

احصل على 10 دولارات وجرب النموذج مجاناً
الذكاء الاصطناعي في التعليم يُحدث تحولاً سريعاً في كيفية تعلم الطلاب، وتدريس المعلمين، وتخصيص المؤسسات لتجارب التعلم.
ومع تشغيل هذه الحلول بشكل متزايد على الأجهزة المحلية مثل أجهزة الكمبيوتر المحمولة والأجهزة اللوحية وحتى الهواتف المحمولة، تبرز الحاجة إلى نماذج صغيرة خفيفة الوزن لكنها قادرة – خاصة تلك التي تحتوي على حوالي 8 مليارات معامل.
في هذه المقالة، نقارن بين خيارين رائدين في هذا المجال: Qwen 3 8B وLLaMA 3.1 8B. سنستكشف نقاط القوة والضعف لكل منهما في الاستدلال، ودعم اللغات المتعددة، وسرعة النشر، والملاءمة العملية للتطبيقات التعليمية.
Qwen 3 8B مقابل Llama 3.1 8B: مقدمة أساسية
| المعيار | Qwen 3 8B | LLaMA 3.1 8B |
|---|---|---|
| حجم النموذج | حوالي 8.2 مليار معامل | حوالي 8 مليار معامل |
| الهندسة المعمارية | GQA | GQA |
| دعم اللغات | أكثر من 100 لغة، دعم قوي للصينية | 8 لغات (الإنجليزية، الإسبانية، الفرنسية، الألمانية، إلخ.) |
| دعم الوسائط المتعددة | نص فقط (لا يدعم الصور/الصوت مباشرة) | نص فقط (لا يدعم الصور/الصوت مباشرة) |
| طول السياق | 128k | 128k |
| بيانات التدريب | تم تقطيره من Qwen 3 32B (يحتوي على بيانات التعلم المعزز) | تم تدريبه مسبقاً على حوالي 15 تريليون رمز من مصادر متاحة للعموم. |
الابتكار الرئيسي في Qwen3 هو دمج وضعي “التفكير” و"عدم التفكير" داخل نموذج واحد. وفي الوقت نفسه، تجدر الإشارة إلى أنه نظراً لمهارات Qwen3 القوية في استخدام الأدوات، يمكنه العمل كوسائط متعددة عن طريق استدعاء واجهات برمجة التطبيقات الخارجية.
Qwen 3 8B مقابل Llama 3.1 8B: المعايير
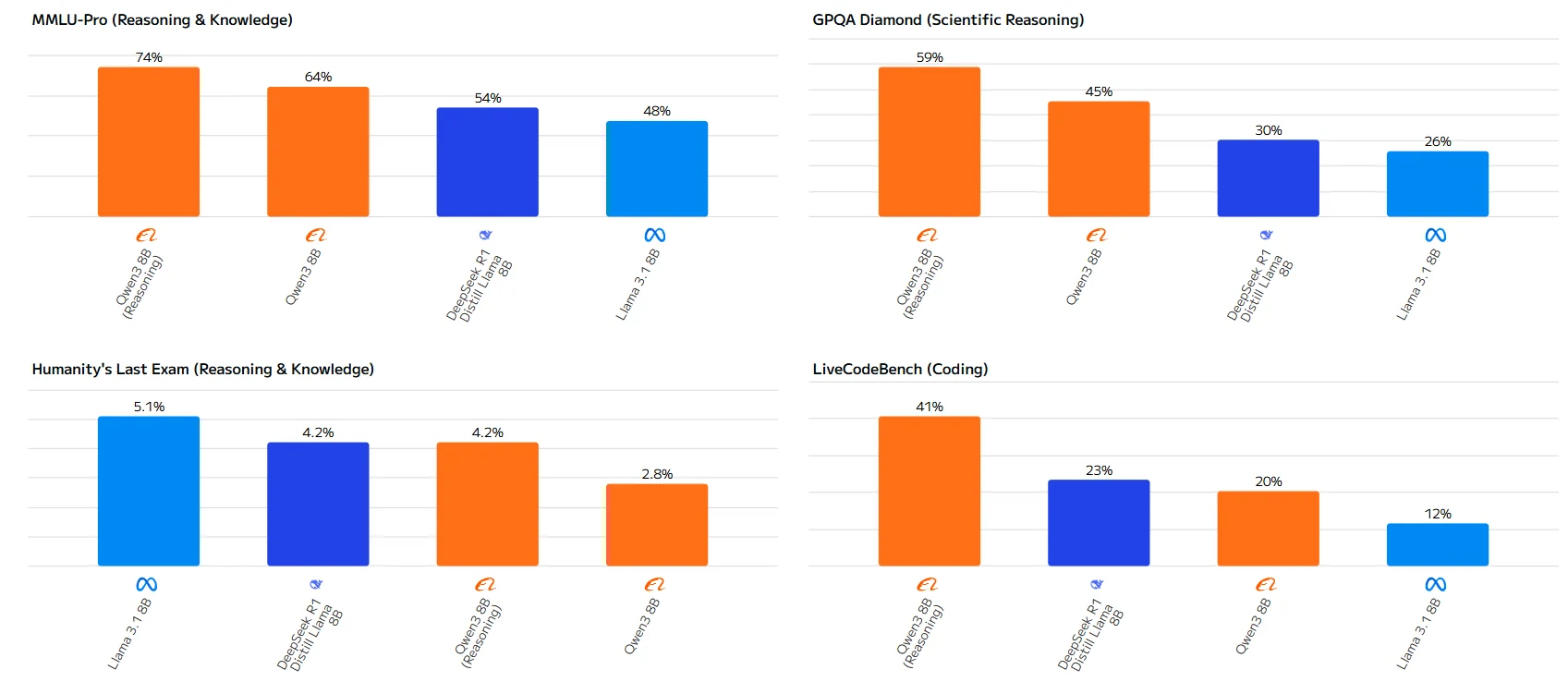
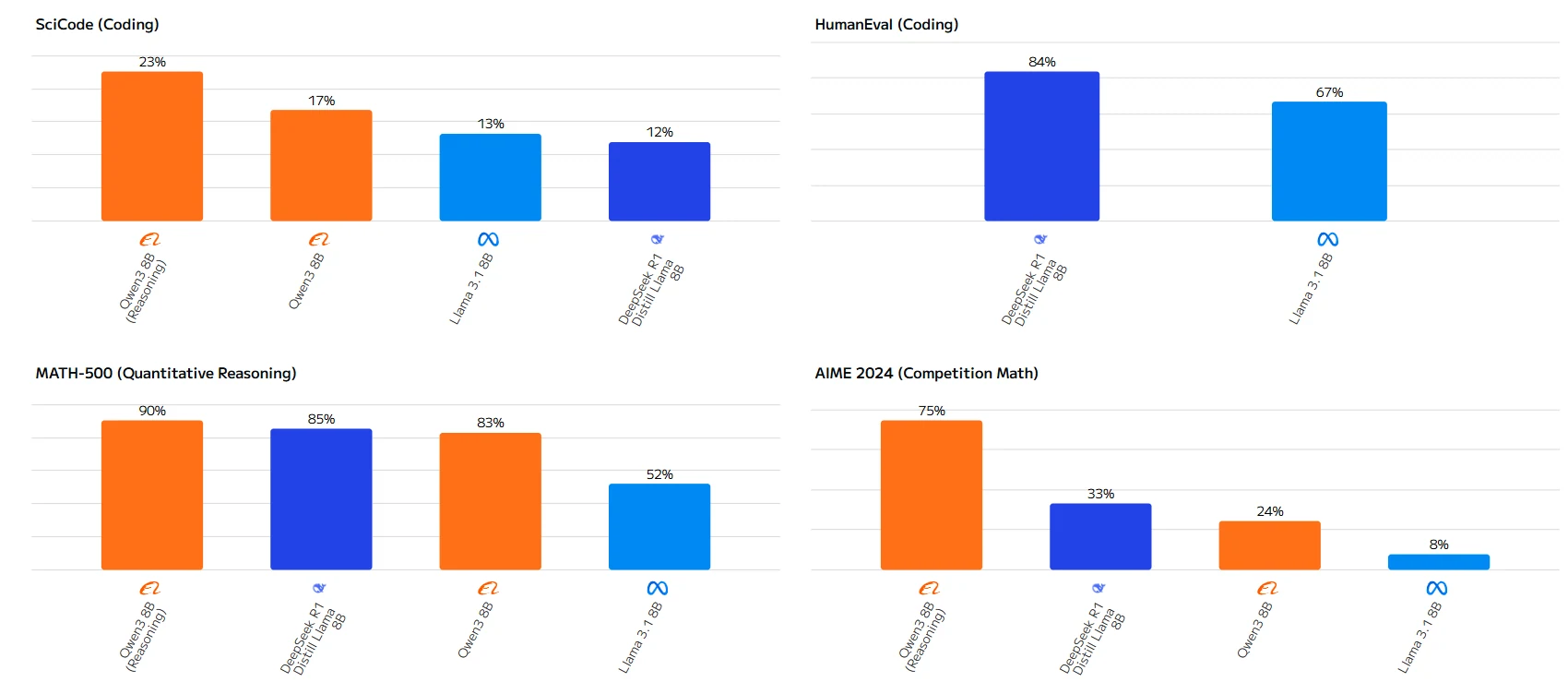
الفجوة في الأداء ملحوظة بشكل خاص في المهام الرياضية، حيث يتفوق Qwen-3 8B على Llama 3.1 8B بهامش كبير. بينما يتفوق Llama 3.1 8B بشكل طفيف في امتحان Humanity’s Last Exam، يُظهر Qwen-3 8B قدرات فائقة في معظم التطبيقات العملية.
Qwen 3 8B مقابل Llama 3.1 8B: متطلبات الأجهزة
| الدقة | حجم نموذج Qwen3-8B | حجم نموذج LLaMA 3.1–8B |
|---|---|---|
| FP32 (32-bit floats) | ≈ 33 جيجابايت (8.2B × 4 بايت) | ≈ 32 جيجابايت (8.0B × 4 بايت) |
| FP16/BF16 (16-bit) | ≈ 16.4 جيجابايت (8.2B × 2 بايت) | ≈ 16 جيجابايت (8.0B × 2 بايت) |
| INT8 (8-bit quantized) | ≈ 8.2 جيجابايت (8.2B × 1 بايت) | ≈ 8.0 جيجابايت (8.0B × 1 بايت) |
| INT4 (4-bit quantized) | ≈ 4.1 جيجابايت (8.2B × 0.5 بايت) | ≈ 4.0 جيجابايت (8.0B × 0.5 بايت) |
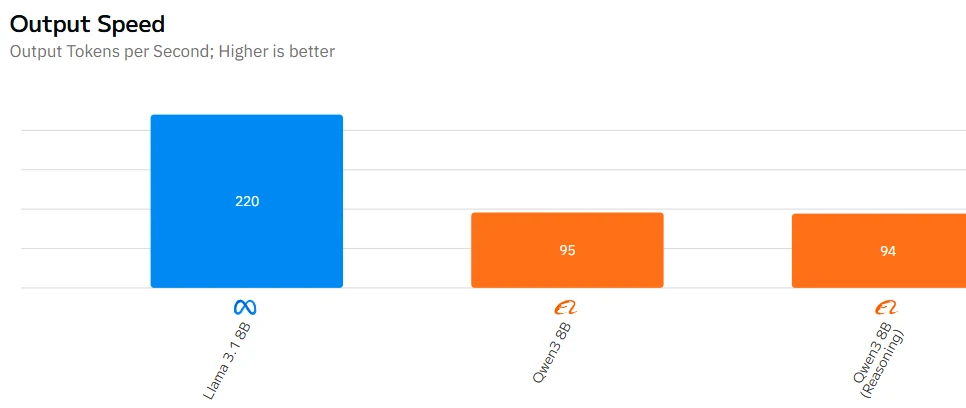
- لا يوجد فرق كبير في متطلبات الأجهزة بين الاثنين – فهما من نفس الفئة. وإذا كان هناك شيء، فإن وضع التفكير في Qwen3-8B قد يبطئ الاستدلال قليلاً عند توليد استدلال مطول، ولكن يمكنك تعطيل ذلك من أجل السرعة إذا لزم الأمر.
Qwen 3 8B مقابل Llama 3.1 8B: السرعة
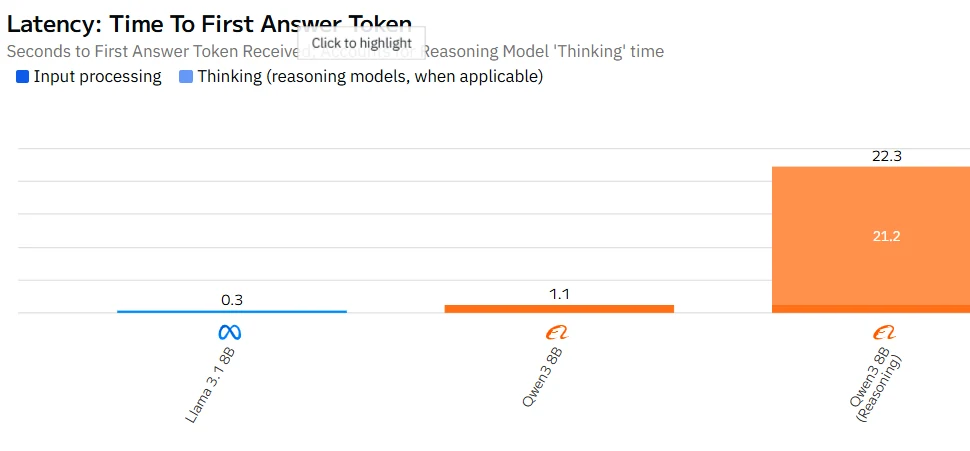
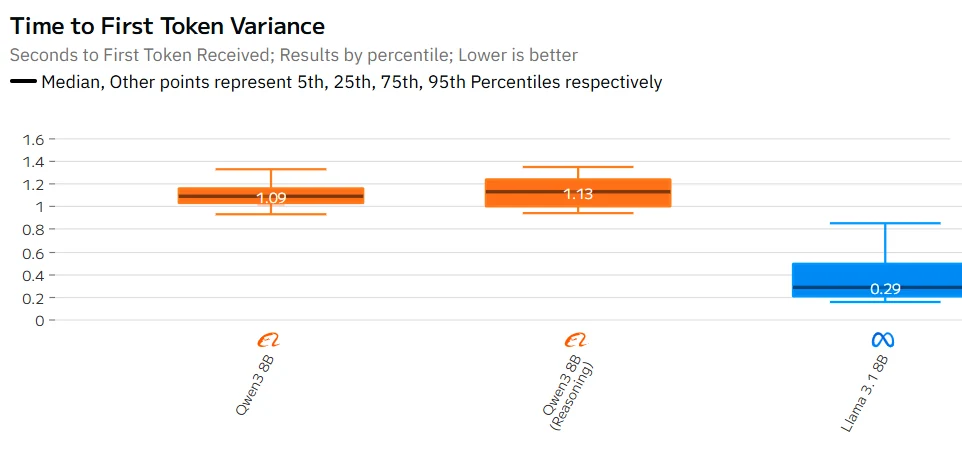
Qwen 3 8B مقابل Llama 3.1 8B: الخيار الأفضل للذكاء الاصطناعي في التعليم
| الميزة | Qwen 3 8B | LLaMA 3.1 8B |
|---|---|---|
| القدرة على الاستدلال | ✅ استدلال متقدم بسلسلة الأفكار باستخدام رموز thinking |
⚠️ عمق استدلال محدود |
| المهام الرياضية والمنطقية | ✅ أداء قوي في المعايير | ❌ أضعف في حل المشكلات المعقدة |
| الشروح خطوة بخطوة | ✅ نعم، بفضل “وضع التفكير” | ⚠️ إجابات أقل تنظيماً |
| دعم اللغات | ✅ أكثر من 100 لغة (بما في ذلك الصينية القوية) | ❌ 8 لغات فقط |
| تكامل الأدوات | ✅ يمكنه استدعاء واجهات برمجة تطبيقات خارجية لوظائف موسعة | ❌ لا توجد قدرات استخدام أدوات |
| السرعة | ⚠️ أبطأ قليلاً بسبب وضع التفكير | ✅ استدلال أسرع |
طريقة أخرى لتسريع Qwen 3 8B: جرب Novita API
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ النسخة التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف قدرات النموذج المختار.
الخطوة 4: احصل على مفتاح API الخاص بك
للتحقق من الهوية مع API، سنزودك بمفتاح API جديد. بالدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة الخاصة بك.
بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير لديك. قم بتهيئة API باستخدام مفتاح API الخاص بك للبدء في التفاعل مع Novita AI LLM. هذا مثال على استخدام واجهة برمجة تطبيقات إكمال المحادثة لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen3-8b-fp8"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
للتطبيقات التعليمية ومهام الاستدلال والبيئات متعددة اللغات، يعتبر Qwen 3 8B النموذج المتفوق. على الرغم من أن LLaMA 3.1 8B أسرع قليلاً، إلا أنه يفتقر إلى العمق والمرونة التي يوفرها Qwen. لتعزيز سرعة وسهولة نشر Qwen، فإن استخدام Novita API يعد حلاً عملياً وصديقاً للمطورين.
الأسئلة الشائعة
هل Qwen 3 8B أبطأ من LLaMA 3.1 8B؟
بشكل طفيف، بسبب وضع الاستدلال – ولكن يمكن إيقاف تشغيل ذلك للحصول على استدلال أسرع.
ما الذي يجعل Qwen 3 8B أفضل للتعليم؟
يقدم شروحاً منظمة، وأداء أفضل في الرياضيات، ودعم متعدد اللغات.
كيف يمكنني نشر Qwen 3 8B بسهولة؟
استخدم Novita API للتكامل السريع، واختيار النماذج المرن، وخيار النسخة التجريبية المجانية.
Novita AI هي منصة سحابية للذكاء الاصطناعي توفر للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة لدينا، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.



