

- Was ist GLM-4.5V und warum ist es wichtig für Ihr Unternehmen?
- Wichtige Leistungsvorteile: SOTA-Ergebnisse in 42 Benchmarks
- Kernfunktionen für visuelles Reasoning
- Erste Schritte mit GLM-4.5V auf der Novita AI-Plattform
- Anwendungsfälle für Unternehmen und Entwickler
- Das richtige Modell-API für Ihre Anwendung auswählen
- Fazit
Heute freuen wir uns, die Partnerschaft von Novita AI mit Zhipu AI bekannt zu geben, die ab dem ersten Tag Support für GLM-4.5V auf der Novita AI-Plattform als Zhipu AI-Launchpartner bietet.
GLM-4.5V stellt einen Durchbruch in der multimodalen KI-Technologie dar und ist jetzt auf der entwicklerfreundlichen Plattform von Novita AI verfügbar. Dieses hochmoderne visuelle Reasoning-Modell erzielt in 42 Tests Spitzenleistungen und bleibt dabei für Unternehmen und Entwickler jeder Größe zugänglich.
GLM-4.5V deckt gängige Aufgaben wie Bild-, Video- und Dokumentenverständnis sowie GUI-Agent-Operationen ab. Egal, ob Sie Chatbots für den Kundenservice, Content-Analyse-Tools oder Automatisierungslösungen entwickeln – GLM-4.5V auf Novita AI vereinfacht den gesamten Entwicklungsprozess.
Aktuelle Preise auf Novita AI: 0,6 $ / Mio. Input-Token, 1,8 $ / Mio. Output-Token
Was ist GLM-4.5V und warum ist es wichtig für Ihr Unternehmen?
GLM-4.5V ist das neueste multimodale KI-Modell von Zhipu AI, das die GLM-4.5-Basis mit umfassenden visuellen Reasoning-Fähigkeiten ausstattet. Das Modell basiert auf der robusten 106B-Parameter-Mixture-of-Experts (MoE)-Architektur, die auf GLM-4.5-Air aufbaut, und erbt fortschrittliche Techniken von GLM-4.1V-Thinking, während es eine beispiellose Skalierungseffizienz erreicht.
Als offizieller Launchpartner von Zhipu AI bietet Novita AI Unternehmen sofortigen Zugang zu visueller KI auf Unternehmensniveau, ohne die Komplexität des Trainings oder der Wartung eigener Modelle. Anstatt mehrere spezialisierte Modelle zu verwalten, erhalten Sie eine einheitliche Lösung, die alles von der grundlegenden Bilderkennung bis hin zur komplexen Videoanalyse und Dokumentenverarbeitung bewältigt.
Wichtige Leistungsvorteile: SOTA-Ergebnisse in 42 Benchmarks
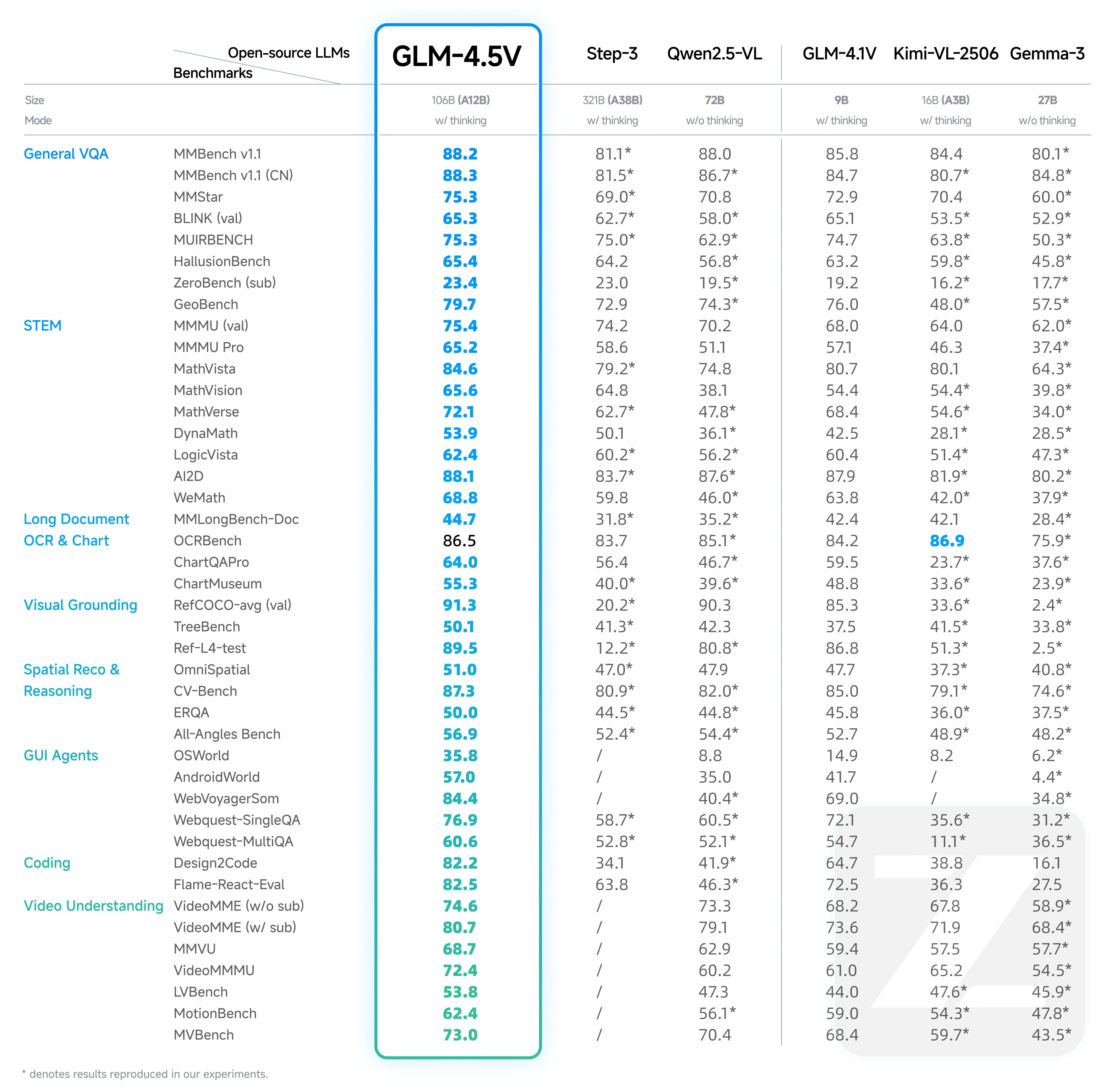
GLM-4.5V erzielt unter Open-Source-Modellen vergleichbarer Größe eine Spitzenleistung (State-of-the-Art), die in 42 umfassenden Benchmarks validiert wurde.
Durch effiziente hybride Trainingstechniken liefert GLM-4.5V konsistente, zuverlässige Ergebnisse für verschiedene Arten von visuellen Inhalten.
Auf der optimierten Infrastruktur von Novita AI erleben Entwickler minimale Latenz und maximalen Durchsatz, was GLM-4.5V für Produktionsanwendungen praktikabel macht. Die Leistung des Modells führt direkt zu besseren Benutzererfahrungen – egal, ob Sie kundenorientierte Anwendungen oder interne Automatisierungstools entwickeln.
Kernfunktionen für visuelles Reasoning
GLM-4.5V bietet fünf wesentliche visuelle Reasoning-Fähigkeiten, die praktisch jeden geschäftlichen Anwendungsfall abdecken:
Bild-Reasoning: Verstehen komplexer Szenen, gleichzeitige Analyse mehrerer Bilder und präzise Erkennung geografischer Standorte. Ideal für E-Commerce-Produktanalysen, Content-Moderation und standortbasierte Dienste.
Video-Verständnis: Verarbeitung langer Videos mit Storyboardanalyse und Ereigniserkennung. Perfekt für Content-Ersteller, Sicherheitsanwendungen und Bildungsplattformen, die ein Video-Verständnis benötigen.
GUI-Aufgaben: Lesen von Bildschirmen, Erkennen von Symbolen und Unterstützung bei Desktop-Operationen. Unverzichtbar für RPA-Lösungen, Barrierefreiheitstools und automatisierte Test-Frameworks.
Diagramm- und Dokumentenanalyse: Gewinnen von Erkenntnissen aus Forschungsberichten, Finanzdokumenten und komplexen Visualisierungen. Entscheidend für Business Intelligence, Compliance und Datenautomatisierungs-Workflows.
Grounding-Fähigkeit: Präzise Lokalisierung von visuellen Elementen in Bildern oder Videos. Wertvoll für Qualitätskontrolle, Augmented-Reality-Anwendungen und detaillierte visuelle Suchimplementierungen.
Das Modell führt außerdem einen Thinking-Mode-Schalter ein, der es den Nutzern ermöglicht, zwischen schnellen Antworten und tiefgehendem Reasoning zu wählen. Dieser Schalter funktioniert genauso wie im GLM-4.5-Sprachmodell.
Erste Schritte mit GLM-4.5V auf der Novita AI-Plattform
Der Zugriff auf GLM-4.5V über Novita AI bietet mehrere Wege, die auf unterschiedliche technische Kenntnisse und Anwendungsfälle zugeschnitten sind. Egal, ob Sie als Geschäftsanwender KI-Fähigkeiten erkunden oder als Entwickler Produktionsanwendungen erstellen – Novita AI bietet die notwendigen Werkzeuge.
Nutzung des Playgrounds (Jetzt verfügbar – Keine Programmierkenntnisse erforderlich)
- Sofortiger Zugriff: Registrieren Sie sich und experimentieren Sie in Sekunden mit GLM-4.5V-Modellen
- Interaktive Oberfläche: Testen Sie komplexe visuelle Reasoning-Prompts und visualisieren Sie Chain-of-Thought-Outputs in Echtzeit
- Modellvergleich: Vergleichen Sie GLM-4.5V mit anderen führenden Modellen für Ihren spezifischen Anwendungsfall
Der Playground ermöglicht es Ihnen, Bilder direkt hochzuladen, verschiedene Prompts zu testen und sofort Ergebnisse zu sehen – ohne technische Einrichtung. Perfekt für das Prototyping, das Testen von Ideen und das Verständnis der Modellfähigkeiten vor der vollständigen Implementierung.
Integration über die API (Live und bereit – Für Entwickler)
Verbinden Sie GLM-4.5V mit Ihren Anwendungen über die einheitliche REST-API von Novita AI.
Option 1: Direkte API-Integration (Python-Beispiel)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 65536
system_content = ""Sei ein hilfsbereiter Assistent""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Hauptfunktionen:
- OpenAI-kompatible API für nahtlose Integration
- Flexible Parametersteuerung zur Feinabstimmung der Antworten
- Streaming-Unterstützung für Echtzeitantworten
Option 2: Multi-Agent-Workflows mit dem OpenAI Agents SDK
Erstellen Sie anspruchsvolle Multi-Agent-Systeme mit GLM-4.5V:
- Plug-and-Play-Integration: Verwenden Sie GLM-4.5V in jedem OpenAI Agents-Workflow
- Erweiterte Agentenfähigkeiten: Unterstützung für Übergaben, Routing und Tool-Integration mit überlegener visueller Reasoning-Leistung
- Skalierbare Architektur: Entwickeln Sie Agenten, die die einheitlichen Reasoning-, Codierungs- und visuellen Analysefähigkeiten von GLM-4.5V nutzen
Verbindung mit Drittanbieter-Plattformen
Entwicklungstools: Nahtlose Integration mit beliebten IDEs und Entwicklungsumgebungen wie Cursor, Trae, Qwen Code und Cline über OpenAI-kompatible APIs.
Orchestrierungs-Frameworks: Verbinden Sie sich mit LangChain, Dify, CrewAI, Langflow und anderen KI-Orchestrierungsplattformen über offizielle Konnektoren.
Hugging Face-Integration: Novita AI fungiert als offizieller Inferenz-Anbieter von Hugging Face und gewährleistet eine breite Ökosystem-Kompatibilität.
Novita AI kümmert sich um die gesamte Infrastruktur, Skalierung und Optimierung, sodass Sie sich auf die Entwicklung großartiger Anwendungen mit den leistungsstarken visuellen Fähigkeiten von GLM-4.5V konzentrieren können.
Anwendungsfälle für Unternehmen und Entwickler
GLM-4.5V erschließt leistungsstarke visuelle KI-Fähigkeiten für verschiedenste geschäftliche Szenarien. Die Vielseitigkeit und Genauigkeit des Modells machen es ideal sowohl für kundenorientierte Anwendungen als auch für interne Automatisierungsinitiativen.
Bildverständnis
Laden Sie ein beliebiges Bild hoch und erhalten Sie detaillierte Beschreibungen, Objektidentifikation und kontextbezogene Analysen mit bemerkenswerter Tiefe. GLM-4.5V geht über die grundlegende Erkennung hinaus – es versteht Kontext, Beziehungen und kann sogar kreative Aufgaben wie Wortratespiele aus visuellen Hinweisen bewältigen.
Unternehmen nutzen dies für Bestandsverwaltungssysteme, die Produkte automatisch kategorisieren, Qualitätskontrollprozesse, die Defekte präzise erkennen, und automatisierte Content-Tagging, das die Auffindbarkeit verbessert.
E-Commerce-Plattformen nutzen das Bildverständnis zur Generierung von Produktbeschreibungen, während Content-Ersteller die Erstellung von Alt-Texten für Barrierefreiheit und SEO-Optimierung automatisieren.
Video-Verständnis (MP4-Format unterstützt)
Verarbeiten Sie MP4-Videos, um umfassende Erkenntnisse zu gewinnen, Schlüsselmomente zu identifizieren und detaillierte Zusammenfassungen zu erstellen. GLM-4.5V zeichnet sich durch die Analyse komplexer Videoinhalte aus – von der Sportmatch-Analyse, die entscheidende Spielzüge identifiziert und die Teamleistung bewertet, bis hin zur Überwachung von Überwachungsmaterial, das Anomalien in Echtzeit erkennt.
Marketingteams analysieren Kampagnenvideos, um das Engagement zu messen und Leistungskennzahlen zu extrahieren, während Bildungsplattformen lange Vorlesungen in durchsuchbare, indexierte Inhalte umwandeln.
Die Fähigkeit des Modells, zeitliche Abläufe und Ereignisse zu verstehen, macht es für Medienunternehmen unverzichtbar, die automatisch Highlight-Reels und Inhaltszusammenfassungen erstellen.
Geografie-Raten und Standortinformationen
Identifizieren Sie Standorte anhand visueller Hinweise mit beeindruckender Genauigkeit, einschließlich der Erkennung bestimmter Wahrzeichen, Architekturstile und geografischer Koordinaten. GLM-4.5V kann genaue Orte aus Filmszenen bestimmen, Städte anhand von Straßenansichten identifizieren und sogar Breiten-/Längengradkoordinaten liefern.
Reiseanwendungen nutzen dies zur Zielidentifikation und Reiseplanung, Immobilienplattformen taggen Immobilien automatisch mit Standortkontext und nahegelegenen Annehmlichkeiten, während Logistikunternehmen Lieferorte überprüfen und Routen optimieren.
Filmstandortscouts und Tourismusverbände nutzen diese Fähigkeit, um Drehorte und Touristenattraktionen zu identifizieren und zu bewerben.
Objekterkennung und visuelle Suche
Identifizieren und lokalisieren Sie präzise bestimmte Objekte in komplexen Bildern, bis hin zu Details wie Trikotnummern in Sportaufnahmen oder bestimmten Möbelstücken in Inneneinrichtungen. GLM-4.5V findet nicht nur Objekte, sondern liefert kontextbezogene Informationen – identifiziert Stile, schlägt ähnliche Produkte vor und empfiehlt sogar ergänzende Artikel.
Einzelhandelsanalyseplattformen verfolgen Produktplatzierungen und Kundeninteraktionen, Fertigungslinien stellen die korrekte Montage sicher, während Innenarchitekten es verwenden, um stimmige Raumgestaltungen zu erstellen.
Webseiten-Replikation und UI-Analyse
Analysieren und replizieren Sie Weboberflächen mit hoher Genauigkeit und generieren Sie sauberen HTML- und CSS-Code aus Screenshots. GLM-4.5V versteht UI-Elemente, Layoutstrukturen und Designmuster, was es für schnelles Prototyping und Wettbewerbsanalysen unverzichtbar macht.
Entwicklungsteams beschleunigen die UI-Erstellung, indem sie Design-Mockups in Code umwandeln, QA-Teams automatisieren visuelle Regressionstests, während UX-Forscher Konkurrenzoberflächen auf Design-Erkenntnisse analysieren.
Das Modell zeichnet sich durch die Erstellung responsiver, barrierefreier Oberflächen aus, die die ursprüngliche Designabsicht beibehalten und gleichzeitig die Codequalität verbessern.
Das richtige Modell-API für Ihre Anwendung auswählen
Novita AI bietet verschiedene GLM-Modell-APIs, die für spezifische Anwendungsfälle optimiert sind. Wählen Sie den geeigneten Endpunkt basierend auf Ihren Anwendungsanforderungen, um Leistung und Kosteneffizienz zu maximieren.
GLM-4.5-API – Für allgemeine multimodale Aufgaben
- Am besten geeignet für: Einfache Bildbeschreibungen, einfache visuelle Frage-Antwort-Stellungen, standardmäßige Dokumentenanalyse
- Verwenden Sie, wenn: Sie schnelles visuelles Verständnis zusammen mit Textverarbeitung benötigen
- Ideal für: Chatbots, Content-Moderation und allgemeine KI-Assistenten
Für den täglichen Gebrauch: Verwenden Sie GLM-4.5 wie gewohnt – laden Sie einfach ein beliebiges Bild oder Video hoch, das Sie analysieren oder besprechen möchten.
GLM-4.5V-API – Für fortgeschrittenes visuelles Reasoning
- Am besten geeignet für: Komplexe Mehrbildanalysen, detailliertes Videoverständnis, präzise Objektlokalisierung
- Verwenden Sie, wenn: Visuelle Genauigkeit und Detailtreue für Ihre Anwendung entscheidend sind
- Ideal für: Medizinische Bildgebung, Überwachungssysteme, Qualitätsprüfung und professionelle Videoanalyse
Für fortgeschrittene visuelle Erkundung: Wählen Sie das GLM-4.5V-Modell, um auf spezialisierte visuelle Reasoning-Szenarien zuzugreifen und das volle Potenzial unserer hochmodernen visuellen Fähigkeiten zu erschließen.
Fazit
GLM-4.5V auf Novita AI stellt einen Paradigmenwechsel dar, wie Unternehmen und Entwickler visuelle KI-Anwendungen angehen. Durch die Kombination modernster Leistung mit einer zugänglichen, entwicklerfreundlichen Plattform werden traditionelle Barrieren für die Implementierung fortschrittlicher KI beseitigt.
Egal, ob Sie einfache Bildklassifizierungstools oder komplexe multimodale Systeme entwickeln – GLM-4.5V bietet die Fähigkeiten und Flexibilität, die für den Erfolg erforderlich sind. Die umfassenden visuellen Reasoning-Fähigkeiten des Modells, von der Bildanalyse bis zum Videoverständnis, ermöglichen innovative Lösungen in jeder Branche.
Starten Sie noch heute mit GLM-4.5V auf Novita AI und verwandeln Sie die Art und Weise, wie Ihre Anwendungen die visuelle Welt sehen und verstehen.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für den Aufbau und die Skalierung bereitstellt.



