les sorties structurées, le support du raisonnement, et un tarif de 0,30 $ par 1M de tokens d’entrée, 0,055 $ par 1M de tokens d’entrée lus depuis le cache, et 0,90 $ par 1M de tokens de sortie.
Principaux enseignements
- GLM 4.6V est un modèle capable de vision sur Novita AI pour les équipes développant l’analyse de captures d’écran, la compréhension de documents-images, le QA visuel, le support multimodal et les workflows d’agents.
- Novita AI répertorie GLM 4.6V comme un modèle serverless prenant en charge les entrées texte, image et vidéo, la sortie texte, l’accès aux complétions de chat compatible OpenAI et le support d’API compatible Anthropic.
- Les pages actuelles du modèle et des tarifs de Novita AI répertorient
zai-org/glm-4.6vavec une fenêtre de contexte de 131 072 tokens, un maximum de 32 768 tokens de sortie, et un tarif par token réparti entre les tokens d’entrée, les tokens d’entrée lus depuis le cache et les tokens de sortie. - Cet article est une page de lancement et d’information sur le modèle. Utilisez-le pour décider si GLM 4.6V correspond à votre charge de travail ; utilisez la référence de l’API Novita lorsque vous avez besoin de la syntaxe exacte des requêtes pour une implémentation en production.
Qu’est-ce que GLM 4.6V ?
GLM 4.6V est une variante de modèle GLM multimodal conçue pour les tâches de vision-langage. En termes pratiques pour les développeurs, il est utile lorsque l’invite doit combiner des instructions en langage naturel avec des preuves visuelles telles que des captures d’écran, des pages de documents, des graphiques, des tableaux de bord, des formulaires ou un contexte dérivé de vidéos.
Contrairement à un modèle de chat textuel uniquement, GLM 4.6V est conçu pour les cas où l’entrée visuelle modifie la réponse. Un workflow de support peut avoir besoin d’inspecter une capture d’écran client avant de suggérer une solution. Une équipe produit peut vouloir qu’un modèle compare une capture d’écran d’interface utilisateur avec le comportement attendu. Un chemin d’automatisation de documents peut avoir besoin de raisonner sur la mise en page, les tableaux et les étiquettes visibles qui sont difficiles à préserver après une simple extraction OCR.
Sur Novita AI, GLM 4.6V est positionné comme une option d’API serverless. Cela donne aux équipes un moyen simple d’évaluer et d’intégrer le modèle sans gérer l’infrastructure GPU, le service de modèle, la mise à l’échelle ou la configuration de l’environnement d’inférence. La voie pratique consiste à partir de la page du modèle et de la documentation de l’API Novita AI, puis à se connecter via la surface d’API compatible OpenAI.
Accès à l’API GLM 4.6V sur Novita AI
Novita AI répertorie GLM 4.6V dans la bibliothèque de modèles avec l’ID de modèle API zai-org/glm-4.6v. Pour les équipes utilisant déjà les complétions de chat compatibles OpenAI, les principaux détails d’intégration sont la clé API Novita AI, l’URL de base Novita AI et l’ID du modèle GLM 4.6V.
La page du modèle GLM 4.6V actuelle identifie la disponibilité, les modalités, les limites, les indicateurs de fonctionnalités et les tarifs spécifiques au modèle. La référence de l’API de complétions de chat Novita documente le point de terminaison et la forme de réponse des complétions de chat pour les appels API.
| Élément API | Valeur actuelle |
|---|---|
| ID du modèle API | zai-org/glm-4.6v |
| URL de base compatible OpenAI | https://api.novita.ai/openai |
| Chemin REST des complétions de chat | https://api.novita.ai/openai/v1/chat/completions |
| Sortie typique | Réponse textuelle au format des complétions de chat |
| Authentification | Clé API Novita AI transmise comme jeton porteur |
Cette page se concentre sur les faits de lancement dont les développeurs ont généralement besoin en premier : disponibilité, accès API, tarifs, limites et adéquation. Pour les champs de requête exacts, le comportement de streaming, la syntaxe des outils et les paramètres de sortie structurée, utilisez la référence API actuelle avant de déployer un code de production.
Récapitulatif des spécifications et tarifs de GLM 4.6V
Le tableau suivant résume les faits les plus importants concernant GLM 4.6V pour décider d’évaluer le modèle sur Novita AI.
| Champ | Détails |
|---|---|
| Nom d’affichage | GLM 4.6V |
| ID du modèle API | zai-org/glm-4.6v |
| Chemin d’accès | API Serverless |
| URL de base | https://api.novita.ai/openai |
| Point de terminaison des complétions de chat | https://api.novita.ai/openai/v1/chat/completions |
| Modalités d’entrée | Texte, image, vidéo |
| Modalité de sortie | Texte |
| Fenêtre de contexte | 131 072 tokens |
| Max de tokens de sortie | 32 768 tokens |
| Indicateurs de fonctionnalités | Appel de fonctions, sorties structurées, raisonnement |
| Tarifs | 0,30 $ par 1M de tokens d’entrée ; 0,055 $ par 1M de tokens d’entrée lus depuis le cache ; 0,90 $ par 1M de tokens de sortie |
| Meilleure utilisation | Workflows d’API vision-langage nécessitant des réponses textuelles à partir de preuves visuelles |
Les tarifs peuvent changer, alors confirmez la page des tarifs Novita AI actuelle avant le déploiement en production ou les engagements de coûts envers les clients. Les tarifs listés sont utiles pour l’établissement initial du budget, mais les dépenses réelles dépendent toujours de la longueur des invites, de l’utilisation d’images ou de vidéos, de la longueur des sorties générées, des tentatives, du comportement du cache et de la façon dont votre application gère les longs contextes.
Benchmark et signaux de performance de GLM 4.6V
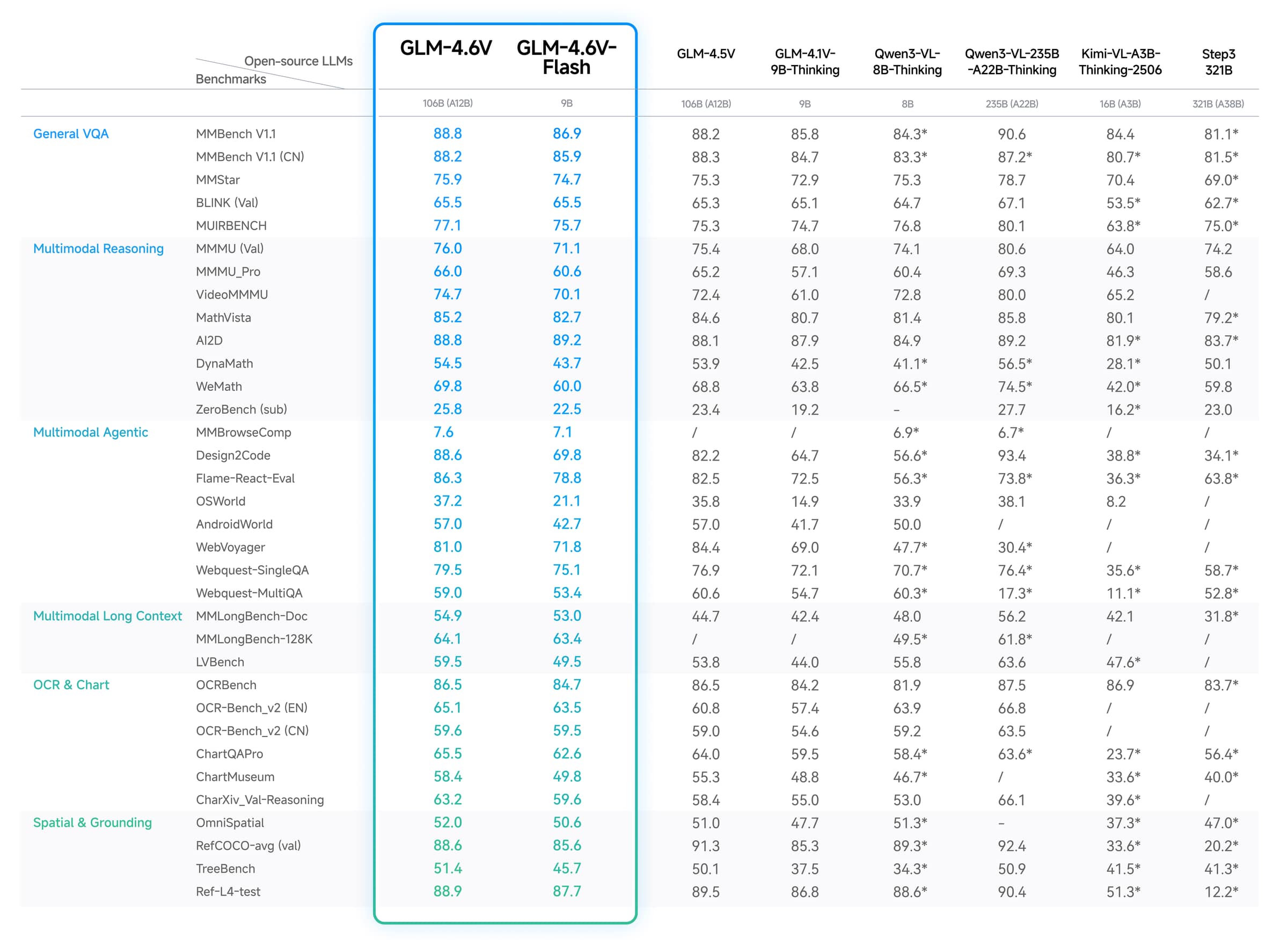
Ce graphique provient des documents officiels du modèle GLM-4.6V publiés par Z.ai et reflétés dans le dépôt public GLM-V. Le principal enseignement est l’étendue : GLM-4.6V est positionné comme un modèle vision-langage à usage général couvrant l’OCR, la lecture de graphiques, le raisonnement spatial, la compréhension de documents et les tâches multimodales de type agent.
Le graphique n’est encore qu’un point de départ. Il ne vous dit pas avec quelle précision GLM-4.6V suivra votre schéma ou comment il se comportera sur votre mélange exact de captures d’écran et de documents. Avant le déploiement, vérifiez :
- des captures d’écran et pages de documents représentatives de votre workflow réel,
- les cas de sortie structurée ou d’appel d’outils qui doivent passer votre analyseur syntaxique,
- la latence et le coût à votre taille de contexte habituelle.
Utilisez le graphique officiel comme preuve que GLM-4.6V a de vastes ambitions multimodales, puis prenez la décision finale sur vos propres tests de précision, latence et coût.
Principales capacités pour les développeurs
Entrée visuelle pour les workflows de captures d’écran et de documents
GLM 4.6V est utile lorsque votre application doit raisonner sur une entrée visuelle plutôt que sur du texte uniquement. Les équipes produit peuvent résumer les captures d’écran d’interface utilisateur. Les équipes de support peuvent classer les rapports de bugs visuels. Les workflows de documents peuvent préserver les indices de mise en page souvent perdus lorsqu’une page est convertie en texte brut trop tôt.
Cela ne supprime pas le besoin de validation. Pour les documents à enjeux élevés, les captures d’écran privées de clients ou les données réglementées, assurez-vous que le workflow correspond à vos exigences de confidentialité et de traitement des données avant d’envoyer une entrée visuelle à une API externe.
Contexte long pour les invites multimodales riches
La fenêtre de contexte de 131 072 tokens donne aux équipes la possibilité de combiner des instructions, l’historique de la conversation, du texte récupéré, des extraits de documents et des références visuelles. C’est précieux pour les tâches où la réponse dépend de plusieurs éléments de contexte, et non d’une seule image isolée.
Le contexte long doit toujours être traité comme une ressource de budget et de latence. N’envoyez pas par défaut un historique de conversation illimité ou tous les fichiers disponibles. Réduisez, résumez et acheminez le contexte en fonction de la tâche.
Appel de fonctions et sorties structurées
Novita AI répertorie GLM 4.6V avec la prise en charge de l’appel de fonctions et des sorties structurées. Cela rend le modèle pertinent pour les applications de type agent où la compréhension visuelle doit se connecter à une logique d’application contrôlée, comme la création d’un ticket de support, la sélection d’un outil de récupération, ou le retour d’un objet de classification JSON.
L’application doit rester l’autorité. Elle doit toujours valider les arguments des outils, vérifier les autorisations, appliquer les règles de schéma et exiger une confirmation avant d’effectuer des actions qui affectent les données utilisateur, la facturation ou les systèmes externes.
Quand utiliser GLM 4.6V
Triage du support visuel
Utilisez GLM 4.6V lorsque les utilisateurs soumettent des captures d’écran accompagnées de descriptions textuelles. Le modèle peut aider à résumer l’état visible de l’interface utilisateur, extraire les catégories de problèmes probables et produire des notes concises pour un réviseur humain ou un workflow en aval.
Interprétation de documents et de graphiques
Utilisez GLM 4.6V lorsque la mise en page visuelle est importante. Les exemples incluent les formulaires scannés, les captures d’écran de rapports, les images riches en tableaux, les graphiques de tableau de bord et les artefacts de conception où la réponse dépend de la structure visible.
Workflows d’agents multimodaux
Utilisez GLM 4.6V lorsqu’un agent doit inspecter un état visuel puis choisir une prochaine étape structurée. Un agent de QA visuel, un workflow de type navigateur ou un assistant opérationnel peut bénéficier de la combinaison d’un contexte visuel avec l’appel de fonctions et les sorties structurées.
Quand ne pas utiliser GLM 4.6V
Ne choisissez pas GLM 4.6V uniquement parce qu’il est multimodal. Si votre chemin est uniquement textuel, court, sensible à la latence et à volume élevé, un modèle axé sur le texte peut être un meilleur choix par défaut. Comparez les modèles dans la bibliothèque de modèles Novita AI et évaluez le coût, la latence et la qualité des sorties sur vos propres invites.
Évitez d’envoyer des images ou documents sensibles tant que le workflow n’a pas de règles claires de confidentialité, de rétention et de contrôle d’accès. S’il traite des dossiers clients confidentiels, des informations médicales, des documents financiers ou des identifiants internes visibles dans les captures d’écran, ajoutez des vérifications de rédaction et de politique avant les appels au modèle.
Soyez également prudent avec la vidéo. Novita AI répertorie la vidéo comme modalité d’entrée pour GLM 4.6V, mais les workflows vidéo en production dépendent de l’accès au fichier, de la durée, de la taille, de la latence et du formatage des requêtes. Validez votre chemin vidéo exact avant d’en faire une fonctionnalité essentielle pour l’utilisateur.
Comment GLM 4.6V s’intègre dans votre workflow API
GLM 4.6V s’intègre le mieux comme couche de raisonnement multimodal derrière une interface applicative contrôlée. Une architecture typique conserve les clés API dans un service backend, accepte le texte utilisateur et les entrées visuelles approuvées, appelle l’API Novita AI avec zai-org/glm-4.6v, valide la réponse, puis achemine le résultat dans l’expérience produit.
Pour les tests de validation textuels, l’API de complétions de chat compatible OpenAI est la voie principale. Pour les workflows de vision, l’application ne doit ajouter une entrée visuelle qu’une fois que l’authentification, le routage, la journalisation et le comportement de timeout fonctionnent déjà. Pour les workflows d’outils ou JSON, la sortie du modèle doit passer par une validation déterministe avant toute action en aval.
Les équipes utilisant déjà des clients compatibles OpenAI peuvent souvent réutiliser le même modèle de client avec l’URL de base Novita AI. Les équipes développant de nouvelles intégrations devraient partir du guide de l’API LLM Novita AI et de la référence de l’API de complétions de chat.
Conclusion
GLM 4.6V sur Novita AI a le plus de sens lorsque votre application a besoin d’une compréhension vision-langage via une API serverless, en particulier pour le triage de captures d’écran, le raisonnement document-image, l’interprétation de graphiques, le QA visuel ou les workflows d’agents multimodaux. La liste vérifiée de Novita AI fournit suffisamment d’informations sur le modèle, les tarifs, les limites et les points de terminaison pour justifier une évaluation structurée.
Choisissez un autre modèle si la charge de travail est uniquement textuelle, extrêmement sensible à la latence ou dominée par des requêtes à faible coût et volume élevé où l’entrée visuelle ne change pas matériellement la réponse. Dans ces cas, comparez GLM 4.6V avec des options axées sur le texte et acheminez uniquement les tâches visuelles vers le modèle multimodal.
La prochaine étape pratique consiste à essayer GLM 4.6V sur un petit ensemble de tests spécifiques à la charge de travail, en utilisant l’ID du modèle zai-org/glm-4.6v, les tarifs actuels de Novita AI et la référence de l’API pour la syntaxe exacte des requêtes.
FAQ
Qu’est-ce que GLM 4.6V ?
GLM 4.6V est une variante de modèle GLM multimodal pour les tâches de vision-langage. Sur Novita AI, il est répertorié comme un modèle serverless avec des entrées texte, image et vidéo et une sortie texte.
GLM 4.6V est-il disponible sur Novita AI ?
Oui. Depuis le 24 juin 2026, Novita AI répertorie GLM 4.6V sur sa page de modèle avec un accès API serverless et l’ID du modèle zai-org/glm-4.6v.
Quel est l’ID du modèle pour GLM 4.6V sur Novita AI ?
Utilisez zai-org/glm-4.6v comme ID du modèle API dans les requêtes Novita AI et la configuration de la passerelle de modèles.
Combien coûte GLM 4.6V sur Novita AI ?
Depuis le 24 juin 2026, Novita AI répertorie GLM 4.6V à 0,30 $ par 1M de tokens d’entrée, 0,055 $ par 1M de tokens d’entrée lus depuis le cache, et 0,90 $ par 1M de tokens de sortie.
À quoi sert le mieux GLM 4.6V ?
GLM 4.6V est le mieux adapté pour les workflows API où l’entrée visuelle est importante, y compris le triage de captures d’écran, l’interprétation de documents-images, l’analyse de graphiques, le QA visuel et les workflows d’agents multimodaux qui nécessitent une sortie textuelle à partir d’un contexte d’image ou de vidéo.
GLM 4.6V prend-il en charge l’appel de fonctions ?
Oui. La page actuelle du modèle Novita AI répertorie la prise en charge de l’appel de fonctions pour GLM 4.6V. Validez les arguments et les autorisations des outils dans votre application avant d’effectuer toute action basée sur la sortie du modèle.



