

AI in education is rapidly transforming how students learn, teachers instruct, and institutions personalize learning experiences.
As these solutions increasingly run on local devices like laptops, tablets, and even mobile phones, there’s a rising need for lightweight yet capable small models—especially those around 8 billion parameters.
In this article, we compare two leading options in this space: Qwen 3 8B and LLaMA 3.1 8B. We’ll explore their strengths and weaknesses in reasoning, multilingual support, deployment speed, and practical suitability for educational applications.
Qwen 3 8B vs Llama 3.1 8B: Basic Introduction
| Criterion | Qwen 3 8B | LLaMA 3.1 8B |
|---|---|---|
| Model Size | ~8.2B parameters | ~8B parameters |
| Architecture | GQA | GQA |
| Language Support | 100+ languages, strong Chinese support | 8 languages (English, Spanish, French, German, etc.) |
| Multimodal Support | Text-only (no direct image/audio support) | Text-only (no direct image/audio support) |
| Context Length | 128k | 128k |
| Training Data | Distilled by Qwen 3 32B(contains RL datas) | Pretrained on ~15 trillion tokens from publicly available sources. |
A key innovation of Qwen3 is the integration of both “thinking” and “non-thinking” modes within a single model. Meanwhile, it’s worth noting that because Qwen3 has strong tool-use skills, it can act multimodal by calling external APIs.
Qwen 3 8B vs Llama 3.1 8B: Benchmark
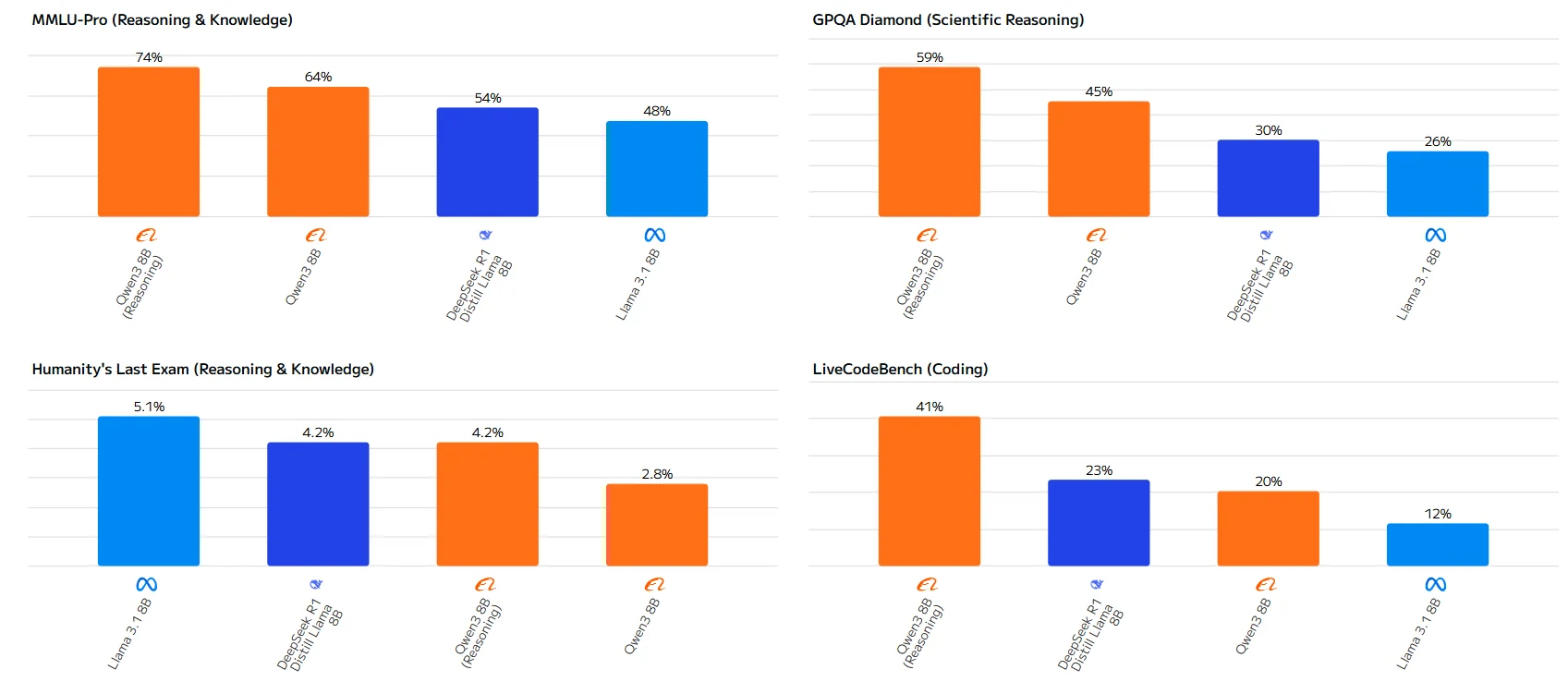
Fron Artificial Analysis
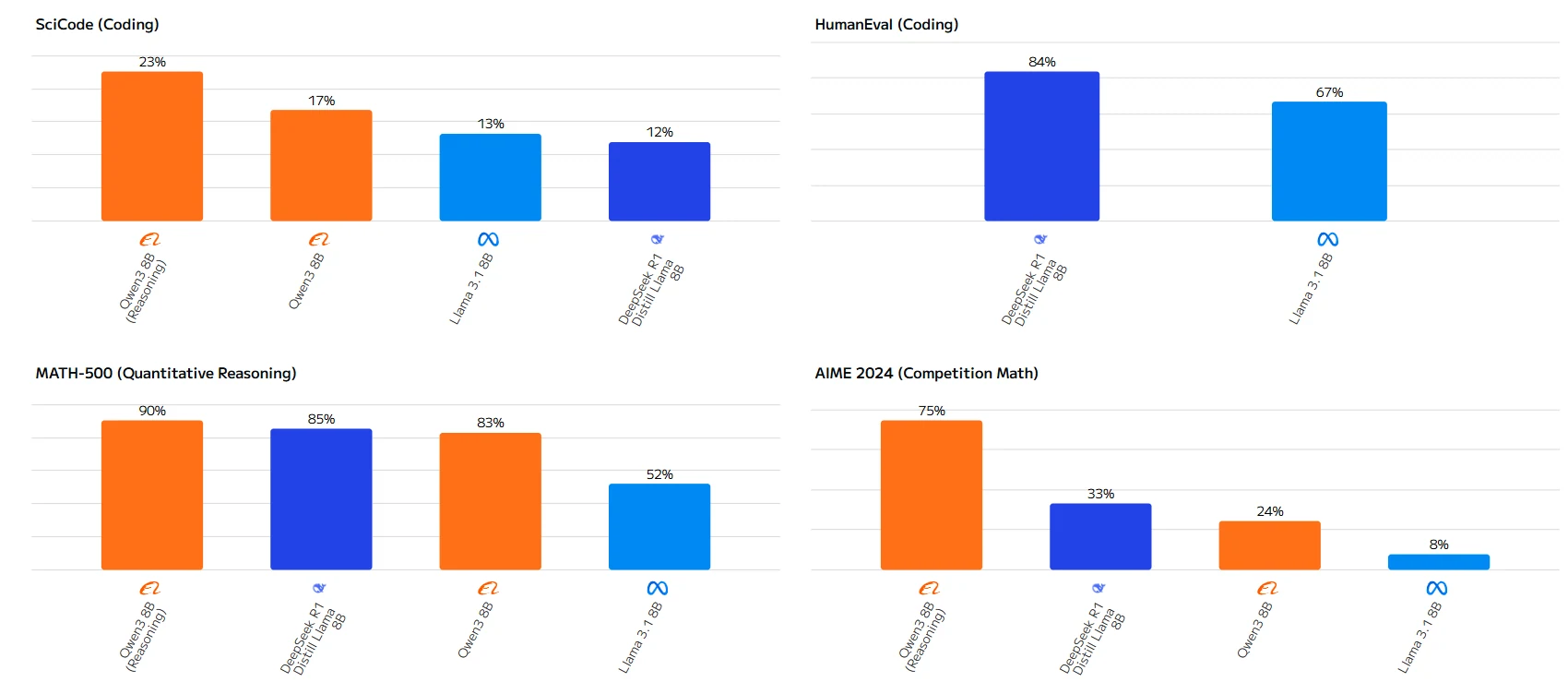
Fron Artificial Analysis
The performance gap is especially notable in mathematical tasks, where Qwen-3 8B outperforms Llama 3.1 8B by large margins. While Llama 3.1 8B slightly edges out in Humanity’s Last Exam, Qwen-3 8B demonstrates superior capabilities in most practical applications.
Qwen 3 8B vs Llama 3.1 8B: Hardware Requirements
| Precision | Qwen3-8B Model Size | LLaMA 3.1–8B Model Size |
|---|---|---|
| FP32 (32-bit floats) | ≈ 33 GB (8.2B × 4 bytes) | ≈ 32 GB (8.0B × 4 bytes) |
| FP16/BF16 (16-bit) | ≈ 16.4 GB (8.2B × 2 bytes) | ≈ 16 GB (8.0B × 2 bytes) |
| INT8 (8-bit quantized) | ≈ 8.2 GB (8.2B × 1 byte) | ≈ 8.0 GB (8.0B × 1 byte) |
| INT4 (4-bit quantized) | ≈ 4.1 GB (8.2B × 0.5 byte) | ≈ 4.0 GB (8.0B × 0.5 byte) |
- Between the two, there’s no major difference in hardware requirements – they are of the same class. If anything, Qwen3-8B’s thinking mode might slow down inference a bit when it’s generating verbose reasoning, but you can disable that for speed if needed.
Qwen 3 8B vs Llama 3.1 8B: Speed
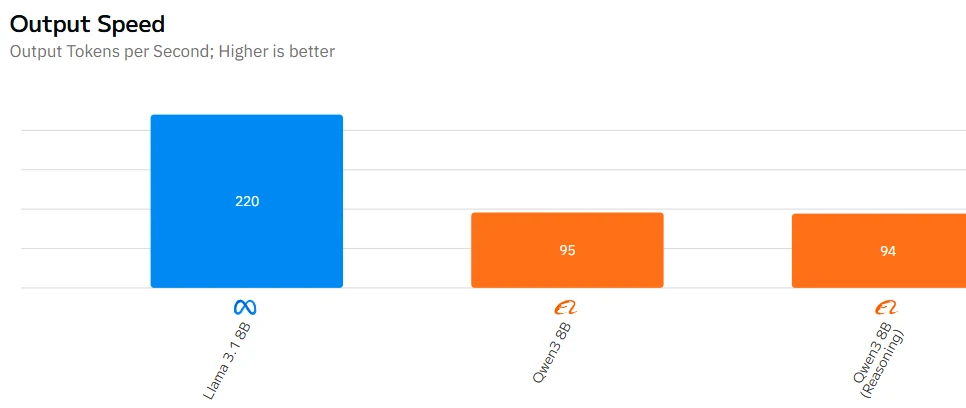
Fron Artificial Analysis
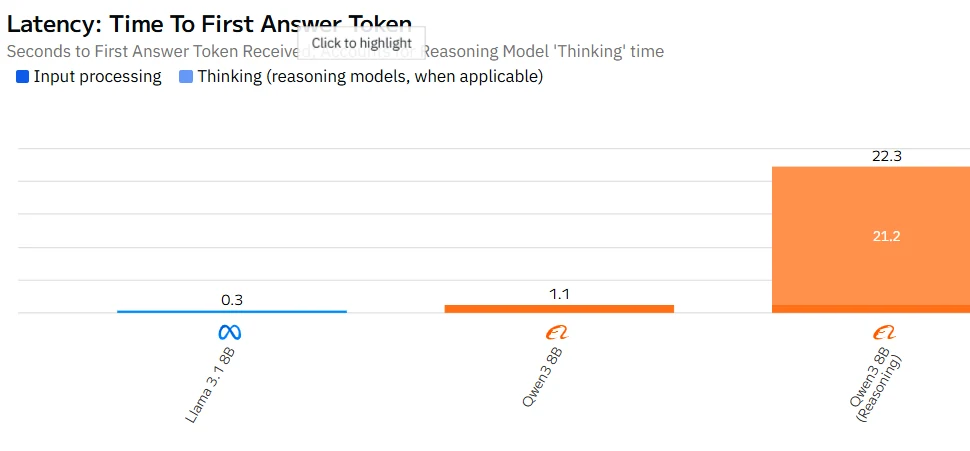
Fron Artificial Analysis
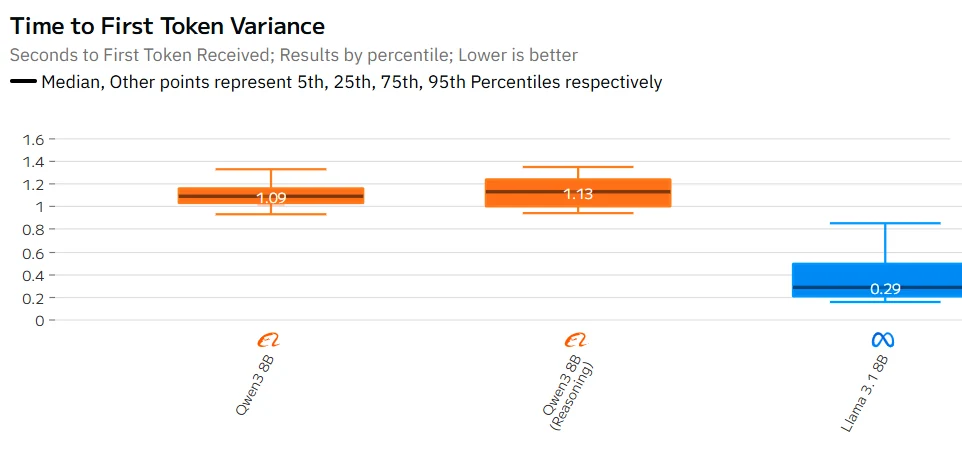
Fron Artificial Analysis
Qwen 3 8B vs Llama 3.1 8B: Best Pick for AI in education
| Feature | Qwen 3 8B | LLaMA 3.1 8B |
|---|---|---|
| Reasoning Ability | ✅ Advanced chain-of-thought reasoning using <think> tokens | ⚠️ Limited reasoning depth |
| Math & Logic Tasks | ✅ Strong performance in benchmarks | ❌ Weaker in complex problem-solving |
| Step-by-Step Explanations | ✅ Yes, due to “thinking mode” | ⚠️ Less structured answers |
| Language Support | ✅ 100+ languages (including strong Chinese) | ❌ Only 8 languages |
| Tool Integration | ✅ Can call external APIs for extended functionality | ❌ No tool-use capabilities |
| Speed | ⚠️ Slightly slower due to thinking mode | ✅ Faster inference |
Another Way to Speed Up Qwen 3 8B: Try Novita API
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen3-8b-fp8"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
For educational applications, reasoning tasks, and multilingual environments, Qwen 3 8B is the superior model. Although LLaMA 3.1 8B is slightly faster, it lacks the depth and flexibility Qwen provides. To boost Qwen’s speed and ease of deployment, using the Novita API is a practical and developer-friendly solution.
Frequently Asked Questions
Is Qwen 3 8B slower than LLaMA 3.1 8B?
Slightly, due to its reasoning mode—but this can be turned off for faster inference.
What makes Qwen 3 8B better for education?
It provides structured explanations, better math performance, and multilingual support.
How can I deploy Qwen 3 8B easily?
Use Novita API for fast integration, flexible model selection, and a free trial option.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



