

Today, we’re excited to announce Novita AI’s partnership with Z.ai to bring day-one support for GLM-4.5 on the Novita AI platform as a Z.ai launch partner. This groundbreaking collaboration introduces the world’s most unified AI model series, combining advanced reasoning, sophisticated coding capabilities, and native agentic functionality in a single, powerful framework designed for developers building the next generation of AI applications.
Novita AI is now offering the groundbreaking GLM-4.5 model (355B total params, 32B active): Built with hybrid reasoning modes offering both thinking mode for complex reasoning and tool usage, and non-thinking mode for instant responses. Ranks 2nd place overall across comprehensive benchmarks.
Both models feature 128k context length and native function calling capacity, available through Novita AI’s optimized inference infrastructure.
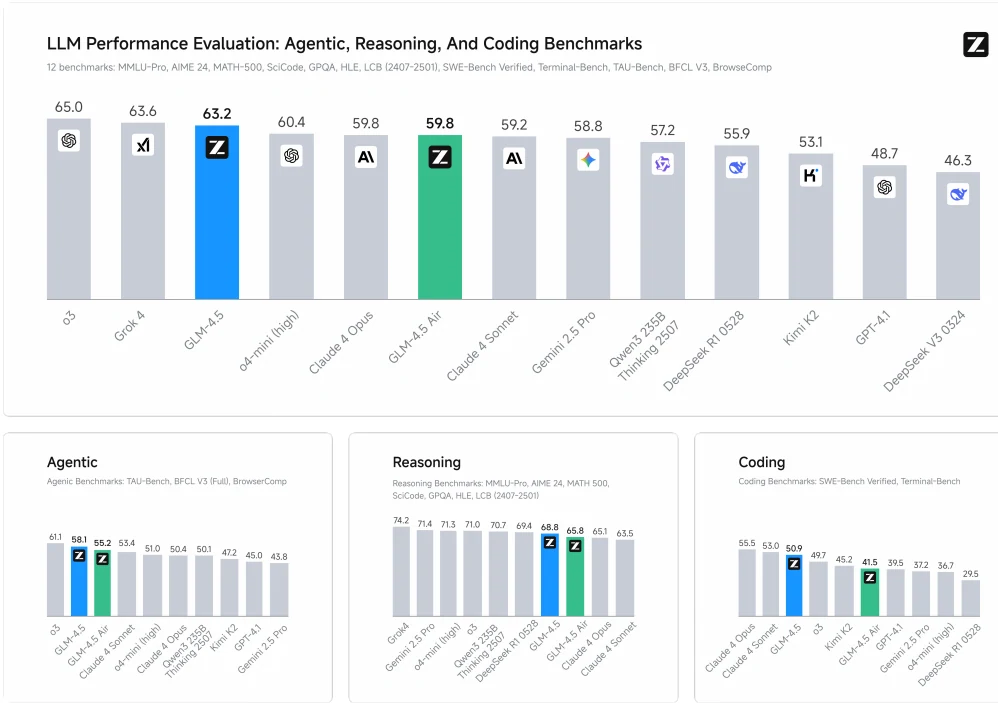
⚡ Overall Performance
GLM-4.5 ranks 2nd place and GLM-4.5-Air ranks 5th across 12 benchmarks covering agentic (3), reasoning (7), and coding (2) tasks, compared against models from OpenAI, Anthropic, Google DeepMind, xAI, Alibaba, Moonshot, and DeepSeek.
GLM-4.5 unifies all capabilities where previous models excelled in specific areas—coding, math, or reasoning—but none achieved best performance across all tasks.
Agentic Tasks
GLM-4.5 is a foundation model optimized for agentic tasks. It provides 128k context length and native function calling capacity. Z.ai measured its agent ability on τ-bench and BFCL-v3 (Berkeley Function Calling Leaderboard v3). On both benchmarks, GLM-4.5 matches the performance of Claude-4-Sonnet.
Web browsing is a popular agentic application that requires complex reasoning and multi-turn tool using. Z.ai evaluated GLM-4.5 on the BrowseComp benchmark, a challenging benchmark for web browsing that consists of complicated questions that expect short answers. With access to the web browsing tool, GLM-4.5 gives correct answers for 26.4% of all questions, clearly outperforming Claude-4-Opus (18.8%) and close to o4-mini-high (28.0%).
| Benchmark | GLM-4.5 | GLM-4.5-Air | o3 | o4-mini-high | GPT-4.1 | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | Qwen3 235B Thinking 2507 | DeepSeek R1 0528 | Kimi K2 | Grok4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TAU-bench | 70.1 | 69.4 | 61.2 | 57.4 | 62.0 | 70.5 | 70.3 | 62.5 | 73.2 | 58.7 | 62.6 | 67.5 |
| BFCL v3 (Full) | 77.8 | 76.4 | 72.4 | 67.2 | 68.9 | 61.8 | 75.2 | 61.2 | 72.4 | 63.8 | 71.1 | 66.2 |
| BrowseComp | 26.4 | 21.3 | 49.7 | 28.3 | 4.1 | 18.8 | 14.7 | 7.6 | 4.6 | 3.2 | 7.9 | 32.6 |
Reasoning
Under the thinking mode, GLM-4.5 and GLM-4.5-Air can solve complex reasoning problems including mathematics, science, and logical problems.
| Benchmark | GLM-4.5 | GLM-4.5-Air | o3 | o4-mini-high | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | Gemini 2.5 Flash | DeepSeek R1 0528 | Qwen3-235B Thinking 2507 | Grok4 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MMLU Pro | 84.6 | 81.4 | 85.3 | 83.2 | 87.3 | 84.2 | 86.2 | 83.2 | 84.9 | 84.5 | 86.6 |
| AIME24 | 91.0 | 89.4 | 90.3 | 94.0 | 75.7 | 77.3 | 88.7 | 82.3 | 89.3 | 94.1 | 94.3 |
| MATH 500 | 98.2 | 98.1 | 99.2 | 98.9 | 98.2 | 99.1 | 96.7 | 98.1 | 98.3 | 98.0 | 99.0 |
| SciCode | 41.7 | 37.3 | 41.0 | 46.5 | 39.8 | 40.0 | 42.8 | 39.4 | 40.3 | 42.9 | 45.7 |
| GPQA | 79.1 | 75.0 | 82.7 | 78.4 | 79.6 | 77.7 | 84.4 | 79.0 | 81.3 | 81.1 | 87.7 |
| HLE | 14.4 | 10.6 | 20.0 | 17.5 | 11.7 | 8.5 | 21.1 | 11.1 | 14.9 | 15.8 | 23.9 |
| LiveCodeBench (2407-2501) | 72.9 | 70.7 | 78.4 | 80.4 | 63.6 | 58.0 | 80.1 | 69.5 | 77.0 | 78.2 | 81.9 |
| AA-Index (Estimated) | 67.7 | 64.8 | 70.0 | 69.8 | 64.4 | 62.7 | 70.5 | 65.1 | 68.3 | 69.4 | 73.2 |
Coding
GLM-4.5 is also good at coding, including both building a coding project from scratch, and agentically solving coding tasks in existing projects. It can be seamlessly combined with existing coding toolkits such as Claude Code, Roo Code, and CodeGeex. To evaluate the coding capability, Z.ai compared different models on SWE-bench Verified and Terminal Bench.
| Benchmark | GLM-4.5 | GLM-4.5-Air | o3 | o4-mini-high | GPT-4.1 | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | Gemini 2.5 Flash | Qwen3 235B Thinking 2507 | Qwen3 235B | DeepSeek R1 0528 | Kimi K2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SWE-bench Verified | 64.2 | 57.6 | 69.1 | 54.8 | 48.6 | 67.8 | 70.4 | 49.0 | 60.4 | 35.0 | 36.2 | 41.4 | 65.4 |
| Terminal-Bench | 37.5 | 30.0 | 30.2 | 18.5 | 30.3 | 43.2 | 35.5 | 25.3 | 16.8 | 6.3 | 6.6 | 17.5 | 25.0 |
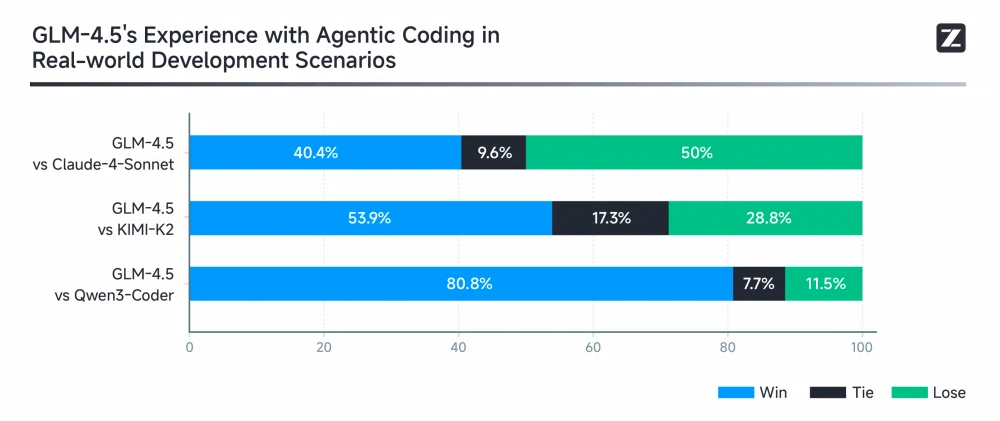
To evaluate GLM-4.5’s agentic coding capabilities in real-world scenarios, Z.ai used Claude Code to conduct comprehensive testing against Claude-4-Sonnet, Kimi K2, and Qwen3-Coder using 52 coding tasks covering frontend development, tool development, data analysis, testing, and algorithm applications. GLM-4.5 wins against Kimi K2 in 53.9% of the tasks and dominates Qwen3-Coder with an 80.8% win rate, while showing room for improvement against Claude-4-Sonnet.
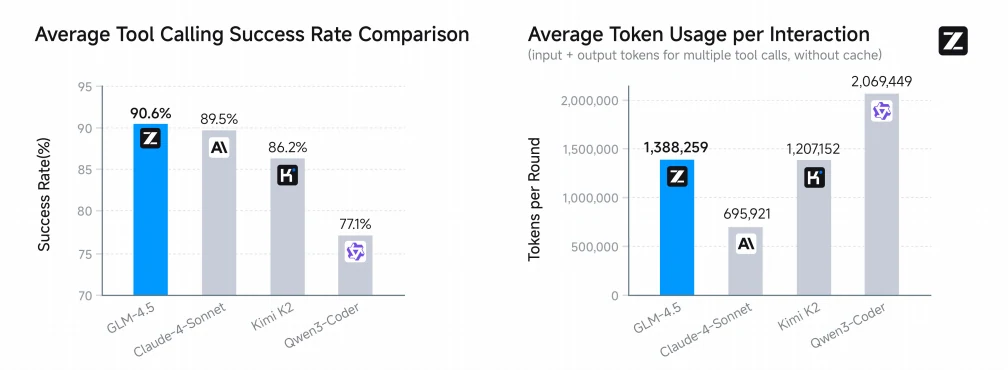
Notably, GLM-4.5 achieves the highest average tool calling success rate at 90.6%, outperforming Claude-4-Sonnet (89.5%), Kimi-K2 (86.2%), and Qwen3-Coder (77.1%), demonstrating superior reliability and efficiency in agentic coding tasks.
🚀 Get Started with Novita AI
Use the Playground (No Coding Required)
- Instant Access: Sign up and start experimenting with GLM-4.5 in seconds
- Interactive Interface: Test complex reasoning prompts and visualize structured outputs in real-time
- Model Comparison: Compare GLM-4.5 with other leading models for your specific use case
Integrate via API (For Developers)
Connect GLM-4.5 to your applications with Novita AI’s unified REST API.
Option 1: Direct API Integration (Python Example)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_S4q9KTdBQujFkXSE5aZYZCrwN9f5QO96BtAFLw4FOgB__slLHW9KFAjmMgC12ag6mf2lJ1rASEvHbP_gv7Jh2Q==",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Key Features:
- OpenAI-Compatible API for seamless integration
- Flexible parameter control for fine-tuning responses
- Streaming support for real-time responses
Option 2: Multi-Agent Workflows with OpenAI Agents SDK Build sophisticated multi-agent systems using GLM-4.5:
- Plug-and-Play Integration: Use GLM-4.5 in any OpenAI Agents workflow
- Advanced Agent Capabilities: Support for handoffs, routing, and tool integration with 90.6% success rate
- Scalable Architecture: Design agents that leverage GLM-4.5’s unified reasoning, coding, and agentic capabilities
Connect with Third-Party Platforms
- Development Tools: Seamlessly integrate with popular IDEs and development environments like Cursor and Cline through OpenAI-compatible APIs
- Orchestration Frameworks: Connect with LangChain, Dify, Langflow, and other AI orchestration platforms using official connectors
- Hugging Face Integration: Use GLM-4.5 in Spaces, pipelines, or with the Transformers library via Novita AI endpoints
🔬 Technical Innovation of GLM-4.5
MoE Architecture Excellence
GLM-4.5 adopts Mixture of Experts (MoE) architecture improving compute efficiency for both training and inference. Compared to DeepSeek-V3, the design reduces width (hidden dimension and routed experts) while increasing height (number of layers).
Key technical features:
- Grouped-Query Attention with partial RoPE (continued from ChatGLM2)
- QK-Norm to stabilize attention logits range
- Muon optimizer for accelerated convergence and larger batch size tolerance
- MTP (Multi-Token Prediction) layer supporting speculative decoding during inference
Advanced Training Pipeline
Pre-training: Two-stage approach
- 15T tokens on general pre-training corpus
- 7T tokens on code & reasoning corpus
Mid-training: Domain-specific optimization
- Repo-Level Code Data (500B tokens)
- Synthetic Reasoning Data (500B tokens)
- Long Context & Agent Data (100B tokens)
Post-training: Sophisticated hybrid approach
- Expert Training: Separate models for Reasoning, Agentic, and General domains through SFT and specialized RL
- Unified Training: Knowledge distillation combining experts into single model via large-scale SFT self-distillation, followed by three-stage RL alignment
slime: Revolutionary RL Infrastructure
GLM-4.5’s training is powered by slime, an open-source RL infrastructure designed for large-scale models:
- Flexible Hybrid Training Architecture: Supports both synchronous co-located training and disaggregated asynchronous training
- Decoupled Agent-Oriented Design: Separates rollout engines from training engines for optimized performance
- Accelerated Data Generation: Mixed-precision inference using FP8 for data generation while maintaining BF16 stability for training
🎯 Ready to Experience Unified AI?
Try GLM-4.5 and GLM-4.5-Air today on the Novita AI Platform. Experience firsthand how unified AI capabilities are transforming what’s possible when reasoning, coding, and agentic functionality converge in optimized, production-ready infrastructure.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



