

- Wesentliche Erkenntnisse
- Was ist GLM 4.6V?
- GLM 4.6V API-Zugriff auf Novita AI
- GLM 4.6V Spezifikationen und Preisübersicht
- GLM 4.6V Benchmark- und Leistungsindikatoren
- Wichtige Fähigkeiten für Entwickler
- Wann sollte GLM 4.6V verwendet werden?
- Wann sollte GLM 4.6V nicht verwendet werden?
- Wie GLM 4.6V in deinen API-Workflow passt
- Fazit
- FAQ
- Empfohlene Artikel
GLM 4.6V ist auf Novita AI als serverloses multimodales Modell für Teams verfügbar, die Vision-KI mit nativem Tool-Calling über eine gehostete API benötigen. Zum Stand vom 24. Juni 2026 listet Novita AI die Modell-ID als zai-org/glm-4.6v, OpenAI-kompatiblen API-Zugriff, ein Kontextfenster von 131.072 Token, 32.768 maximale Ausgabe-Token, Function Calling, strukturierte Ausgaben, Reasoning-Unterstützung und Preise von $0,30 pro 1 Mio. Input-Tokens, $0,055 pro 1 Mio. Cache-Read-Input-Tokens und $0,90 pro 1 Mio. Output-Tokens.
Wesentliche Erkenntnisse
- GLM 4.6V ist ein visionsfähiges Modell auf Novita AI für Teams, die Screenshot-Analysen, Dokument-Bild-Verständnis, visuelle QA, multimodalen Support und Agenten-Workflows entwickeln.
- Novita AI listet GLM 4.6V als serverloses Modell mit Text-, Bild- und Video-Input, Text-Output, OpenAI-kompatiblen Chat-Completions-Zugriff und Anthropic-kompatiblem API-Support.
- Die aktuellen Novita AI Modell- und Preisseiten listen
zai-org/glm-4.6vmit einem Kontextfenster von 131.072 Token, 32.768 maximalen Output-Tokens und einer Aufteilung auf Input-, Cache-Read-Input- und Output-Tokens. - Dieser Artikel ist eine Modellvorstellung und Informationsseite. Nutze ihn, um zu entscheiden, ob GLM 4.6V zu deinem Workload passt; verwende die Novita API-Referenz, wenn du die genaue Request-Syntax für die Produktionsimplementierung benötigst.
Was ist GLM 4.6V?
GLM 4.6V ist eine multimodale GLM-Modellvariante, die für Vision-Language-Aufgaben entwickelt wurde. Für Entwickler bedeutet das praktisch: Es ist nützlich, wenn der Prompt natürliche Sprachinstruktionen mit visuellen Beweisen wie Screenshots, Dokumentseiten, Diagrammen, Dashboards, Formularen oder Video-Kontext kombinieren muss.
Im Gegensatz zu einem reinen Text-Chat-Modell ist GLM 4.6V für Fälle konzipiert, in denen der visuelle Input die Antwort verändert. Ein Support-Workflow muss möglicherweise einen Kundenscreenshot inspizieren, bevor er eine Lösung vorschlägt. Ein Produktteam möchte ein Modell einsetzen, um einen UI-Screenshot mit dem erwarteten Verhalten zu vergleichen. Ein Dokumentenautomatisierungsprozess muss Layout, Tabellen und sichtbare Beschriftungen verarbeiten, die nach einer einfachen OCR-Extraktion schwer zu erhalten sind.
Auf Novita AI wird GLM 4.6V als serverlose API-Option bereitgestellt. Das gibt Teams einen unkomplizierten Weg, das Modell zu evaluieren und zu integrieren, ohne GPU-Infrastruktur, Modellhosting, Skalierung oder Inferenz-Runtime-Setup verwalten zu müssen. Der praktische Weg ist, mit der Novita AI Modellseite und API-Dokumentation zu beginnen und dann über die OpenAI-kompatible API-Oberfläche anzubinden.
GLM 4.6V API-Zugriff auf Novita AI
Novita AI listet GLM 4.6V in der Modellbibliothek mit der API-Modell-ID zai-org/glm-4.6v. Für Teams, die bereits OpenAI-kompatible Chat-Completions verwenden, sind die wichtigsten Integrationsdetails der Novita AI API-Schlüssel, die Novita AI Basis-URL und die GLM 4.6V Modell-ID.
Die aktuelle GLM 4.6V Modellseite gibt Auskunft über modellspezifische Verfügbarkeit, Modalitäten, Limits, Feature-Flags und Preise. Die Novita Chat-Completions-API-Referenz dokumentiert den Chat-Completions-Endpunkt und die Antwortstruktur für API-Aufrufe.
Auf hoher Ebene verwendet eine GLM 4.6V API-Integration:
| API-Element | Aktueller Wert |
|---|---|
| API-Modell-ID | zai-org/glm-4.6v |
| OpenAI-kompatible Basis-URL | https://api.novita.ai/openai |
| REST-Pfad für Chat-Completions | https://api.novita.ai/openai/v1/chat/completions |
| Typische Ausgabe | Textantwort im Chat-Completions-Format |
| Authentifizierung | Novita AI API-Schlüssel als Bearer-Token |
Diese Seite konzentriert sich auf die Launch-Level-Fakten, die Entwickler zuerst benötigen: Verfügbarkeit, API-Zugriff, Preise, Limits und Einsatzbereich. Für die exakten Request-Felder, Streaming-Verhalten, Tool-Syntax und Parameter für strukturierte Ausgaben verwende vor der Produktionsauslieferung die aktuelle API-Referenz.
GLM 4.6V Spezifikationen und Preisübersicht
Die folgende Tabelle fasst die für GLM 4.6V relevanten Fakten zusammen, die bei der Entscheidung, ob das Modell auf Novita AI evaluiert werden soll, am wichtigsten sind.
| Feld | Details |
|---|---|
| Anzeigename | GLM 4.6V |
| API-Modell-ID | zai-org/glm-4.6v |
| Zugriffspfad | Serverlose API |
| Basis-URL | https://api.novita.ai/openai |
| Chat-Completions-Endpunkt | https://api.novita.ai/openai/v1/chat/completions |
| Eingabe-Modalitäten | Text, Bild, Video |
| Ausgabe-Modalität | Text |
| Kontextfenster | 131.072 Token |
| Maximale Ausgabe-Token | 32.768 Token |
| Feature-Flags | Function Calling, strukturierte Ausgaben, Reasoning |
| Preise | $0,30 pro 1 Mio. Input-Tokens; $0,055 pro 1 Mio. Cache-Read-Input-Tokens; $0,90 pro 1 Mio. Output-Tokens |
| Bester Einsatzbereich | Vision-Language-API-Workflows, die Textantworten aus visuellen Belegen benötigen |
Die Preise können sich ändern. Bestätige daher die aktuelle Novita AI Preisseite vor der Produktionsauslieferung oder kundenorientierten Kostenverpflichtungen. Die aufgeführten Tarife helfen bei der Budgetplanung, aber die tatsächlichen Kosten hängen von der Prompt-Länge, der Bild- oder Videoverwendung, der generierten Ausgabelänge, Wiederholungen, dem Cache-Verhalten und der Art und Weise ab, wie deine Anwendung lange Kontexte handhabt.
GLM 4.6V Benchmark- und Leistungsindikatoren
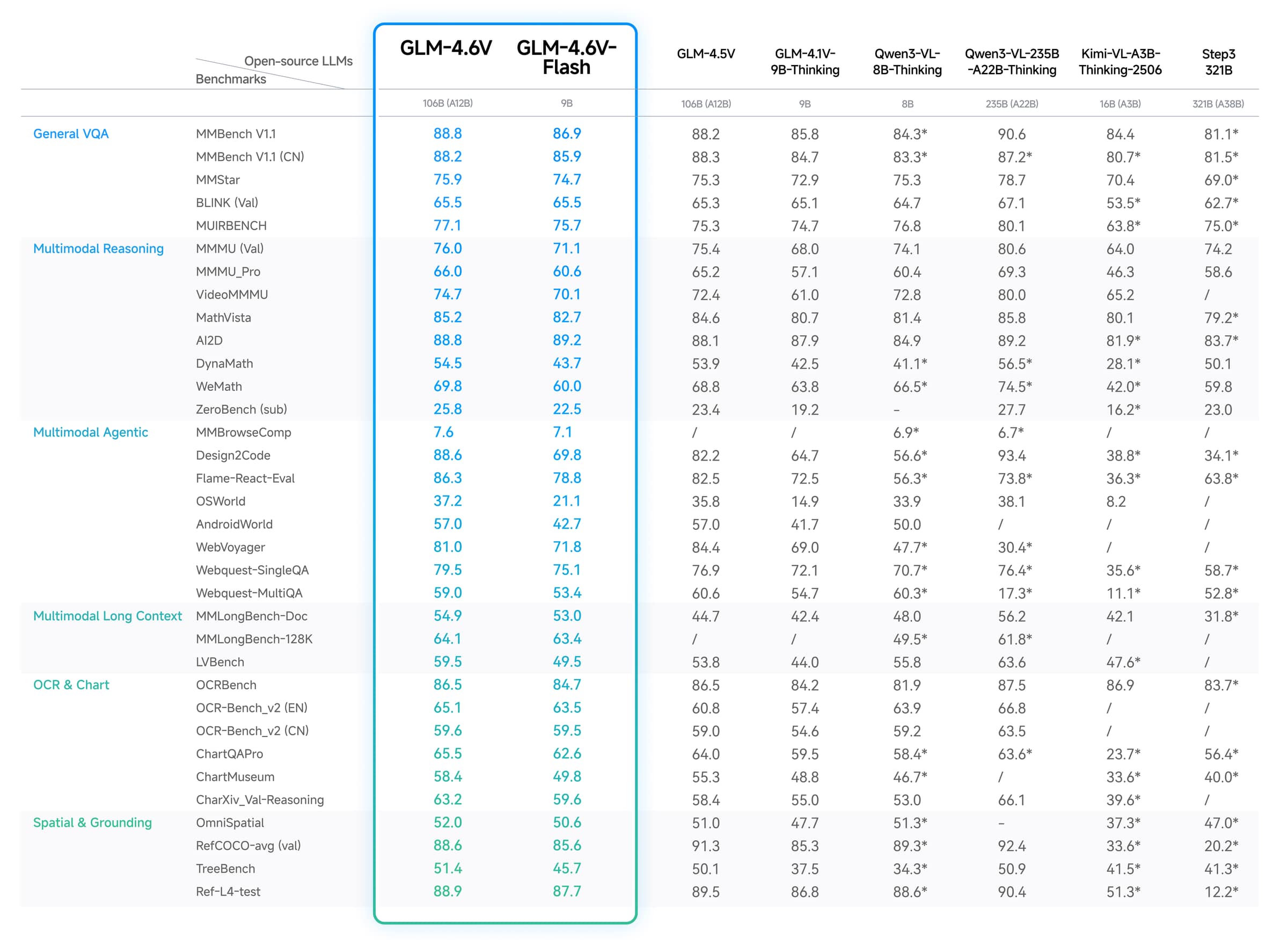
Dieses Diagramm stammt aus den offiziellen GLM-4.6V Modellmaterialien, die von Z.ai veröffentlicht und im öffentlichen GLM-V Repository gespiegelt wurden. Die wichtigste Erkenntnis ist die Breite: GLM-4.6V wird als allgemeines Vision-Language-Modell für OCR, Diagrammlesen, räumliches Denken, Dokumentenverständnis und agentenähnliche multimodale Aufgaben positioniert.
Das Diagramm ist jedoch nur ein Ausgangspunkt. Es sagt nicht aus, wie gut GLM-4.6V dein Schema befolgt oder wie es sich bei deinen spezifischen Screenshots und Dokumentmischungen verhält. Vor der Ausbringung solltest du Folgendes überprüfen:
- repräsentative Screenshots und Dokumentseiten aus deinem realen Workflow,
- Fälle mit strukturierten Ausgaben oder Tool-Calling, die deinen Parser bestehen müssen,
- Latenz und Kosten bei deiner typischen Kontextgröße.
Verwende das offizielle Diagramm als Beleg, dass GLM-4.6V breite multimodale Ambitionen hat, und triff die endgültige Entscheidung auf Basis deiner eigenen Genauigkeits-, Latenz- und Kosten-Tests.
Wichtige Fähigkeiten für Entwickler
Vision-Input für Screenshot- und Dokument-Workflows
GLM 4.6V ist nützlich, wenn deine Anwendung visuelle Eingaben verarbeiten muss und nicht nur Text. Produktteams können UI-Screenshots zusammenfassen. Supportteams können visuelle Bugreports klassifizieren. Dokumenten-Workflows können Layout-Hinweise bewahren, die oft verloren gehen, wenn eine Seite zu früh in reinen Text umgewandelt wird.
Das ersetzt jedoch nicht die Validierung. Bei sicherheitskritischen Dokumenten, privaten Kundenscreenshots oder regulierten Daten stelle sicher, dass der Workflow deinen Datenschutz- und Datenverarbeitungsanforderungen entspricht, bevor du visuelle Eingaben an eine externe API sendest.
Langer Kontext für umfangreiche multimodale Prompts
Das Kontextfenster von 131.072 Token gibt Teams Raum, um Anweisungen, Konversationshistorie, abgerufenen Text, Dokumentauszüge und visuelle Referenzen zu kombinieren. Das ist wertvoll für Aufgaben, bei denen die Antwort von mehreren Kontextteilen abhängt, nicht nur von einem einzelnen isolierten Bild.
Langer Kontext sollte dennoch als Budget- und Latenzressource behandelt werden. Sende nicht standardmäßig eine unbegrenzte Konversationshistorie oder jede verfügbare Datei. Kürze, fasse zusammen und leite Kontext basierend auf der Aufgabe weiter.
Function Calling und strukturierte Ausgaben
Novita AI listet GLM 4.6V mit Unterstützung für Function Calling und strukturierte Ausgaben. Das macht das Modell relevant für agentenähnliche Anwendungen, bei denen visuelles Verständnis mit kontrollierter Anwendungslogik verbunden werden muss, z. B. beim Erstellen eines Support-Tickets, Auswählen eines Retrieval-Tools oder Zurückgeben eines JSON-Klassifikationsobjekts.
Die Anwendung sollte die Autorität bleiben. Sie muss weiterhin Tool-Argumente validieren, Berechtigungen prüfen, Schema-Regeln durchsetzen und Bestätigungen verlangen, bevor Aktionen ausgeführt werden, die Benutzerdaten, Abrechnung oder externe Systeme betreffen.
Wann sollte GLM 4.6V verwendet werden?
Visuelle Support-Triage
Verwende GLM 4.6V, wenn Benutzer Screenshots zusammen mit Textbeschreibungen einreichen. Das Modell kann helfen, den sichtbaren UI-Zustand zusammenzufassen, wahrscheinliche Problemkategorien zu extrahieren und prägnante Notizen für einen menschlichen Prüfer oder nachgelagerten Workflow zu erstellen.
Dokument- und Diagramminterpretation
Verwende GLM 4.6V, wenn das visuelle Layout wichtig ist. Beispiele sind gescannte Formulare, Berichtscreenshots, tabellenlastige Bilder, Dashboard-Diagramme und Design-Artefakte, bei denen die Antwort von der sichtbaren Struktur abhängt.
Multimodale Agenten-Workflows
Verwende GLM 4.6V, wenn ein Agent den visuellen Zustand inspizieren und dann einen strukturierten nächsten Schritt wählen muss. Ein visueller QA-Agent, ein Browser-ähnlicher Workflow oder ein Operations-Assistent kann von der Kombination aus visuellem Kontext mit Function Calling und strukturierten Ausgaben profitieren.
Wann sollte GLM 4.6V nicht verwendet werden?
Wähle GLM 4.6V nicht nur, weil es multimodal ist. Wenn dein Workflow rein textbasiert, kurz, latenzempfindlich und hochvolumig ist, ist ein textfokussiertes Modell möglicherweise die bessere Standardwahl. Vergleiche Modelle in der Novita AI Modellbibliothek und bewerte Kosten, Latenz und Ausgabequalität anhand deiner eigenen Prompts.
Vermeide es, vertrauliche Bilder oder Dokumente zu senden, bis der Workflow klare Regeln für Datenschutz, Aufbewahrung und Zugriffskontrolle hat. Wenn er vertrauliche Kundendaten, medizinische Informationen, Finanzdokumente oder interne Anmeldeinformationen auf Screenshots verarbeitet, füge vor Modellaufrufen Schwärzungs- und Richtlinienprüfungen hinzu.
Sei auch vorsichtig bei Video. Novita AI listet Video als Eingabemodalität für GLM 4.6V, aber produktive Video-Workflows hängen von Dateizugriff, Dauer, Größe, Latenz und Request-Formatierung ab. Validiere deinen genauen Videopfad, bevor du ihn zu einer zentralen benutzerseitigen Funktion machst.
Wie GLM 4.6V in deinen API-Workflow passt
GLM 4.6V eignet sich am besten als multimodale Reasoning-Ebene hinter einer kontrollierten Anwendungsschnittstelle. Eine typische Architektur hält API-Schlüssel in einem Backend-Dienst, akzeptiert Benutzertext und freigegebene visuelle Eingaben, ruft die Novita AI API mit zai-org/glm-4.6v auf, validiert die Antwort und leitet das Ergebnis dann in das Produkterlebnis weiter.
Für reine Text-Smoke-Tests ist die OpenAI-kompatible Chat-Completions-API der Hauptweg. Für Vision-Workflows sollte die Anwendung visuelle Eingaben erst hinzufügen, nachdem Authentifizierung, Routing, Logging und Timeout-Verhalten bereits funktionieren. Für Tool- oder JSON-Workflows sollte die Modellausgabe vor jeder nachgelagerten Aktion eine deterministische Validierung durchlaufen.
Teams, die bereits OpenAI-kompatible Clients verwenden, können oft dasselbe Client-Muster mit der Novita AI Basis-URL wiederverwenden. Teams, die neue Integrationen entwickeln, sollten mit dem Novita AI LLM API-Leitfaden und der Chat-Completions-API-Referenz beginnen.
Fazit
GLM 4.6V auf Novita AI ist am sinnvollsten, wenn deine Anwendung ein Vision-Language-Verständnis über eine serverlose API benötigt, insbesondere für Screenshot-Triage, Dokument-Bild-Analyse, Diagramminterpretation, visuelle QA oder multimodale Agenten-Workflows. Die bestätigte Novita AI-Listung bietet genügend Modell-, Preis-, Limit- und Endpunktinformationen, um eine strukturierte Evaluierung zu rechtfertigen.
Wähle ein anderes Modell, wenn der Workload rein textbasiert, extrem latenzempfindlich oder von günstigen, hochvolumigen Anfragen dominiert ist, bei denen visuelle Eingaben die Antwort nicht wesentlich verändern. Vergleiche in diesen Fällen GLM 4.6V mit textfokussierten Optionen und leite nur visuelle Aufgaben an das multimodale Modell weiter.
Der nächste praktische Schritt besteht darin, GLM 4.6V mit einem kleinen, workload-spezifischen Testsatz auszuprobieren, unter Verwendung der Modell-ID zai-org/glm-4.6v, der aktuellen Novita AI-Preise und der API-Referenz für die exakte Request-Syntax.
FAQ
Was ist GLM 4.6V?
GLM 4.6V ist eine multimodale GLM-Modellvariante für Vision-Language-Aufgaben. Auf Novita AI wird es als serverloses Modell mit Text-, Bild- und Video-Input und Text-Output gelistet.
Ist GLM 4.6V auf Novita AI verfügbar?
Ja. Zum Stand vom 24. Juni 2026 listet Novita AI GLM 4.6V auf seiner Modellseite mit serverlosem API-Zugriff und der Modell-ID zai-org/glm-4.6v.
Wie lautet die Modell-ID für GLM 4.6V auf Novita AI?
Verwende zai-org/glm-4.6v als API-Modell-ID in Novita AI-Requests und Modell-Gateway-Konfigurationen.
Wie viel kostet GLM 4.6V auf Novita AI?
Zum Stand vom 24. Juni 2026 listet Novita AI GLM 4.6V mit Preisen von $0,30 pro 1 Mio. Input-Tokens, $0,055 pro 1 Mio. Cache-Read-Input-Tokens und $0,90 pro 1 Mio. Output-Tokens.
Wofür wird GLM 4.6V am besten eingesetzt?
GLM 4.6V wird am besten für API-Workflows eingesetzt, bei denen visuelle Eingaben eine Rolle spielen, darunter Screenshot-Triage, Dokument-Bild-Interpretation, Diagrammanalyse, visuelle QA und multimodale Agenten-Workflows, die Textausgaben aus Bild- oder Videokontext benötigen.
Unterstützt GLM 4.6V Function Calling?
Ja. Die aktuelle Novita AI Modellseite listet Function Calling-Unterstützung für GLM 4.6V. Validiere Tool-Argumente und Berechtigungen in deiner Anwendung, bevor du basierend auf der Modellausgabe eine Aktion ausführst.



