

今天,我们很高兴地宣布 Novita AI 与智谱 AI 达成合作,作为智谱 AI 的首发合作伙伴,在 Novita AI 平台上提供对 GLM-4.5V 的首日支持。
GLM-4.5V 代表了多模态 AI 技术的突破,现已上线 Novita AI 的开发者友好平台。这款最先进的视觉推理模型在 42 项测试中均取得了基准领先的性能,同时仍对各类规模的企业和开发者保持可及性。
GLM-4.5V 覆盖图像、视频和文档理解以及 GUI 智能体操作等常见任务。无论您是在开发客服机器人、内容分析工具还是自动化解决方案,Novita AI 上的 GLM-4.5V 都能简化整个开发流程。
当前 Novita AI 定价:输入 token 每百万 0.6 美元,输出 token 每百万 1.8 美元
GLM-4.5V 是什么,为什么它对您的业务至关重要
GLM-4.5V 是智谱 AI 最新的多模态 AI 模型,它在 GLM-4.5 基础模型之上增强了全面的视觉推理能力。该模型基于 GLM-4.5-Air 的 106B 参数混合专家(MoE)架构构建,继承了 GLM-4.1V-Thinking 的先进技术,同时实现了前所未有的扩展效率。
作为智谱 AI 的官方首发合作伙伴,Novita AI 为企业提供即时访问企业级视觉 AI 的能力,无需自行训练或维护模型。您无需同时管理多个专用模型,而是获得一个统一解决方案,能够处理从基础图像识别到复杂视频分析和文档处理的所有任务。
关键性能优势:在 42 项基准测试中均取得 SOTA 结果
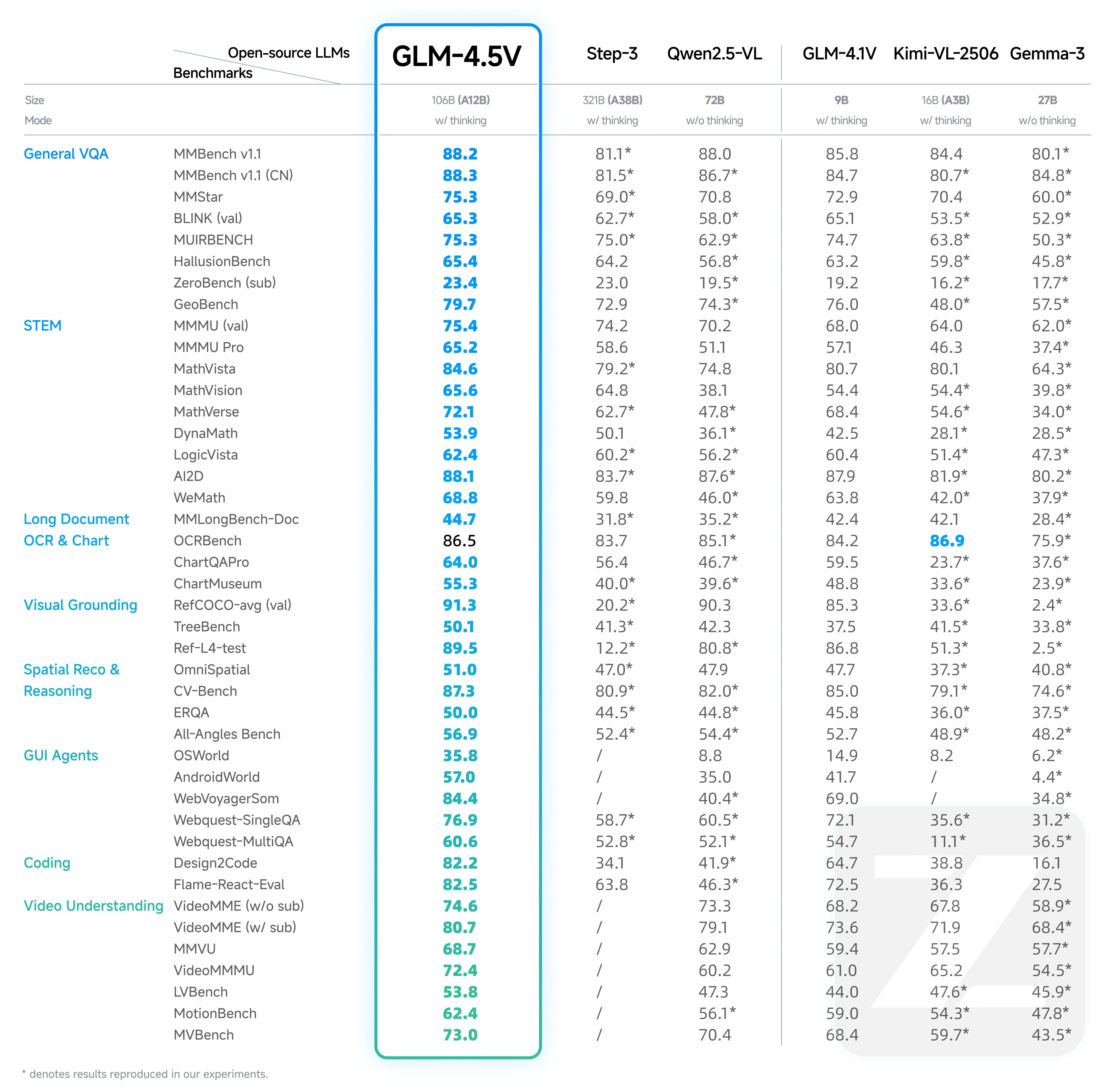
GLM-4.5V 在同等规模的开源模型中达到了最先进的性能,经 42 项综合基准验证。
通过高效的混合训练技术,GLM-4.5V 在各种视觉内容类型上都能提供一致、可靠的结果。
在 Novita AI 优化的基础设施上,开发者能够体验到最低的延迟和最高的吞吐量,使得 GLM-4.5V 可用于生产应用。无论您是在构建面向客户的应用还是内部自动化工具,该模型的性能都能直接转化为更好的用户体验。
核心视觉推理能力
GLM-4.5V 提供五项基本的视觉推理能力,几乎覆盖所有业务用例:
图像推理:理解复杂场景,同时分析多张图像,精准识别地理位置。非常适合电商产品分析、内容审核以及基于位置的服务。
视频理解:处理长视频,具备故事板分析和事件识别能力。适用于内容创作者、安全应用以及需要视频理解的教育平台。
GUI 任务:读取屏幕、识别图标并协助桌面操作。对于 RPA 解决方案、无障碍工具和自动化测试框架至关重要。
图表与文档分析:从研究报告、财务文档和复杂可视化中提取洞察。对商业智能、合规性和数据自动化工作流至关重要。
定位能力:在图像或视频中精确定位视觉元素。对质量控制、增强现实应用以及详细的视觉搜索实现非常有价值。
该模型还引入了 思考模式 开关,允许用户在快速响应与深度推理之间进行权衡。该开关的工作方式与 GLM-4.5 语言模型相同。
在 Novita AI 平台上开始使用 GLM-4.5V
通过 Novita AI 访问 GLM-4.5V 有多种途径,可适应不同的技术专业水平和用例。无论您是探索 AI 能力的业务用户,还是构建生产应用的开发者,Novita AI 都为您提供了所需的工具。
使用 Playground(现已可用 — 无需编码)
- 即时访问:注册 并立即开始使用 GLM-4.5V 模型 进行实验
- 交互式界面:实时测试复杂的视觉推理提示,可视化思维链输出
- 模型比较:将 GLM-4.5V 与针对您特定用例的其他领先模型进行比较
Playground 允许您直接上传图像、测试各种提示,无需任何技术设置即可立即查看结果。非常适合在全面实施之前进行原型设计、测试创意和了解模型能力。
通过 API 集成(已上线并可立即使用 — 面向开发者)
使用 Novita AI 的统一 REST API 将 GLM-4.5V 连接到您的应用。
选项 1:直接 API 集成(Python 示例)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
主要特性:
- 兼容 OpenAI 的 API,实现无缝集成
- 灵活的参数控制,用于微调响应
- 支持流式传输,实现实时响应
选项 2:使用 OpenAI Agents SDK 构建多智能体工作流
使用 GLM-4.5V 构建复杂的多智能体系统:
- 即插即用集成:在任何 OpenAI Agents 工作流 中使用 GLM-4.5V
- 高级智能体能力:支持任务移交、路由和工具集成,具备卓越的视觉推理性能
- 可扩展架构:设计利用 GLM-4.5V 统一推理、编码和视觉分析能力的智能体
连接第三方平台
开发工具:通过兼容 OpenAI 的 API 与流行的 IDE 和开发环境(如 Cursor、Trae、Qwen Code 和 Cline)无缝集成。
编排框架:使用官方连接器与 LangChain、Dify、CrewAI、Langflow 及其他 AI 编排平台连接。
Hugging Face 集成:Novita AI 是 Hugging Face 的官方推理提供商,确保广泛的生态系统兼容性。
Novita AI 负责所有基础设施、扩展和优化,让您能够专注于使用 GLM-4.5V 强大的视觉能力构建出色的应用。
企业和开发者的用例
GLM-4.5V 在多种业务场景中解锁了强大的视觉 AI 能力。该模型的多功能性和准确性使其既适用于面向客户的应用,也适用于内部自动化项目。
图像理解
上传任意图像,即可获得包含深度上下文的详细描述、物体识别与分析。GLM-4.5V 超越了基础识别——它理解上下文、关系,甚至能从视觉线索参与猜词游戏等创意任务。
企业利用这一能力来构建自动分类产品的库存管理系统、精确检测缺陷的质量控制流程,以及提高可搜索性的自动内容标记。
电商平台使用图像理解来生成产品描述,而内容创作者则自动生成替代文本以实现可访问性和 SEO 优化。
视频理解(支持 MP4 格式)
处理 MP4 视频以提取全面洞察、识别关键时刻并生成详细摘要。GLM-4.5V 擅长分析复杂的视频内容——从识别关键比赛动作并评估球队表现的体育赛事分析,到实时检测异常的监控录像监测。
营销团队分析活动视频以衡量参与度并提取绩效指标,而教育平台则将冗长的讲座转变为可搜索、有索引的内容。
该模型理解时间序列和事件的能力,使其对于自动生成精彩片段和内容摘要的媒体公司极具价值。
地理猜测与位置智能
从视觉线索中准确识别位置,甚至能识别特定地标、建筑风格和地理坐标。GLM-4.5V 可以从电影场景中精确定位地点、从街景中识别城市,甚至提供经纬度坐标。
旅游应用利用此功能进行目的地识别和行程规划,房地产平台自动为房产添加位置上下文和附近设施标签,物流公司则验证交付地点并优化路线。
电影取景地和旅游局利用这一能力来识别和推广拍摄地点及旅游景点。
物体检测与视觉搜索
在复杂图像中精准识别并定位特定物体,精细到体育画面中的球衣号码或室内设计中的特定家具。GLM-4.5V 不仅能找到物体,还能提供上下文信息——识别风格、推荐类似产品,甚至推荐配套物品。
零售分析平台跟踪产品摆放和客户互动,制造生产线确保装配正确,室内设计师则利用它来创建协调的房间设计。
网页复制与 UI 分析
高保真度分析并复制网页界面,从截图生成清晰的 HTML 和 CSS 代码。GLM-4.5V 理解 UI 元素、布局结构和设计模式,使其成为快速原型设计和竞品分析的宝贵工具。
开发团队通过将设计稿转化为代码来加速 UI 创建,QA 团队自动进行视觉回归测试,UX 研究人员则分析竞品界面以获得设计洞察。
该模型擅长创建响应式、可访问的界面,在保持原始设计意图的同时提高代码质量。
为您的应用选择合适的模型 API
Novita AI 提供针对特定用例优化的不同 GLM 模型 API。根据您的应用需求选择合适的端点,以最大化性能和成本效率。
GLM-4.5 API — 适用于通用多模态任务
- 最适合:基础图像描述、简单的视觉问答、标准文档分析
- 使用场景:需要快速视觉理解同时进行文本处理
- 理想应用:聊天机器人、内容审核和通用 AI 助手
日常使用:继续像往常一样使用 GLM-4.5——只需上传任意图像或视频即可进行分析和讨论。
GLM-4.5V API — 适用于高级视觉推理
- 最适合:复杂的多图像分析、详细的视频理解、精确的物体定位
- 使用场景:视觉准确性和细节对您的应用至关重要
- 理想应用:医学影像、监控系统、质量检测和专业视频分析
高级视觉探索:选择 GLM-4.5V 模型 以访问专门的视觉推理场景,解锁我们尖端的视觉能力全部潜力。
结论
Novita AI 上的 GLM-4.5V 代表了企业和开发者处理视觉 AI 应用的范式转变。通过将最先进的性能与易于访问的开发者友好平台相结合,它消除了高级 AI 实施的传统障碍。
无论您是在构建简单的图像分类工具还是复杂的多模态系统,GLM-4.5V 都能提供成功所需的能力和灵活性。该模型从图像分析到视频理解的全面视觉推理能力,使每个行业都能实现创新解决方案。
立即在 Novita AI 上使用 GLM-4.5V 开始构建,彻底改变您的应用理解和感知视觉世界的方式。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济且可靠的 GPU 云用于构建和扩展。



