

Réclamez 10 $ et essayez le modèle gratuit
L’IA dans l’éducation transforme rapidement la manière dont les élèves apprennent, les enseignants instruisent et les institutions personnalisent les expériences d’apprentissage.
Comme ces solutions fonctionnent de plus en plus sur des appareils locaux comme les ordinateurs portables, tablettes et même téléphones mobiles, il y a un besoin croissant de petits modèles légers mais capables — en particulier ceux d’environ 8 milliards de paramètres.
Dans cet article, nous comparons deux options de premier plan dans ce domaine : Qwen 3 8B et LLaMA 3.1 8B. Nous explorerons leurs forces et faiblesses en matière de raisonnement, de support multilingue, de vitesse de déploiement et de pertinence pratique pour les applications éducatives.
Qwen 3 8B vs Llama 3.1 8B : Introduction de base
| Critère | Qwen 3 8B | LLaMA 3.1 8B |
|---|---|---|
| Taille du modèle | ~8,2B paramètres | ~8B paramètres |
| Architecture | GQA | GQA |
| Support linguistique | 100+ langues, fort support du chinois | 8 langues (anglais, espagnol, français, allemand, etc.) |
| Support multimodal | Texte uniquement (pas de support direct pour l’image/audio) | Texte uniquement (pas de support direct pour l’image/audio) |
| Longueur du contexte | 128k | 128k |
| Données d’entraînement | Distillé par Qwen 3 32B (contient des données RL) | Pré-entraîné sur ~15 billions de tokens provenant de sources publiques. |
Une innovation clé de Qwen3 est l’intégration de modes « pensée » et « non-pensée » au sein d’un seul modèle. Par ailleurs, il convient de noter que grâce à ses compétences solides en utilisation d’outils, Qwen3 peut agir multimodal en appelant des API externes.
Qwen 3 8B vs Llama 3.1 8B : Benchmark
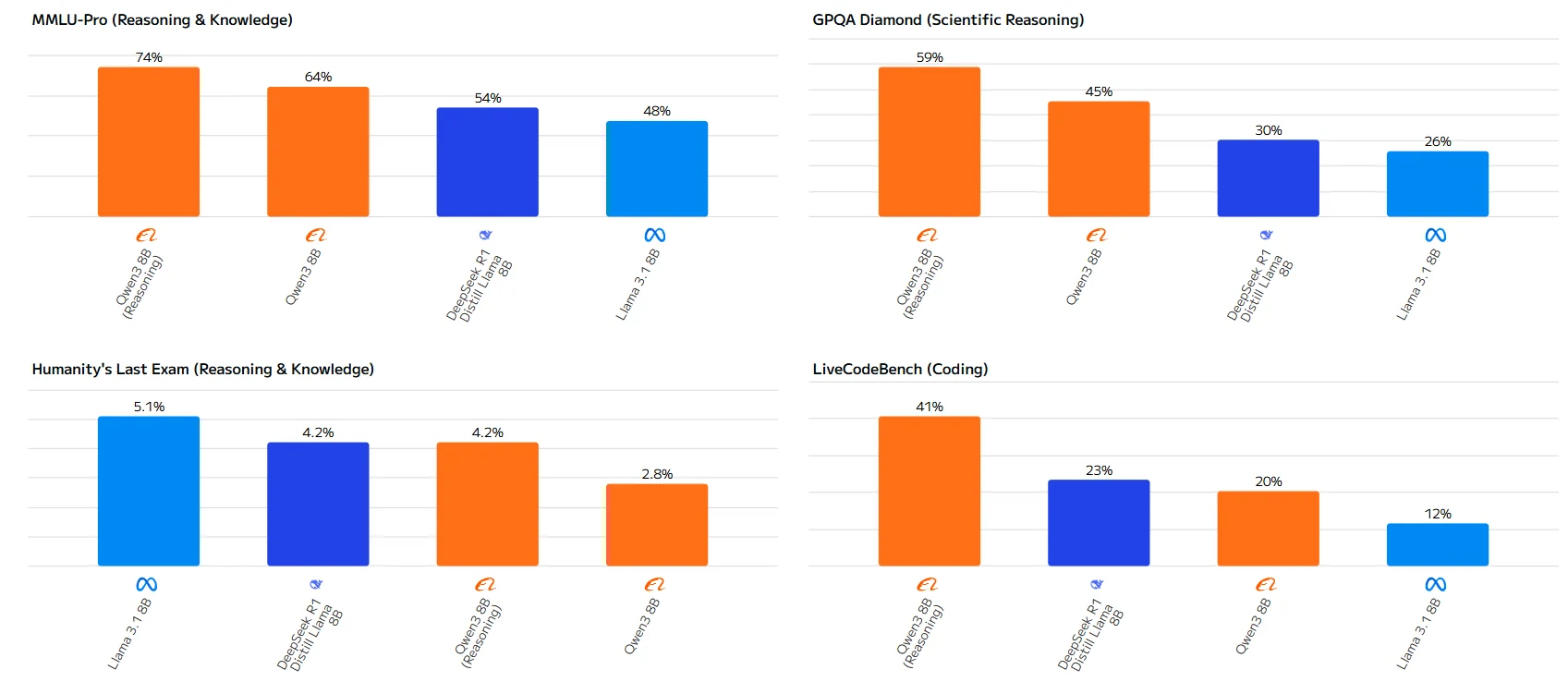
Source : Artificial Analysis
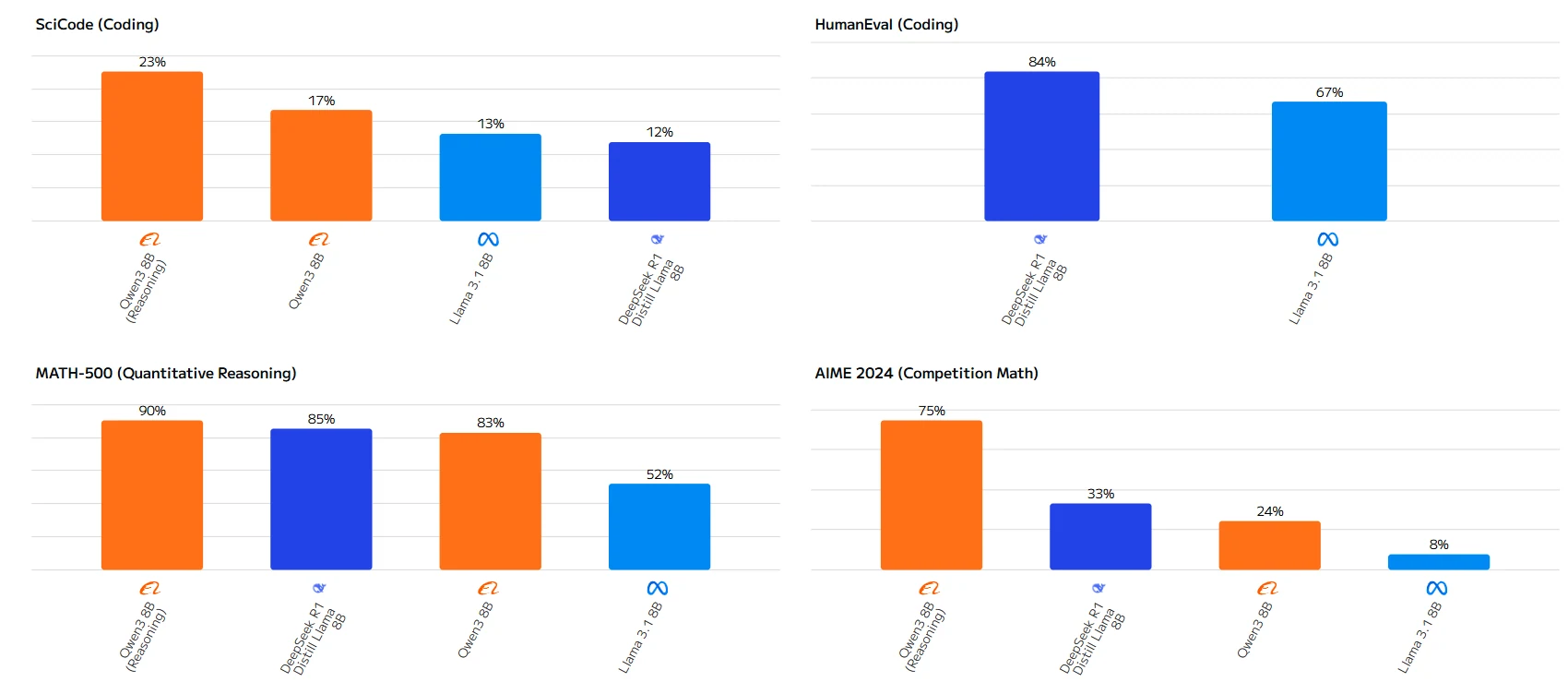
Source : Artificial Analysis
L’écart de performance est particulièrement notable dans les tâches mathématiques, où Qwen-3 8B surpasse Llama 3.1 8B avec une large marge. Alors que Llama 3.1 8B devance légèrement dans Humanity’s Last Exam, Qwen-3 8B démontre des capacités supérieures dans la plupart des applications pratiques.
Qwen 3 8B vs Llama 3.1 8B : Exigences matérielles
| Précision | Taille du modèle Qwen3-8B | Taille du modèle LLaMA 3.1–8B |
|---|---|---|
| FP32 (flottants 32 bits) | ≈ 33 GB (8,2B × 4 bytes) | ≈ 32 GB (8,0B × 4 bytes) |
| FP16/BF16 (16 bits) | ≈ 16,4 GB (8,2B × 2 bytes) | ≈ 16 GB (8,0B × 2 bytes) |
| INT8 (quantifié sur 8 bits) | ≈ 8,2 GB (8,2B × 1 byte) | ≈ 8,0 GB (8,0B × 1 byte) |
| INT4 (quantifié sur 4 bits) | ≈ 4,1 GB (8,2B × 0,5 byte) | ≈ 4,0 GB (8,0B × 0,5 byte) |
- Entre les deux, il n’y a pas de différence majeure en termes de besoins matériels – ils sont de la même catégorie. Si quelque chose, le mode pensée de Qwen3-8B pourrait ralentir un peu l’inférence lorsqu’il génère un raisonnement verbeux, mais vous pouvez le désactiver pour gagner en vitesse si nécessaire.
Qwen 3 8B vs Llama 3.1 8B : Vitesse
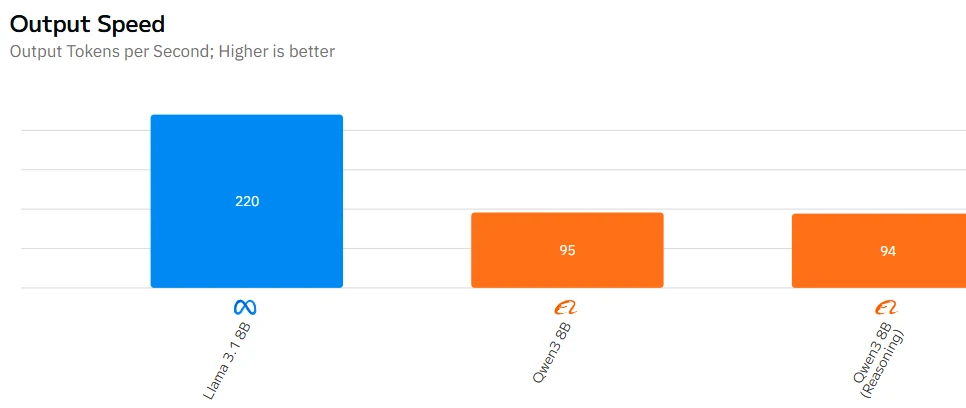
Source : Artificial Analysis
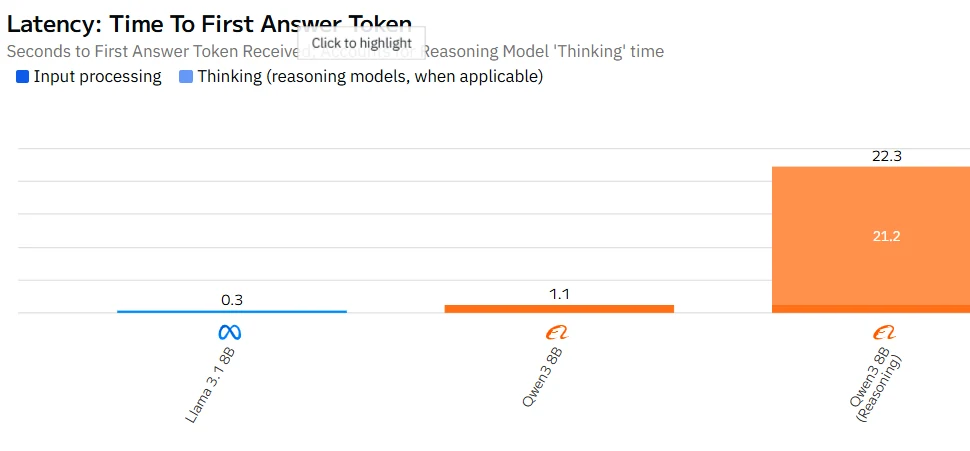
Source : Artificial Analysis
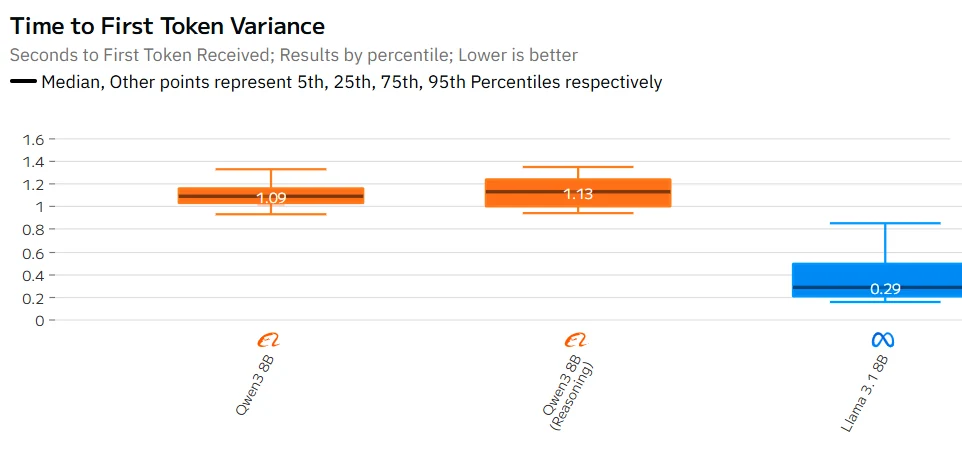
Source : Artificial Analysis
Qwen 3 8B vs Llama 3.1 8B : Meilleur choix pour l’IA dans l’éducation
| Fonctionnalité | Qwen 3 8B | LLaMA 3.1 8B |
|---|---|---|
| Capacité de raisonnement | ✅ Raisonnement avancé par chaîne de pensée utilisant les tokens thinking |
⚠️ Profondeur de raisonnement limitée |
| Tâches mathématiques et logiques | ✅ Forte performance dans les benchmarks | ❌ Plus faible dans la résolution de problèmes complexes |
| Explications pas à pas | ✅ Oui, grâce au « mode pensée » | ⚠️ Réponses moins structurées |
| Support linguistique | ✅ 100+ langues (dont un fort support du chinois) | ❌ Seulement 8 langues |
| Intégration d’outils | ✅ Peut appeler des API externes pour des fonctionnalités étendues | ❌ Aucune capacité d’utilisation d’outils |
| Vitesse | ⚠️ Légèrement plus lent à cause du mode pensée | ✅ Inférence plus rapide |
Une autre façon d’accélérer Qwen 3 8B : essayez Novita API
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Commencez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Essayez Qwen 3 8B maintenant !
Étape 4 : Obtenez votre clé API
Pour vous authentifier avec l’API, nous vous fournirons une nouvelle clé API. En entrant dans la page « Paramètres », vous pouvez copier la clé API comme indiqué dans l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Ceci est un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen3-8b-fp8"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Pour les applications éducatives, les tâches de raisonnement et les environnements multilingues, Qwen 3 8B est le modèle supérieur. Bien que LLaMA 3.1 8B soit légèrement plus rapide, il manque de la profondeur et de la flexibilité qu’offre Qwen. Pour améliorer la vitesse et la facilité de déploiement de Qwen, utiliser la Novita API est une solution pratique et conviviale pour les développeurs.
Questions fréquemment posées
Est-ce que Qwen 3 8B est plus lent que LLaMA 3.1 8B ?
Légèrement, à cause de son mode raisonnement — mais cela peut être désactivé pour une inférence plus rapide.
Qu’est-ce qui rend Qwen 3 8B meilleur pour l’éducation ?
Il fournit des explications structurées, de meilleures performances en mathématiques et un support multilingue.
Comment déployer facilement Qwen 3 8B ?
Utilisez Novita API pour une intégration rapide, une sélection flexible de modèles et une option d’essai gratuit.
*Novita AI *est une plateforme cloud d’IA qui offre aux développeurs un moyen facile de déployer des modèles d’IA en utilisant notre API simple, tout en fournissant également le cloud GPU abordable et fiable pour construire et passer à l’échelle.



