

Today, we’re excited to announce Novita AI’s partnership with Zhipu AI to bring day-one support for GLM-4.5V on the Novita AI platform as a Zhipu AI launch partner.
GLM-4.5V represents a breakthrough in multimodal AI technology, now available on Novita AI’s developer-friendly platform. This state-of-the-art visual reasoning model achieves benchmark-leading performance across 42 tests while remaining accessible to businesses and developers of all sizes.
GLM-4.5V covers common tasks such as image, video, and document understanding, as well as GUI agent operations. Whether you’re developing customer service bots, content analysis tools, or automation solutions, GLM-4.5V on Novita AI simplifies the entire development process.
Current pricing on Novita AI: $0.6 / M input tokens, $1.8 / M output tokens
What is GLM-4.5V and Why It Matters for Your Business
GLM-4.5V is Zhipu AI’s latest multimodal AI model that supercharges the GLM-4.5 foundation with comprehensive visual reasoning capabilities. Built on the robust 106B-parameter Mixture of Experts (MoE) architecture based on GLM-4.5-Air, this model inherits advanced techniques from GLM-4.1V-Thinking while achieving unprecedented scaling efficiency.
As an official Zhipu AI launch partner, Novita AI provides businesses with immediate access to enterprise-grade visual AI without the complexity of training or maintaining your own models. Instead of juggling multiple specialized models, you get a unified solution that handles everything from basic image recognition to complex video analysis and document processing.
Key Performance Advantages: SOTA Results Across 42 Benchmarks
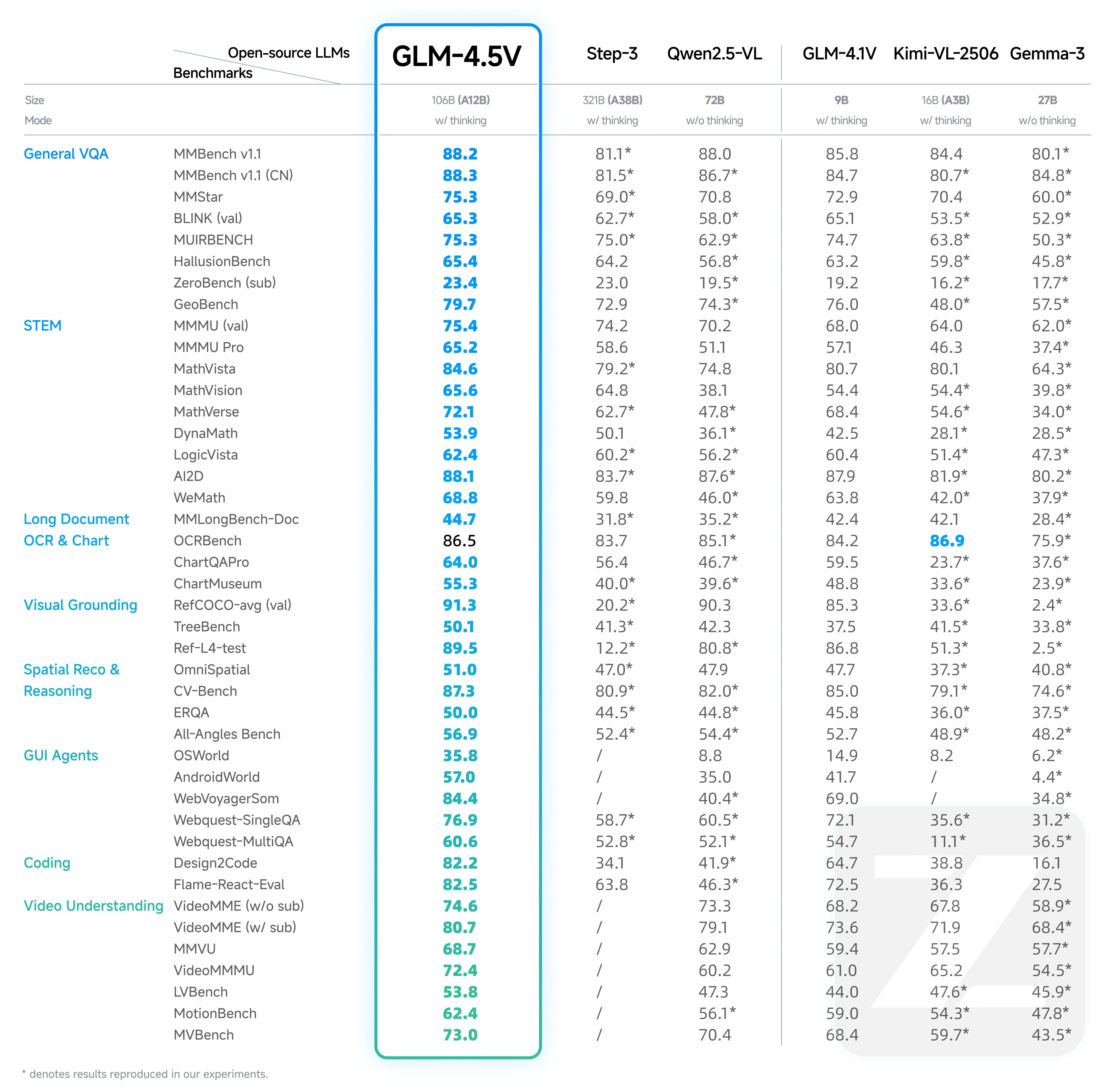
GLM-4.5V achieves state-of-the-art performance among open-source models of comparable size, validated across 42 comprehensive benchmarks.
Through efficient hybrid training techniques, GLM-4.5V delivers consistent, reliable results across diverse visual content types.
On Novita AI’s optimized infrastructure, developers experience minimal latency and maximum throughput, making GLM-4.5V practical for production applications. The model’s performance translates directly into better user experiences, whether you’re building customer-facing applications or internal automation tools.
Core Visual Reasoning Capabilities
GLM-4.5V offers five essential visual reasoning capabilities that cover virtually any business use case:
Image Reasoning: Understand complex scenes, analyze multiple images simultaneously, and recognize geographical locations with precision. Perfect for e-commerce product analysis, content moderation, and location-based services.
Video Understanding: Process long videos with storyboard analysis and event recognition capabilities. Ideal for content creators, security applications, and educational platforms requiring video comprehension.
GUI Tasks: Read screens, recognize icons, and assist with desktop operations. Essential for RPA solutions, accessibility tools, and automated testing frameworks.
Chart and Document Analysis: Extract insights from research reports, financial documents, and complex visualizations. Critical for business intelligence, compliance, and data automation workflows.
Grounding Capability: Precisely localize visual elements within images or videos. Valuable for quality control, augmented reality applications, and detailed visual search implementations.
The model also introduces a Thinking Mode switch, allowing users to balance between quick responses and deep reasoning. This switch works the same as in the GLM-4.5 language model.
Getting Started with GLM-4.5V on Novita AI Platform
Accessing GLM-4.5V through Novita AI offers multiple pathways tailored to different technical expertise levels and use cases. Whether you’re a business user exploring AI capabilities or a developer building production applications, Novita AI provides the tools you need.
Use the Playground (Available Now - No Coding Required)
- Instant Access: Sign up and start experimenting with GLM-4.5V models in seconds
- Interactive Interface: Test complex visual reasoning prompts and visualize chain-of-thought outputs in real-time
- Model Comparison: Compare GLM-4.5V with other leading models for your specific use case
The playground enables you to upload images directly, test various prompts, and see immediate results without any technical setup. Perfect for prototyping, testing ideas, and understanding model capabilities before full implementation.
Integrate via API (Live and Ready - For Developers)
Connect GLM-4.5V to your applications with Novita AI’s unified REST API.
Option 1: Direct API Integration (Python Example)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Key Features:
- OpenAI-Compatible API for seamless integration
- Flexible parameter control for fine-tuning responses
- Streaming support for real-time responses
Option 2: Multi-Agent Workflows with OpenAI Agents SDK
Build sophisticated multi-agent systems using GLM-4.5V:
- Plug-and-Play Integration: Use GLM-4.5V in any OpenAI Agents workflow
- Advanced Agent Capabilities: Support for handoffs, routing, and tool integration with superior visual reasoning performance
- Scalable Architecture: Design agents that leverage GLM-4.5V’s unified reasoning, coding, and visual analysis capabilities
Connect with Third-Party Platforms
Development Tools: Seamlessly integrate with popular IDEs and development environments like Cursor, Trae, Qwen Code and Cline through OpenAI-compatible APIs.
Orchestration Frameworks: Connect with LangChain, Dify, CrewAI, Langflow, and other AI orchestration platforms using official connectors.
Hugging Face Integration: Novita AI serves as an official inference provider of Hugging Face, ensuring broad ecosystem compatibility.
Novita AI handles all infrastructure, scaling, and optimization, letting you focus on building great applications with GLM-4.5V’s powerful visual capabilities.
Use Cases for Businesses and Developers
GLM-4.5V unlocks powerful visual AI capabilities across diverse business scenarios. The model’s versatility and accuracy make it ideal for both customer-facing applications and internal automation initiatives.
Image Comprehension
Upload any image and receive detailed descriptions, object identification, and contextual analysis with remarkable depth. GLM-4.5V goes beyond basic recognition—it understands context, relationships, and can even engage in creative tasks like word-guessing games from visual clues.
Businesses leverage this for inventory management systems that automatically categorize products, quality control processes that detect defects with precision, and automated content tagging that improves searchability.
E-commerce platforms use image comprehension to generate product descriptions, while content creators automate alt-text generation for accessibility and SEO optimization.
Video Comprehension (MP4 Format Supported)
Process MP4 videos to extract comprehensive insights, identify key moments, and generate detailed summaries. GLM-4.5V excels at analyzing complex video content—from sports match analysis that identifies crucial plays and evaluates team performance, to surveillance footage monitoring that detects anomalies in real-time.
Marketing teams analyze campaign videos to measure engagement and extract performance metrics, while educational platforms transform lengthy lectures into searchable, indexed content.
The model’s ability to understand temporal sequences and events makes it invaluable for media companies creating highlight reels and content summaries automatically.
Geography Guessing and Location Intelligence
Identify locations from visual cues with impressive accuracy, even recognizing specific landmarks, architectural styles, and geographic coordinates. GLM-4.5V can pinpoint exact locations from movie scenes, identify cities from street views, and even provide latitude/longitude coordinates.
Travel applications use this for destination identification and trip planning, real estate platforms automatically tag properties with location context and nearby amenities, while logistics companies verify delivery locations and optimize routing.
Film location scouts and tourism boards leverage this capability to identify and promote filming locations and tourist attractions.
Object Detection and Visual Search
Precisely identify and locate specific objects within complex images, down to details like jersey numbers in sports footage or specific furniture pieces in interior designs. GLM-4.5V not only finds objects but provides contextual information—identifying styles, suggesting similar products, and even recommending complementary items.
Retail analytics platforms track product placement and customer interactions, manufacturing lines ensure assembly correctness, while interior designers use it to create cohesive room designs.
Webpage Replication and UI Analysis
Analyze and replicate web interfaces with high fidelity, generating clean HTML and CSS code from screenshots. GLM-4.5V understands UI elements, layout structures, and design patterns, making it invaluable for rapid prototyping and competitive analysis.
Development teams accelerate UI creation by converting design mockups to code, QA teams automate visual regression testing, while UX researchers analyze competitor interfaces for design insights.
The model excels at creating responsive, accessible interfaces that maintain the original design intent while improving code quality.
Choosing the Right Model API for Your Application
Novita AI offers different GLM model APIs optimized for specific use cases. Select the appropriate endpoint based on your application requirements to maximize performance and cost-efficiency.
GLM-4.5 API - For General Multimodal Tasks
- Best for: Basic image descriptions, simple visual Q&A, standard document analysis
- Use when: You need quick visual understanding alongside text processing
- Ideal for: Chatbots, content moderation, and general-purpose AI assistants
For everyday use: Continue using GLM-4.5 as usual—simply upload any image or video you’d like analyzed or discussed.
GLM-4.5V API - For Advanced Visual Reasoning
- Best for: Complex multi-image analysis, detailed video understanding, precise object localization
- Use when: Visual accuracy and detail are critical to your application
- Ideal for: Medical imaging, surveillance systems, quality inspection, and professional video analysis
For advanced vision exploration: Choose the GLM-4.5V model to access specialized visual reasoning scenarios and unlock the full potential of our cutting-edge vision capabilities.
Conclusion
GLM-4.5V on Novita AI represents a paradigm shift in how businesses and developers approach visual AI applications. By combining state-of-the-art performance with an accessible, developer-friendly platform, it eliminates traditional barriers to advanced AI implementation.
Whether you’re building simple image classification tools or complex multimodal systems, GLM-4.5V provides the capabilities and flexibility needed for success. The model’s comprehensive visual reasoning abilities, from image analysis to video understanding, enable innovative solutions across every industry.
Start building with GLM-4.5V on Novita AI today and transform how your applications see and understand the visual world.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



