

- Qwen 3 8B vs Llama 3.1 8B: Grundlegende Einführung
- Qwen 3 8B vs Llama 3.1 8B: Benchmarks
- Qwen 3 8B vs Llama 3.1 8B: Hardware-Anforderungen
- Qwen 3 8B vs Llama 3.1 8B: Geschwindigkeit
- Qwen 3 8B vs Llama 3.1 8B: Beste Wahl für KI in der Bildung
- Eine weitere Möglichkeit, Qwen 3 8B zu beschleunigen: Novita API ausprobieren
Fordern Sie 10 $ an und testen Sie das kostenlose Modell
KI in der Bildung verändert rasant, wie Schüler lernen, Lehrer unterrichten und Einrichtungen Lernerfahrungen personalisieren.
Da diese Lösungen zunehmend auf lokalen Geräten wie Laptops, Tablets und sogar Mobiltelefonen laufen, steigt der Bedarf an leichtgewichtigen und dennoch leistungsfähigen kleinen Modellen – insbesondere solchen mit etwa 8 Milliarden Parametern.
In diesem Artikel vergleichen wir zwei führende Optionen in diesem Bereich: Qwen 3 8B und LLaMA 3.1 8B. Wir untersuchen ihre Stärken und Schwächen in den Bereichen Reasoning, Mehrsprachigkeit, Bereitstellungsgeschwindigkeit und praktische Eignung für Bildungsanwendungen.
Qwen 3 8B vs Llama 3.1 8B: Grundlegende Einführung
| Kriterium | Qwen 3 8B | LLaMA 3.1 8B |
|---|---|---|
| Modellgröße | ~8,2 Milliarden Parameter | ~8 Milliarden Parameter |
| Architektur | GQA | GQA |
| Sprachunterstützung | 100+ Sprachen, starke Chinesisch-Unterstützung | 8 Sprachen (Englisch, Spanisch, Französisch, Deutsch usw.) |
| Multimodale Unterstützung | Nur Text (keine direkte Bild-/Audio-Unterstützung) | Nur Text (keine direkte Bild-/Audio-Unterstützung) |
| Kontextlänge | 128k | 128k |
| Trainingsdaten | Destilliert aus Qwen 3 32B (enthält RL-Daten) | Vorab trainiert auf ~15 Billionen Tokens aus öffentlich zugänglichen Quellen. |
Eine Schlüsselinnovation von Qwen3 ist die Integration sowohl eines „Denk“- als auch eines „Nicht-Denk“-Modus in einem einzigen Modell. Es ist außerdem erwähnenswert, dass Qwen3 durch seine starken Fähigkeiten zur Werkzeugnutzung multimodal agieren kann, indem es externe APIs aufruft.
Qwen 3 8B vs Llama 3.1 8B: Benchmarks
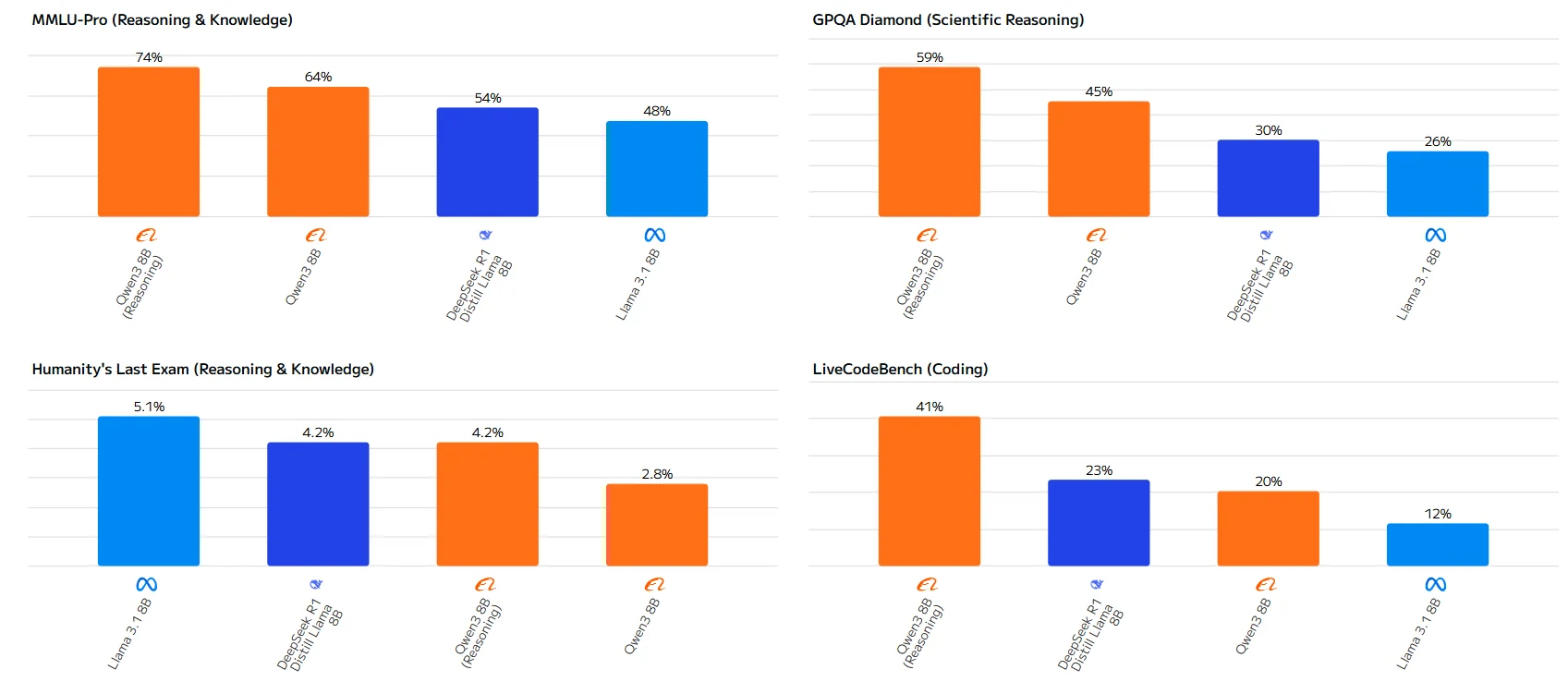
Quelle: Artificial Analysis
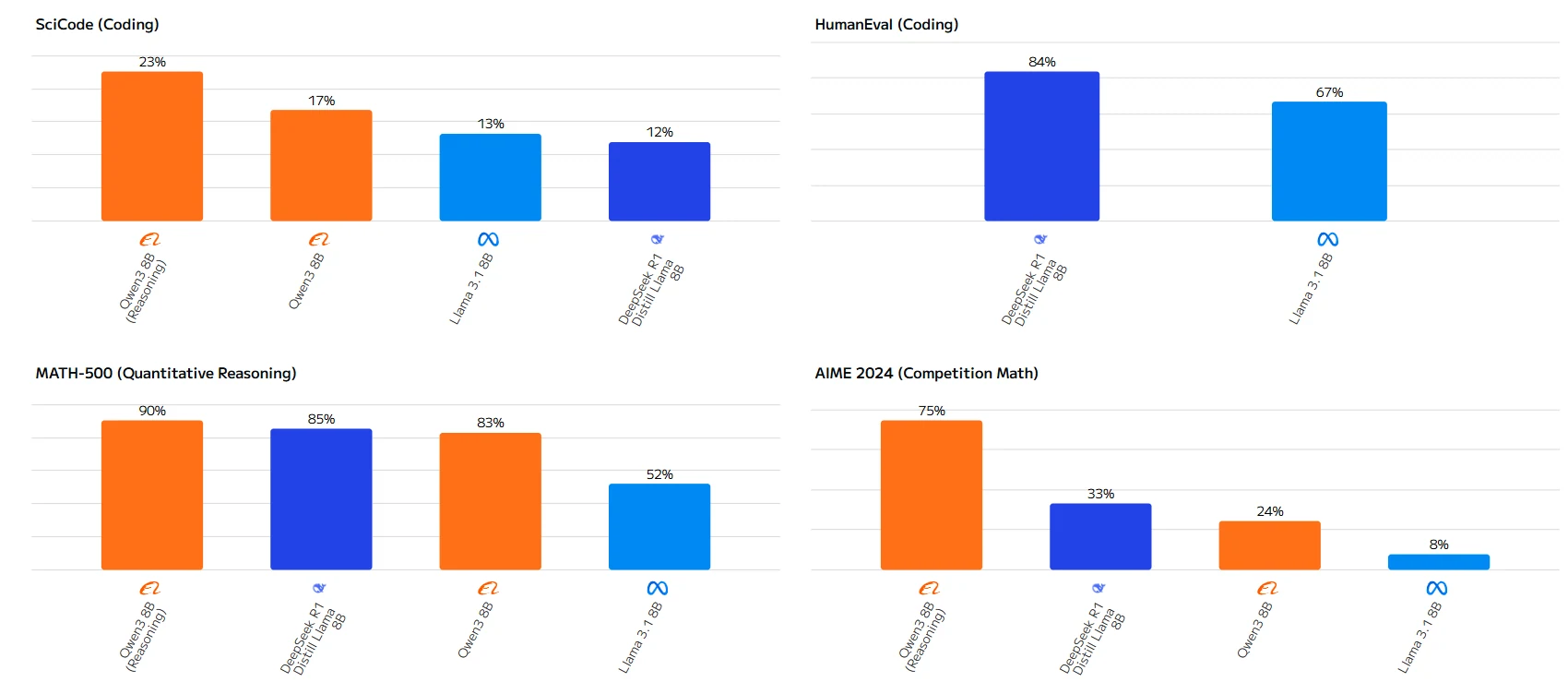
Quelle: Artificial Analysis
Der Leistungsunterschied ist besonders bei mathematischen Aufgaben deutlich, wo Qwen-3 8B Llama 3.1 8B mit großem Abstand übertrifft. Während Llama 3.1 8B bei „Humanity‘s Last Exam“ leicht die Nase vorn hat, zeigt Qwen-3 8B in den meisten praktischen Anwendungen überlegene Fähigkeiten.
Qwen 3 8B vs Llama 3.1 8B: Hardware-Anforderungen
| Präzision | Qwen3-8B Modellgröße | LLaMA 3.1–8B Modellgröße |
|---|---|---|
| FP32 (32-Bit-Gleitkommazahlen) | ≈ 33 GB (8,2B × 4 Bytes) | ≈ 32 GB (8,0B × 4 Bytes) |
| FP16/BF16 (16-Bit) | ≈ 16,4 GB (8,2B × 2 Bytes) | ≈ 16 GB (8,0B × 2 Bytes) |
| INT8 (8-Bit quantisiert) | ≈ 8,2 GB (8,2B × 1 Byte) | ≈ 8,0 GB (8,0B × 1 Byte) |
| INT4 (4-Bit quantisiert) | ≈ 4,1 GB (8,2B × 0,5 Byte) | ≈ 4,0 GB (8,0B × 0,5 Byte) |
- Zwischen beiden gibt es keine großen Unterschiede bei den Hardware-Anforderungen – sie sind derselben Klasse. Falls überhaupt, könnte der Denkmodus von Qwen3-8B die Inferenz etwas verlangsamen, da er ausführliche Überlegungen erzeugt, aber dieser Modus kann bei Bedarf für mehr Geschwindigkeit deaktiviert werden.
Qwen 3 8B vs Llama 3.1 8B: Geschwindigkeit
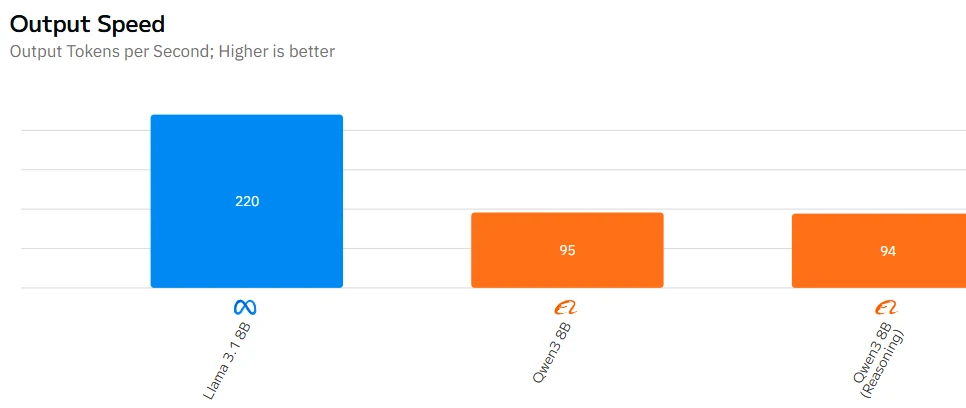
Quelle: Artificial Analysis
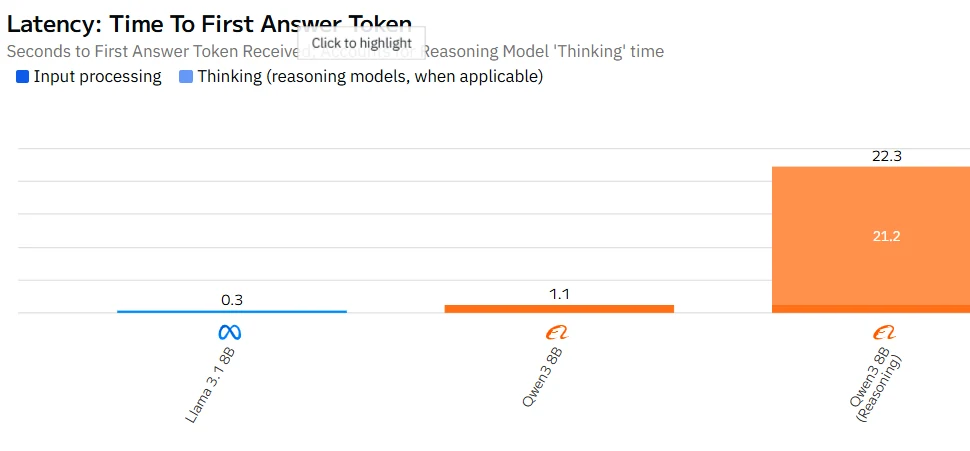
Quelle: Artificial Analysis
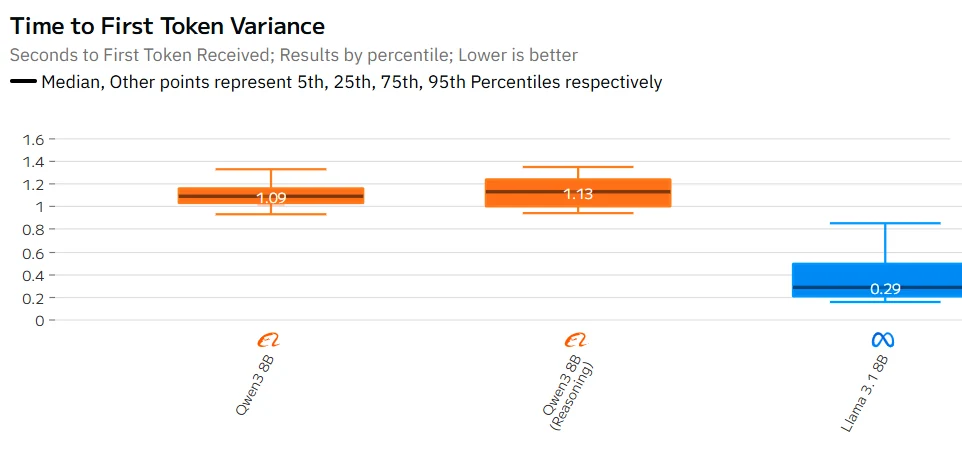
Quelle: Artificial Analysis
Qwen 3 8B vs Llama 3.1 8B: Beste Wahl für KI in der Bildung
| Merkmal | Qwen 3 8B | LLaMA 3.1 8B |
|---|---|---|
| Reasoning-Fähigkeit | ✅ Fortschrittliches Ketten-Denken mit thinking-Tokens |
⚠️ Begrenzte Reasoning-Tiefe |
| Mathematik- & Logikaufgaben | ✅ Starke Leistung in Benchmarks | ❌ Schwächer bei komplexer Problemlösung |
| Schritt-für-Schritt-Erklärungen | ✅ Ja, dank „Denkmodus“ | ⚠️ Weniger strukturierte Antworten |
| Sprachunterstützung | ✅ 100+ Sprachen (inklusive starkem Chinesisch) | ❌ Nur 8 Sprachen |
| Tool-Integration | ✅ Kann externe APIs für erweiterte Funktionen aufrufen | ❌ Keine Tool-Nutzung |
| Geschwindigkeit | ⚠️ Etwas langsamer durch Denkmodus | ✅ Schnellere Inferenz |
Eine weitere Möglichkeit, Qwen 3 8B zu beschleunigen: Novita API ausprobieren
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek .

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Rufen Sie die Seite „Einstellungen“ auf und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<IHR Novita AI API-Schlüssel>",
)
model = "qwen/qwen3-8b-fp8"
stream = True # or False
max_tokens = 2048
system_content = """Sei ein hilfreicher Assistent"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Für Bildungsanwendungen, Reasoning-Aufgaben und mehrsprachige Umgebungen ist Qwen 3 8B das überlegene Modell. Obwohl LLaMA 3.1 8B etwas schneller ist, fehlt ihm die Tiefe und Flexibilität, die Qwen bietet. Um die Geschwindigkeit von Qwen zu steigern und die Bereitstellung zu vereinfachen, ist die Verwendung der Novita API eine praktische und entwicklerfreundliche Lösung.
Häufig gestellte Fragen
Ist Qwen 3 8B langsamer als LLaMA 3.1 8B?
Etwas, aufgrund seines Reasoning-Modus – dieser kann jedoch für schnellere Inferenz deaktiviert werden.
Was macht Qwen 3 8B besser für die Bildung geeignet?
Es liefert strukturierte Erklärungen, bessere Mathematikleistungen und mehrsprachige Unterstützung.
Wie kann ich Qwen 3 8B einfach bereitstellen?
Verwenden Sie die Novita API für schnelle Integration, flexible Modellauswahl und eine kostenlose Testoption.
*Novita AI[ ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.]



