

- O que é GLM-4.5V e por que é importante para o seu negócio
- Principais Vantagens de Desempenho: Resultados de Ponta em 42 Benchmarks
- Principais Capacidades de Raciocínio Visual
- Primeiros Passos com GLM-4.5V na Plataforma Novita AI
- Casos de Uso para Empresas e Desenvolvedores
- Escolhendo a API de Modelo Certa para Sua Aplicação
- Conclusão
Hoje, temos o prazer de anunciar a parceria da Novita AI com a Zhipu AI para oferecer suporte desde o primeiro dia ao GLM-4.5V na plataforma Novita AI como parceira de lançamento da Zhipu AI.
O GLM-4.5V representa um avanço na tecnologia de IA multimodal, agora disponível na plataforma amigável para desenvolvedores da Novita AI. Este modelo de raciocínio visual de última geração alcança desempenho líder em benchmarks em 42 testes, permanecendo acessível para empresas e desenvolvedores de todos os portes.
O GLM-4.5V cobre tarefas comuns como compreensão de imagens, vídeos e documentos, além de operações de agente GUI. Seja desenvolvendo chatbots de atendimento ao cliente, ferramentas de análise de conteúdo ou soluções de automação, o GLM-4.5V na Novita AI simplifica todo o processo de desenvolvimento.
Preços atuais na Novita AI: US$ 0,6 / M tokens de entrada, US$ 1,8 / M tokens de saída
Experimente o Demo do GLM-4.5V
O que é GLM-4.5V e por que é importante para o seu negócio
O GLM-4.5V é o mais recente modelo multimodal de IA da Zhipu AI, que turbina a base do GLM-4.5 com capacidades abrangentes de raciocínio visual. Construído sobre a robusta arquitetura Mixture of Experts (MoE) de 106B parâmetros baseada no GLM-4.5-Air, este modelo herda técnicas avançadas do GLM-4.1V-Thinking enquanto alcança uma eficiência de escalabilidade sem precedentes.
Como parceira oficial de lançamento da Zhipu AI, a Novita AI oferece às empresas acesso imediato a IA visual de nível empresarial, sem a complexidade de treinar ou manter seus próprios modelos. Em vez de gerenciar múltiplos modelos especializados, você obtém uma solução unificada que lida com tudo, desde reconhecimento básico de imagens até análise complexa de vídeos e processamento de documentos.
Principais Vantagens de Desempenho: Resultados de Ponta em 42 Benchmarks
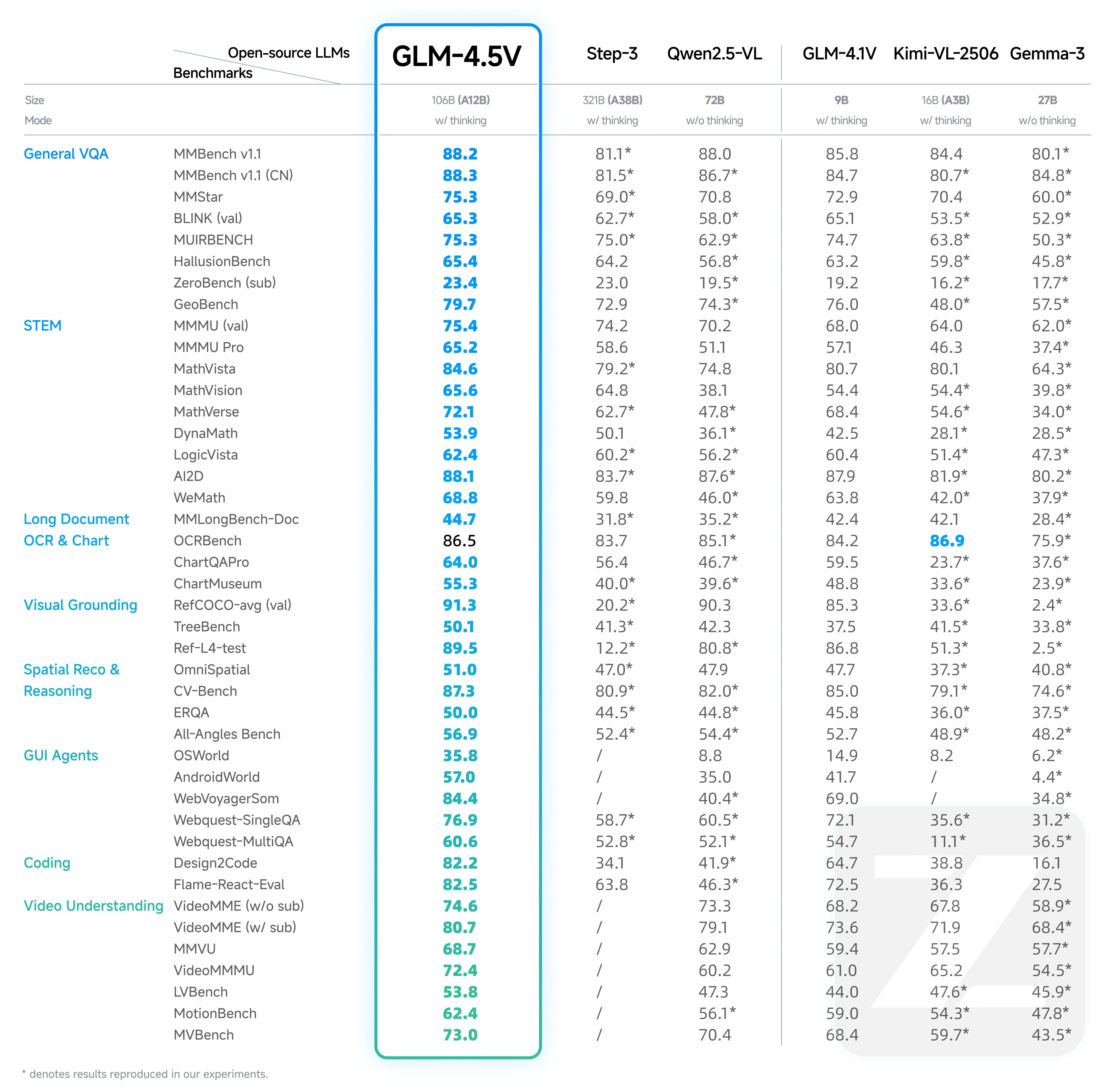
O GLM-4.5V alcança desempenho de última geração entre modelos de código aberto de tamanho comparável, validado em 42 benchmarks abrangentes.
Através de técnicas eficientes de treinamento híbrido, o GLM-4.5V oferece resultados consistentes e confiáveis em diversos tipos de conteúdo visual.
Na infraestrutura otimizada da Novita AI, os desenvolvedores experimentam latência mínima e máxima produtividade, tornando o GLM-4.5V prático para aplicações em produção. O desempenho do modelo se traduz diretamente em melhores experiências do usuário, seja na construção de aplicações voltadas para o cliente ou ferramentas internas de automação.
Principais Capacidades de Raciocínio Visual
O GLM-4.5V oferece cinco capacidades essenciais de raciocínio visual que cobrem praticamente qualquer caso de uso empresarial:
Raciocínio de Imagem: Entenda cenas complexas, analise múltiplas imagens simultaneamente e reconheça localizações geográficas com precisão. Perfeito para análise de produtos em e-commerce, moderação de conteúdo e serviços baseados em localização.
Compreensão de Vídeo: Processe vídeos longos com análise de storyboard e recursos de reconhecimento de eventos. Ideal para criadores de conteúdo, aplicações de segurança e plataformas educacionais que exigem compreensão de vídeo.
Tarefas GUI: Leia telas, reconheça ícones e auxilie em operações de desktop. Essencial para soluções RPA, ferramentas de acessibilidade e estruturas de teste automatizado.
Análise de Gráficos e Documentos: Extraia insights de relatórios de pesquisa, documentos financeiros e visualizações complexas. Crítico para inteligência de negócios, conformidade e fluxos de trabalho de automação de dados.
Capacidade de Grounding: Localize com precisão elementos visuais dentro de imagens ou vídeos. Valioso para controle de qualidade, aplicações de realidade aumentada e implementações de pesquisa visual detalhada.
O modelo também introduz um modo Thinking Mode (Modo de Pensamento), permitindo que os usuários equilibrem respostas rápidas com raciocínio profundo. Essa chave funciona da mesma forma que no modelo de linguagem GLM-4.5.
Primeiros Passos com GLM-4.5V na Plataforma Novita AI
Acessar o GLM-4.5V através da Novita AI oferece múltiplos caminhos adaptados a diferentes níveis de conhecimento técnico e casos de uso. Seja você um usuário empresarial explorando capacidades de IA ou um desenvolvedor construindo aplicações em produção, a Novita AI fornece as ferramentas necessárias.
Use o Playground (Disponível Agora - Sem Necessidade de Codificação)
- Acesso Instantâneo: Cadastre-se e comece a experimentar com os modelos GLM-4.5V em segundos
- Interface Interativa: Teste prompts complexos de raciocínio visual e visualize saídas chain-of-thought em tempo real
- Comparação de Modelos: Compare o GLM-4.5V com outros modelos líderes para seu caso de uso específico
O playground permite que você faça upload de imagens diretamente, teste vários prompts e veja resultados imediatos sem qualquer configuração técnica. Perfeito para prototipagem, teste de ideias e compreensão das capacidades do modelo antes da implementação completa.
Integre via API (Ativa e Pronta - Para Desenvolvedores)
Conecte o GLM-4.5V às suas aplicações com a API REST unificada da Novita AI.
Opção 1: Integração Direta com a API (Exemplo em Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5v"
stream = True # ou False
max_tokens = 65536
system_content = ""Seja um assistente útil""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Olá!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Principais Características:
- API compatível com OpenAI para integração perfeita
- Controle flexível de parâmetros para ajuste fino das respostas
- Suporte a streaming para respostas em tempo real
Opção 2: Fluxos de Trabalho Multiagente com OpenAI Agents SDK
Construa sistemas multiagente sofisticados usando o GLM-4.5V:
- Integração Plug-and-Play: Use o GLM-4.5V em qualquer fluxo de trabalho do OpenAI Agents
- Capacidades Avançadas de Agente: Suporte para handoffs, roteamento e integração de ferramentas com desempenho superior de raciocínio visual
- Arquitetura Escalável: Projete agentes que aproveitem as capacidades unificadas de raciocínio, codificação e análise visual do GLM-4.5V
Conecte-se com Plataformas de Terceiros
Ferramentas de Desenvolvimento: Integre-se perfeitamente com IDEs e ambientes de desenvolvimento populares como Cursor, Trae, Qwen Code e Cline através de APIs compatíveis com OpenAI.
Frameworks de Orquestração: Conecte-se com LangChain, Dify, CrewAI, Langflow e outras plataformas de orquestração de IA usando conectores oficiais.
Integração com Hugging Face: A Novita AI atua como provedor oficial de inferência do Hugging Face, garantindo ampla compatibilidade com o ecossistema.
A Novita AI cuida de toda a infraestrutura, escalabilidade e otimização, permitindo que você se concentre em construir ótimas aplicações com as poderosas capacidades visuais do GLM-4.5V.
Casos de Uso para Empresas e Desenvolvedores
O GLM-4.5V desbloqueia poderosas capacidades de IA visual em diversos cenários de negócios. A versatilidade e precisão do modelo o tornam ideal tanto para aplicações voltadas para o cliente quanto para iniciativas internas de automação.
Compreensão de Imagem
Faça upload de qualquer imagem e receba descrições detalhadas, identificação de objetos e análise contextual com notável profundidade. O GLM-4.5V vai além do reconhecimento básico — ele entende contexto, relações e pode até mesmo se envolver em tarefas criativas como jogos de adivinhação de palavras a partir de pistas visuais.
Empresas aproveitam isso para sistemas de gerenciamento de inventário que categorizam produtos automaticamente, processos de controle de qualidade que detectam defeitos com precisão e marcação automatizada de conteúdo que melhora a busca.
Plataformas de e-commerce usam a compreensão de imagem para gerar descrições de produtos, enquanto criadores de conteúdo automatizam a geração de texto alternativo para acessibilidade e otimização SEO.
Compreensão de Vídeo (Formato MP4 Compatível)
Processe vídeos em MP4 para extrair insights abrangentes, identificar momentos-chave e gerar resumos detalhados. O GLM-4.5V se destaca na análise de conteúdo de vídeo complexo — desde análise de partidas esportivas que identifica jogadas cruciais e avalia desempenho de equipes, até monitoramento de imagens de vigilância que detecta anomalias em tempo real.
Equipes de marketing analisam vídeos de campanhas para medir engajamento e extrair métricas de desempenho, enquanto plataformas educacionais transformam palestras longas em conteúdo pesquisável e indexado.
A capacidade do modelo de entender sequências temporais e eventos o torna inestimável para empresas de mídia que criam compilações de destaques e resumos de conteúdo automaticamente.
Adivinhação Geográfica e Inteligência de Localização
Identifique locais a partir de pistas visuais com impressionante precisão, reconhecendo até mesmo marcos específicos, estilos arquitetônicos e coordenadas geográficas. O GLM-4.5V pode identificar locais exatos a partir de cenas de filmes, identificar cidades a partir de vistas de ruas e até fornecer coordenadas de latitude/longitude.
Aplicações de viagem usam isso para identificação de destinos e planejamento de viagens, plataformas imobiliárias marcam automaticamente propriedades com contexto de localização e amenidades próximas, enquanto empresas de logística verificam locais de entrega e otimizam rotas.
Caçadores de locações de filmes e conselhos de turismo aproveitam essa capacidade para identificar e promover locais de filmagem e atrações turísticas.
Detecção de Objetos e Pesquisa Visual
Identifique e localize com precisão objetos específicos dentro de imagens complexas, até detalhes como números de camisas em imagens esportivas ou peças específicas de mobiliário em design de interiores. O GLM-4.5V não apenas encontra objetos, mas fornece informações contextuais — identificando estilos, sugerindo produtos semelhantes e até recomendando itens complementares.
Plataformas de análise de varejo rastreiam posicionamento de produtos e interações com clientes, linhas de produção garantem a correta montagem, enquanto designers de interiores o usam para criar designs de ambientes coesos.
Replicação de Páginas Web e Análise de UI
Analise e replique interfaces web com alta fidelidade, gerando código HTML e CSS limpo a partir de capturas de tela. O GLM-4.5V entende elementos de UI, estruturas de layout e padrões de design, tornando-o inestimável para prototipagem rápida e análise competitiva.
Equipes de desenvolvimento aceleram a criação de UI convertendo maquetes de design em código, equipes de QA automatizam testes de regressão visual, enquanto pesquisadores de UX analisam interfaces de concorrentes para insights de design.
O modelo se destaca na criação de interfaces responsivas e acessíveis que mantêm a intenção original do design enquanto melhoram a qualidade do código.
Escolhendo a API de Modelo Certa para Sua Aplicação
A Novita AI oferece diferentes APIs de modelos GLM otimizadas para casos de uso específicos. Selecione o endpoint apropriado com base nos requisitos da sua aplicação para maximizar desempenho e custo-benefício.
API GLM-4.5 - Para Tarefas Multimodais Gerais
- Melhor para: Descrições básicas de imagem, Q&A visual simples, análise padrão de documentos
- Use quando: Você precisa de compreensão visual rápida junto com processamento de texto
- Ideal para: Chatbots, moderação de conteúdo e assistentes de IA de uso geral
Para uso cotidiano: Continue usando o GLM-4.5 como de costume — basta fazer upload de qualquer imagem ou vídeo que deseje analisar ou discutir.
API GLM-4.5V - Para Raciocínio Visual Avançado
- Melhor para: Análise complexa de múltiplas imagens, compreensão detalhada de vídeos, localização precisa de objetos
- Use quando: A precisão e o detalhe visual são críticos para sua aplicação
- Ideal para: Imagens médicas, sistemas de vigilância, inspeção de qualidade e análise profissional de vídeo
Para exploração avançada de visão: Escolha o modelo GLM-4.5V para acessar cenários especializados de raciocínio visual e desbloquear todo o potencial de nossas capacidades de visão de ponta.
Conclusão
O GLM-4.5V na Novita AI representa uma mudança de paradigma na forma como empresas e desenvolvedores abordam aplicações de IA visual. Ao combinar desempenho de última geração com uma plataforma acessível e amigável para desenvolvedores, ele elimina as barreiras tradicionais para a implementação avançada de IA.
Seja construindo ferramentas simples de classificação de imagens ou sistemas multimodais complexos, o GLM-4.5V oferece as capacidades e flexibilidade necessárias para o sucesso. As habilidades abrangentes de raciocínio visual do modelo, desde análise de imagem até compreensão de vídeo, possibilitam soluções inovadoras em todos os setores.
Comece a construir com GLM-4.5V na Novita AI hoje e transforme como suas aplicações veem e entendem o mundo visual.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a nuvem GPU confiável e acessível para construir e escalar.



