

- Puntos clave
- ¿Qué es GLM 4.6V?
- Acceso a la API de GLM 4.6V en Novita AI
- Resumen de especificaciones y precios de GLM 4.6V
- Señales de rendimiento y benchmark de GLM 4.6V
- Capacidades clave para desarrolladores
- Cuándo usar GLM 4.6V
- Cuándo no usar GLM 4.6V
- Cómo encaja GLM 4.6V en tu flujo de trabajo de API
- Conclusión
- Preguntas frecuentes
- Artículos recomendados
GLM 4.6V está disponible en Novita AI como un modelo multimodal serverless para equipos que necesitan inteligencia artificial de visión con llamada nativa a herramientas a través de una API alojada. A partir del 24 de junio de 2026, Novita AI enumera el ID del modelo como zai-org/glm-4.6v, acceso a la API compatible con OpenAI, una ventana de contexto de 131,072 tokens, máximo de 32,768 tokens de salida, llamada a funciones, salidas estructuradas, soporte de razonamiento y precios de $0.30 por 1M de tokens de entrada, $0.055 por 1M de tokens de entrada leídos de caché y $0.90 por 1M de tokens de salida.
Puntos clave
- GLM 4.6V es un modelo con capacidad de visión en Novita AI para equipos que crean análisis de capturas de pantalla, comprensión de documentos e imágenes, preguntas visuales, soporte multimodal y flujos de trabajo de agentes.
- Novita AI enumera GLM 4.6V como un modelo serverless con soporte de entrada de texto, imagen y video, salida de texto, acceso a completaciones de chat compatible con OpenAI y soporte de API compatible con Anthropic.
- Las páginas actuales de modelos y precios de Novita AI enumeran
zai-org/glm-4.6vcon una ventana de contexto de 131,072 tokens, máximo de 32,768 tokens de salida y precios por token divididos entre tokens de entrada, de entrada leídos de caché y de salida. - Este artículo es una página de lanzamiento e información del modelo. Úsalo para decidir si GLM 4.6V se adapta a tu carga de trabajo; usa la referencia de la API de Novita cuando necesites la sintaxis exacta de las solicitudes para la implementación en producción.
¿Qué es GLM 4.6V?
GLM 4.6V es una variante del modelo GLM multimodal diseñada para tareas de visión y lenguaje. En términos prácticos para desarrolladores, es útil cuando el prompt necesita combinar instrucciones en lenguaje natural con evidencia visual como capturas de pantalla, páginas de documentos, gráficos, paneles, formularios o contexto derivado de video.
A diferencia de un modelo de chat solo de texto, GLM 4.6V está diseñado para casos donde la entrada visual cambia la respuesta. Un flujo de trabajo de soporte puede necesitar inspeccionar una captura de pantalla de un cliente antes de sugerir una solución. Un equipo de producto puede querer que un modelo compare una captura de pantalla de la interfaz de usuario con el comportamiento esperado. Una ruta de automatización de documentos puede necesitar razonar sobre el diseño, tablas y etiquetas visibles que son difíciles de preservar después de una extracción simple de OCR.
En Novita AI, GLM 4.6V se posiciona como una opción de API serverless. Esto brinda a los equipos una forma directa de evaluar e integrar el modelo sin gestionar infraestructura de GPU, servicio del modelo, escalado o configuración del tiempo de ejecución de inferencia. El camino práctico es comenzar desde la página del modelo de Novita AI y la documentación de la API, luego conectar a través de la superficie de la API compatible con OpenAI.
Acceso a la API de GLM 4.6V en Novita AI
Novita AI enumera GLM 4.6V en la biblioteca de modelos con el ID de API zai-org/glm-4.6v. Para equipos que ya usan completaciones de chat compatibles con OpenAI, los detalles principales de integración son la clave de API de Novita AI, la URL base de Novita AI y el ID del modelo GLM 4.6V.
La página del modelo GLM 4.6V actual identifica la disponibilidad específica del modelo, modalidades, límites, indicadores de funcionalidad y precios. La referencia de la API de completaciones de chat de Novita documenta el endpoint de completaciones de chat y la forma de la respuesta para las llamadas a la API.
A alto nivel, una integración de la API de GLM 4.6V utiliza:
| Elemento de la API | Valor actual |
|---|---|
| ID del modelo de API | zai-org/glm-4.6v |
| URL base compatible con OpenAI | https://api.novita.ai/openai |
| Ruta REST de completaciones de chat | https://api.novita.ai/openai/v1/chat/completions |
| Salida típica | Respuesta de texto en formato de completaciones de chat |
| Autenticación | Clave de API de Novita AI pasada como token de portador |
Esta página se centra en los datos a nivel de lanzamiento que los desarrolladores suelen necesitar primero: disponibilidad, acceso a la API, precios, límites y adecuación. Para los campos exactos de la solicitud, comportamiento de streaming, sintaxis de herramientas y parámetros de salida estructurada, usa la referencia actual de la API antes de enviar código de producción.
Resumen de especificaciones y precios de GLM 4.6V
La siguiente tabla resume los datos de GLM 4.6V que más importan al decidir si evaluar el modelo en Novita AI.
| Campo | Detalles |
|---|---|
| Nombre mostrado | GLM 4.6V |
| ID del modelo de API | zai-org/glm-4.6v |
| Ruta de acceso | API serverless |
| URL base | https://api.novita.ai/openai |
| Endpoint de completaciones de chat | https://api.novita.ai/openai/v1/chat/completions |
| Modalidades de entrada | Texto, imagen, video |
| Modalidad de salida | Texto |
| Ventana de contexto | 131,072 tokens |
| Máximo de tokens de salida | 32,768 tokens |
| Indicadores de funcionalidad | Llamada a funciones, salidas estructuradas, razonamiento |
| Precios | $0.30 por 1M de tokens de entrada; $0.055 por 1M de tokens de entrada leídos de caché; $0.90 por 1M de tokens de salida |
| Mejor adecuación | Flujos de trabajo de API de visión-lenguaje que necesitan respuestas de texto a partir de evidencia visual |
Los precios pueden cambiar, así que confirma la página de precios actual de Novita AI antes del lanzamiento a producción o compromisos de costos visibles para el cliente. Las tarifas listadas son útiles para el presupuesto inicial, pero el gasto real aún depende de la longitud del prompt, el uso de imágenes o video, la longitud de la salida generada, los reintentos, el comportamiento de la caché y la forma en que tu aplicación maneja el contexto largo.
Señales de rendimiento y benchmark de GLM 4.6V
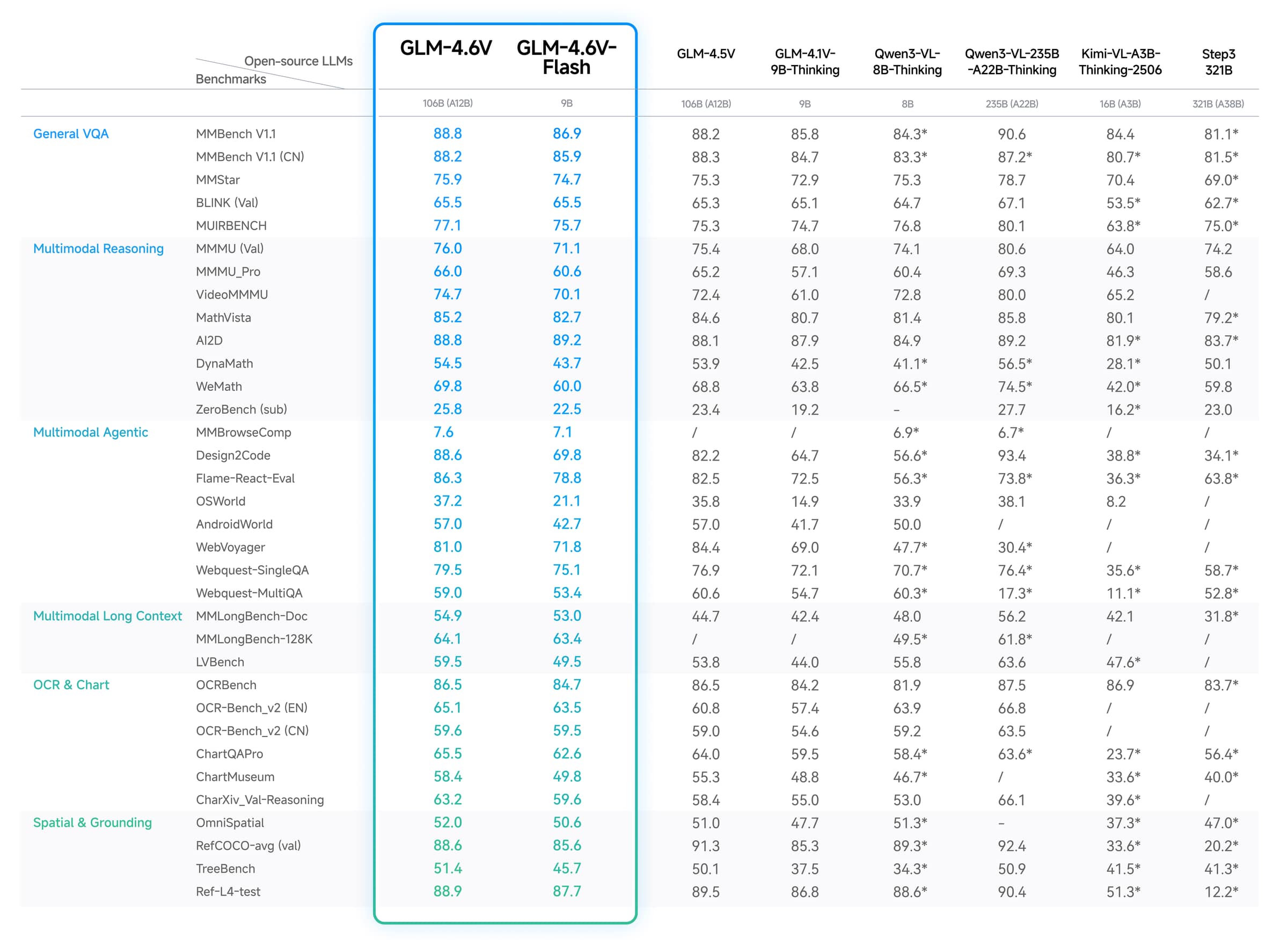
Este gráfico proviene de los materiales oficiales del modelo GLM-4.6V publicados por Z.ai y reflejados en el repositorio público GLM-V. La conclusión principal es la amplitud: GLM-4.6V se posiciona como un modelo de visión y lenguaje de propósito general en tareas de OCR, lectura de gráficos, razonamiento espacial, comprensión de documentos y tareas multimodales de estilo agente.
El gráfico sigue siendo solo un punto de partida. No te dice qué tan bien seguirá GLM-4.6V tu esquema ni cómo se comportará con tu combinación exacta de capturas de pantalla y documentos. Antes del lanzamiento, verifica:
- capturas de pantalla y páginas de documentos representativos de tu flujo de trabajo real,
- casos de salida estructurada o llamada a herramientas que deben pasar por tu analizador,
- latencia y costo en tu tamaño de contexto típico.
Usa el gráfico oficial como evidencia de que GLM-4.6V tiene amplias ambiciones multimodales, luego toma la decisión final basada en tus propias pruebas de precisión, latencia y costo.
Capacidades clave para desarrolladores
Entrada de visión para flujos de trabajo de capturas de pantalla y documentos
GLM 4.6V es útil cuando tu aplicación necesita razonar sobre entrada visual en lugar de solo texto. Los equipos de producto pueden resumir capturas de pantalla de la interfaz de usuario. Los equipos de soporte pueden clasificar informes de errores visuales. Los flujos de trabajo de documentos pueden preservar pistas de diseño que a menudo se pierden cuando una página se convierte a texto plano demasiado pronto.
Esto no elimina la necesidad de validación. Para documentos de alto riesgo, capturas de pantalla privadas de clientes o datos regulados, asegúrate de que el flujo de trabajo cumpla con tus requisitos de privacidad y manejo de datos antes de enviar entrada visual a una API externa.
Contexto largo para prompts multimodales ricos
La ventana de contexto de 131,072 tokens brinda a los equipos espacio para combinar instrucciones, historial de conversación, texto recuperado, extractos de documentos y referencias visuales. Esto es valioso para tareas donde la respuesta depende de varias piezas de contexto, no de una sola imagen aislada.
El contexto largo aún debe tratarse como un recurso de presupuesto y latencia. No envíes historial de conversación ilimitado ni todos los archivos disponibles por defecto. Recorta, resume y enruta el contexto según la tarea.
Llamada a funciones y salidas estructuradas
Novita AI enumera GLM 4.6V con soporte de llamada a funciones y salidas estructuradas. Esto hace que el modelo sea relevante para aplicaciones de tipo agente donde la comprensión visual necesita conectarse a la lógica controlada de la aplicación, como crear un ticket de soporte, seleccionar una herramienta de recuperación o devolver un objeto JSON de clasificación.
La aplicación debe seguir siendo la autoridad. Aún necesita validar los argumentos de las herramientas, verificar permisos, aplicar reglas de esquema y requerir confirmación antes de tomar acciones que afecten datos de usuario, facturación o sistemas externos.
Cuándo usar GLM 4.6V
Triage de soporte visual
Usa GLM 4.6V cuando los usuarios envíen capturas de pantalla junto con descripciones de texto. El modelo puede ayudar a resumir el estado visible de la interfaz de usuario, extraer categorías probables de problemas y producir notas concisas para un revisor humano o un flujo de trabajo posterior.
Interpretación de documentos y gráficos
Usa GLM 4.6V cuando el diseño visual sea importante. Los ejemplos incluyen formularios escaneados, capturas de pantalla de informes, imágenes con muchas tablas, gráficos de paneles y artefactos de diseño donde la respuesta depende de la estructura visible.
Flujos de trabajo de agentes multimodales
Usa GLM 4.6V cuando un agente necesite inspeccionar el estado visual y luego elegir un siguiente paso estructurado. Un agente de preguntas visuales, un flujo de trabajo similar a un navegador o un asistente de operaciones pueden beneficiarse de combinar el contexto visual con llamada a funciones y salidas estructuradas.
Cuándo no usar GLM 4.6V
No elijas GLM 4.6V solo porque es multimodal. Si tu ruta es solo texto, corta, sensible a la latencia y de alto volumen, un modelo centrado en texto puede ser una mejor opción predeterminada. Compara modelos en la biblioteca de modelos de Novita AI y evalúa coste, latencia y calidad de salida con tus propios prompts.
Evita enviar imágenes o documentos sensibles hasta que el flujo de trabajo tenga reglas claras de privacidad, retención y control de acceso. Si maneja registros confidenciales de clientes, información médica, documentos financieros o credenciales internas visibles en capturas de pantalla, agrega comprobaciones de redacción y políticas antes de las llamadas al modelo.
También ten cuidado con el video. Novita AI enumera el video como una modalidad de entrada para GLM 4.6V, pero los flujos de trabajo de video en producción dependen del acceso a archivos, duración, tamaño, latencia y formato de solicitud. Valida tu ruta de video exacta antes de convertirla en una función principal orientada al usuario.
Cómo encaja GLM 4.6V en tu flujo de trabajo de API
GLM 4.6V encaja mejor como una capa de razonamiento multimodal detrás de una interfaz de aplicación controlada. Una arquitectura típica mantiene las claves de API en un servicio backend, acepta texto del usuario y entradas visuales aprobadas, llama a la API de Novita AI con zai-org/glm-4.6v, valida la respuesta y luego enruta el resultado a la experiencia del producto.
Para pruebas de humo solo con texto, la API de completaciones de chat compatible con OpenAI es la ruta principal. Para flujos de trabajo de visión, la aplicación debe agregar entrada visual solo después de que la autenticación, el enrutamiento, el registro y el comportamiento de tiempo de espera ya estén funcionando. Para flujos de trabajo de herramientas o JSON, la salida del modelo debe pasar por una validación determinista antes de cualquier acción posterior.
Los equipos que ya usan clientes compatibles con OpenAI a menudo pueden reutilizar el mismo patrón de cliente con la URL base de Novita AI. Los equipos que crean nuevas integraciones deben comenzar desde la guía de la API LLM de Novita AI y la referencia de la API de completaciones de chat.
Conclusión
GLM 4.6V en Novita AI tiene más sentido cuando tu aplicación necesita comprensión de visión y lenguaje a través de una API serverless, especialmente para triage de capturas de pantalla, razonamiento de documentos e imágenes, interpretación de gráficos, preguntas visuales o flujos de trabajo de agentes multimodales. El listado verificado de Novita AI proporciona información suficiente sobre el modelo, precios, límites y endpoint para justificar una evaluación estructurada.
Elige otro modelo si la carga de trabajo es solo texto, extremadamente sensible a la latencia o está dominada por solicitudes de bajo costo y alto volumen donde la entrada visual no cambia materialmente la respuesta. En esos casos, compara GLM 4.6V con opciones centradas en texto y enruta solo las tareas visuales al modelo multimodal.
El siguiente paso práctico es probar GLM 4.6V en un conjunto de pruebas pequeño y específico de la carga de trabajo, usando el ID del modelo zai-org/glm-4.6v, los precios actuales de Novita AI y la referencia de la API para la sintaxis exacta de las solicitudes.
Preguntas frecuentes
¿Qué es GLM 4.6V?
GLM 4.6V es una variante del modelo GLM multimodal para tareas de visión y lenguaje. En Novita AI, se enumera como un modelo serverless con entradas de texto, imagen y video y salida de texto.
¿Está GLM 4.6V disponible en Novita AI?
Sí. A partir del 24 de junio de 2026, Novita AI enumera GLM 4.6V en su página de modelos con acceso a API serverless y el ID del modelo zai-org/glm-4.6v.
¿Cuál es el ID del modelo para GLM 4.6V en Novita AI?
Usa zai-org/glm-4.6v como ID del modelo de API en las solicitudes de Novita AI y la configuración de la puerta de enlace del modelo.
¿Cuánto cuesta GLM 4.6V en Novita AI?
A partir del 24 de junio de 2026, Novita AI enumera GLM 4.6V a $0.30 por 1M de tokens de entrada, $0.055 por 1M de tokens de entrada leídos de caché y $0.90 por 1M de tokens de salida.
¿Para qué se usa mejor GLM 4.6V?
GLM 4.6V se usa mejor para flujos de trabajo de API donde la entrada visual es importante, incluyendo triage de capturas de pantalla, interpretación de documentos e imágenes, análisis de gráficos, preguntas visuales y flujos de trabajo de agentes multimodales que necesitan salida de texto a partir de contexto de imagen o video.
¿GLM 4.6V es compatible con llamada a funciones?
Sí. La página actual del modelo de Novita AI enumera soporte de llamada a funciones para GLM 4.6V. Valida los argumentos de las herramientas y los permisos en tu aplicación antes de tomar cualquier acción basada en la salida del modelo.



