

本日、Novita AI は Zhipu AI とのパートナーシップを発表し、Zhipu AI のローンチパートナーとして Novita AI プラットフォームで GLM-4.5V を初日からサポートします。
GLM-4.5V はマルチモーダル AI 技術のブレークスルーであり、現在 Novita AI の開発者向けプラットフォームで利用可能です。この最先端のビジュアル推論モデルは、42のテストでベンチマークをリードするパフォーマンスを達成しながら、あらゆる規模の企業や開発者がアクセスしやすいままです。
GLM-4.5V は、画像、動画、ドキュメント理解、そして GUI エージェント操作などの一般的なタスクをカバーします。カスタマーサービスボット、コンテンツ分析ツール、自動化ソリューションのいずれを開発している場合でも、Novita AI 上の GLM-4.5V が開発プロセス全体を簡素化します。
現在のNovita AIの料金:入力トークン100万あたり0.6ドル、出力トークン100万あたり1.8ドル
GLM-4.5V とは何か、そしてそれがビジネスにとって重要な理由
GLM-4.5V は Zhipu AI の最新マルチモーダル AI モデルであり、GLM-4.5 の基盤に包括的なビジュアル推論機能を追加したものです。GLM-4.5-Air をベースとした強固な106Bパラメータの Mixture of Experts(MoE)アーキテクチャ上に構築されており、GLM-4.1V-Thinking からの高度な技術を継承し、前例のないスケーリング効率を実現しています。
公式の Zhipu AI ローンチパートナーとして、Novita AI は、独自のモデルをトレーニングまたは維持する複雑さなしに、企業にエンタープライズグレードのビジュアル AI への即時アクセスを提供します。複数の専門モデルを切り替える代わりに、基本的な画像認識から複雑な動画分析やドキュメント処理までを処理する統合ソリューションを手に入れられます。
主要なパフォーマンス上の利点:42のベンチマークでSOTA(最先端)結果
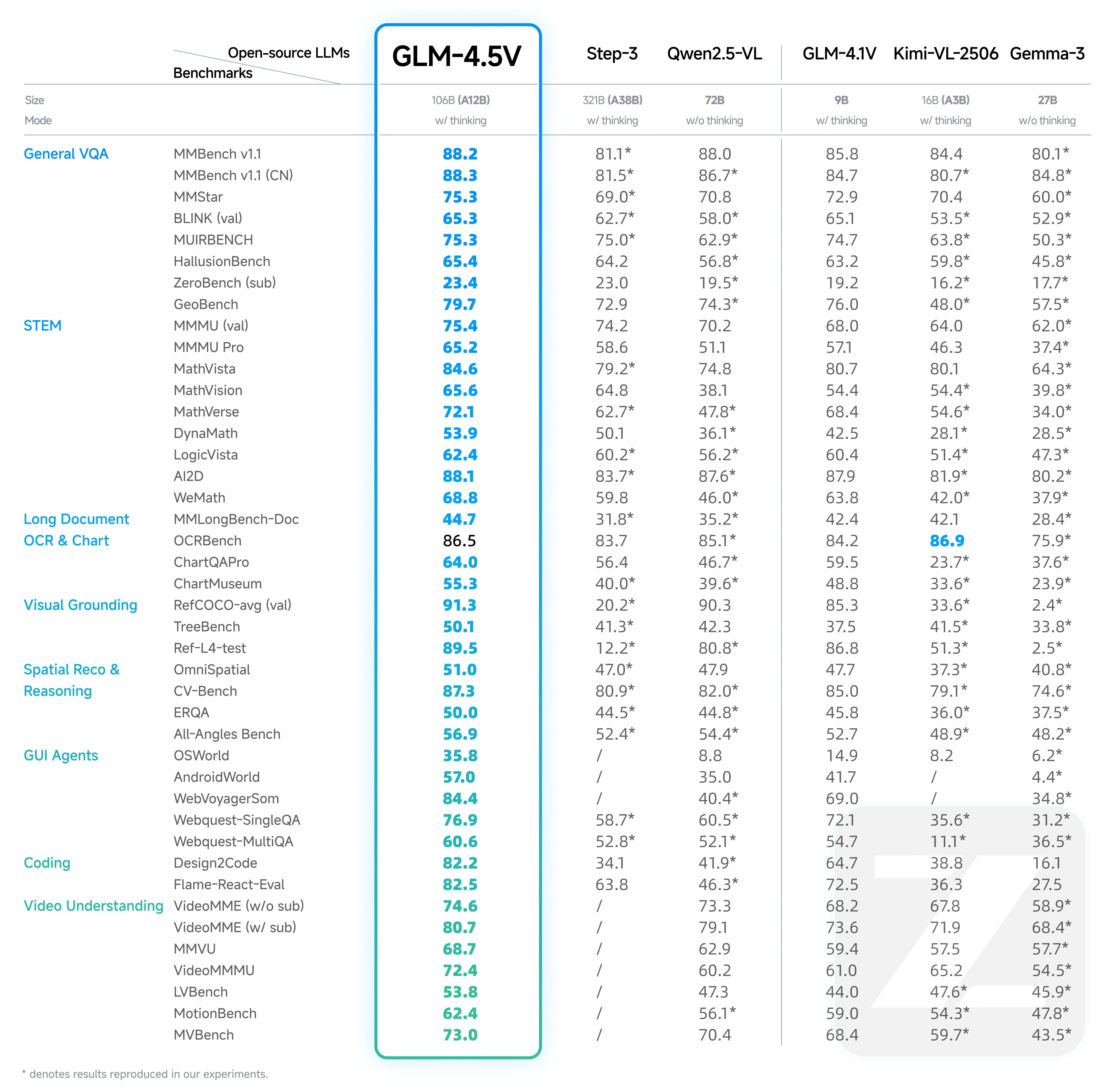
GLM-4.5V は、同規模のオープンソースモデルの中で最先端のパフォーマンスを達成し、42の包括的なベンチマークで検証されています。
効率的なハイブリッドトレーニング技術により、GLM-4.5V は多様なビジュアルコンテンツタイプにわたって一貫した信頼性の高い結果を提供します。
Novita AI の最適化されたインフラストラクチャ上で、開発者は最小限のレイテンシと最大のスループットを体験でき、GLM-4.5V を本番アプリケーションで実用的にします。顧客向けアプリケーションを構築する場合でも、内部自動化ツールを構築する場合でも、モデルのパフォーマンスはより良いユーザー体験に直接つながります。
中核となるビジュアル推論機能
GLM-4.5V は、実質的にあらゆるビジネスユースケースをカバーする5つの必須ビジュアル推論機能を提供します。
画像推論: 複雑なシーンを理解し、複数の画像を同時に分析し、地理的位置を正確に認識します。eコマースの製品分析、コンテンツモデレーション、位置情報ベースのサービスに最適です。
動画理解: ストーリーボード分析とイベント認識機能を使用して長時間の動画を処理します。コンテンツクリエイター、セキュリティアプリケーション、動画理解を必要とする教育プラットフォームに最適です。
GUI タスク: スクリーンを読み取り、アイコンを認識し、デスクトップ操作を支援します。RPA ソリューション、アクセシビリティツール、自動テストフレームワークに不可欠です。
チャート・ドキュメント分析: 調査レポート、財務ドキュメント、複雑なビジュアライゼーションから洞察を抽出します。ビジネスインテリジェンス、コンプライアンス、データ自動化ワークフローに重要です。
グラウンディング機能: 画像または動画内のビジュアル要素を正確に特定します。品質管理、拡張現実アプリケーション、詳細なビジュアル検索の実装に価値があります。
このモデルは Thinking Mode スイッチも導入しており、ユーザーは迅速な応答と深い推論のバランスを取ることができます。このスイッチは GLM-4.5 言語モデルと同じように機能します。
Novita AI プラットフォームで GLM-4.5V を使い始める
Novita AI を介した GLM-4.5V へのアクセスは、さまざまな技術的専門知識レベルとユースケースに合わせた複数の経路を提供します。AI 機能を探索しているビジネスユーザーでも、本番アプリケーションを構築している開発者でも、Novita AI は必要なツールを提供します。
プレイグラウンドを使用する(現在利用可能 - コーディング不要)
- 即時アクセス: サインアップして、GLM-4.5V モデル を数秒で試し始めましょう
- インタラクティブなインターフェース: 複雑なビジュアル推論のプロンプトをテストし、思考連鎖の出力をリアルタイムで可視化
- モデル比較: GLM-4.5V を他の主要モデルと特定のユースケースで比較
プレイグラウンドでは、画像を直接アップロードし、さまざまなプロンプトをテストし、技術的なセットアップなしで即座に結果を確認できます。完全な実装前のプロトタイピング、アイデアのテスト、モデル機能の理解に最適です。
API 経由で統合する(稼働準備完了 - 開発者向け)
Novita AI の統一 REST API を使用して、GLM-4.5V をアプリケーションに接続します。
オプション1:直接 API 統合(Python の例)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
主要機能:
- OpenAI 互換 API によるシームレスな統合
- 応答を微調整するための柔軟なパラメータ制御
- リアルタイム応答のストリーミングサポート
オプション2:OpenAI Agents SDK によるマルチエージェントワークフロー
GLM-4.5V を使用して高度なマルチエージェントシステムを構築します。
- プラグ&プレイ統合: 任意の OpenAI Agents ワークフロー で GLM-4.5V を使用
- 高度なエージェント機能: 優れたビジュアル推論パフォーマンスによるハンドオフ、ルーティング、ツール統合のサポート
- スケーラブルなアーキテクチャ: GLM-4.5V の統合された推論、コーディング、ビジュアル分析機能を活用するエージェントを設計
サードパーティプラットフォームとの連携
開発ツール: OpenAI 互換 API を介して、人気の IDE や開発環境(Cursor、Trae、Qwen Code、Cline など)とシームレスに統合。
オーケストレーションフレームワーク: 公式コネクタを使用して、LangChain、Dify、CrewAI、Langflow などの AI オーケストレーションプラットフォームと接続。
Hugging Face 統合: Novita AI は Hugging Face の公式推論プロバイダーとして機能し、幅広いエコシステムの互換性を保証します。
Novita AI はインフラストラクチャ、スケーリング、最適化のすべてを処理するため、開発者は GLM-4.5V の強力なビジュアル機能を使って優れたアプリケーションの構築に集中できます。
企業と開発者向けユースケース
GLM-4.5V は、さまざまなビジネスシナリオにわたって強力なビジュアル AI 機能を解放します。モデルの多用途性と正確性により、顧客向けアプリケーションと内部自動化イニシアチブの両方に最適です。
画像理解
任意の画像をアップロードすると、詳細な説明、オブジェクト識別、および顕著な深さのコンテキスト分析を受け取れます。GLM-4.5V は基本的な認識を超え、コンテキストや関係を理解し、視覚的な手がかりから単語当てゲームのような創造的なタスクにも取り組めます。
企業はこれを、製品を自動的に分類する在庫管理システム、欠陥を正確に検出する品質管理プロセス、検索可能性を向上させる自動コンテンツタグ付けに活用しています。
eコマースプラットフォームは画像理解を使用して製品説明を生成し、コンテンツクリエイターはアクセシビリティとSEO最適化のために代替テキスト生成を自動化しています。
動画理解(MP4形式対応)
MP4 動画を処理して包括的な洞察を抽出し、キーモーメントを特定し、詳細な要約を生成します。GLM-4.5V は複雑な動画コンテンツの分析に優れています。例えば、重要なプレーを特定しチームパフォーマンスを評価するスポーツマッチ分析から、異常をリアルタイムで検出する監視映像モニタリングまで。
マーケティングチームはキャンペーン動画を分析してエンゲージメントを測定し、パフォーマンス指標を抽出します。教育プラットフォームは長い講義を検索可能でインデックス化されたコンテンツに変換します。
モデルが時系列とイベントを理解する能力は、メディア企業がハイライトリールやコンテンツ要約を自動生成する際に非常に価値があります。
地理推測と位置情報インテリジェンス
視覚的な手がかりから驚くべき精度で位置を特定し、特定のランドマーク、建築様式、地理座標さえも認識します。GLM-4.5V は、映画のシーンから正確な場所を特定し、ストリートビューから都市を識別し、緯度/経度座標を提供することもできます。
旅行アプリケーションでは目的地の特定や旅行計画に、不動産プラットフォームでは物件に位置情報コンテキストと近隣のアメニティを自動タグ付けするために、物流企業では配達場所の確認とルート最適化に使用されています。
映画ロケハンや観光局は、この機能を活用して撮影ロケ地や観光名所を特定・宣伝しています。
物体検出とビジュアル検索
複雑な画像内で特定のオブジェクトを正確に特定・検出します。スポーツ映像の背番号やインテリアデザインの特定の家具まで細かく対応。GLM-4.5V はオブジェクトを見つけるだけでなく、スタイルの識別、類似商品の提案、さらには補完アイテムの推奨など、コンテキスト情報も提供します。
小売分析プラットフォームは製品配置と顧客インタラクションを追跡し、製造ラインは組立の正確性を保証し、インテリアデザイナーは統一感のある部屋デザインを作成するために使用します。
Webページ複製とUI分析
Web インターフェースを高い忠実度で分析・複製し、スクリーンショットからクリーンな HTML および CSS コードを生成します。GLM-4.5V は UI 要素、レイアウト構造、デザインパターンを理解するため、迅速なプロトタイピングや競合分析に非常に価値があります。
開発チームはデザインモックアップをコードに変換して UI 作成を加速し、QA チームはビジュアルリグレッションテストを自動化し、UX リサーチャーはデザインインサイトを得るために競合他社のインターフェースを分析します。
このモデルは、元のデザイン意図を維持しながらコード品質を向上させ、レスポンシブでアクセシブルなインターフェースを作成することに優れています。
アプリケーションに最適なモデル API の選択
Novita AI は特定のユースケースに最適化されたさまざまな GLM モデル API を提供しています。アプリケーション要件に基づいて適切なエンドポイントを選択し、パフォーマンスとコスト効率を最大化します。
GLM-4.5 API - 一般的なマルチモーダルタスク向け
- 最適: 基本的な画像説明、シンプルなビジュアル Q&A、標準的なドキュメント分析
- 使用するケース: テキスト処理と一緒に素早いビジュアル理解が必要な場合
- 理想的な用途: チャットボット、コンテンツモデレーション、汎用 AI アシスタント
日常的な使用: 通常どおり GLM-4.5 を引き続き使用してください。分析または説明したい画像や動画をアップロードするだけで OK です。
GLM-4.5V API - 高度なビジュアル推論向け
- 最適: 複雑なマルチ画像分析、詳細な動画理解、精密なオブジェクト位置特定
- 使用するケース: アプリケーションにおいてビジュアルの精度と詳細が重要な場合
- 理想的な用途: 医用画像、監視システム、品質検査、プロフェッショナルな動画分析
高度なビジョン探索向け: GLM-4.5V モデル を選択して、専門的なビジュアル推論シナリオにアクセスし、最先端のビジョン機能の可能性を最大限に引き出しましょう。
結論
Novita AI 上の GLM-4.5V は、企業と開発者がビジュアル AI アプリケーションにアプローチする方法におけるパラダイムシフトを表しています。最先端のパフォーマンスとアクセスしやすく開発者向けのプラットフォームを組み合わせることで、高度な AI 実装に対する従来の障壁を取り除きます。
シンプルな画像分類ツールから複雑なマルチモーダルシステムまで、GLM-4.5V は成功に必要な機能と柔軟性を提供します。画像分析から動画理解に至るまで、モデルの包括的なビジュアル推論能力により、あらゆる業界で革新的なソリューションが可能になります。
今すぐ Novita AI で GLM-4.5V を使い始め、あなたのアプリケーションがビジュアルワールドをどのように見て理解するかを変革しましょう。
Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、アプリ構築とスケーリングのための手頃で信頼性の高い GPU クラウドも提供しています。



