

- Qwen 3 8B vs Llama 3.1 8B: Introducción básica
- Qwen 3 8B vs Llama 3.1 8B: Comparativa de rendimiento
- Qwen 3 8B vs Llama 3.1 8B: Requisitos de hardware
- Qwen 3 8B vs Llama 3.1 8B: Velocidad
- Qwen 3 8B vs Llama 3.1 8B: La mejor opción para la IA en educación
- Otra forma de acelerar Qwen 3 8B: Prueba Novita API
Reclama $10 y Prueba un Modelo Gratis
La IA en la educación está transformando rápidamente la forma en que los estudiantes aprenden, los profesores enseñan y las instituciones personalizan las experiencias de aprendizaje.
A medida que estas soluciones se ejecutan cada vez más en dispositivos locales como portátiles, tablets e incluso teléfonos móviles, surge una necesidad creciente de modelos pequeños pero potentes—especialmente aquellos de alrededor de 8 mil millones de parámetros.
En este artículo, comparamos dos opciones líderes en este espacio: Qwen 3 8B y LLaMA 3.1 8B. Exploraremos sus fortalezas y debilidades en razonamiento, soporte multilingüe, velocidad de despliegue y adecuación práctica para aplicaciones educativas.
Qwen 3 8B vs Llama 3.1 8B: Introducción básica
| Criterio | Qwen 3 8B | LLaMA 3.1 8B |
|---|---|---|
| Tamaño del modelo | ~8.2B parámetros | ~8B parámetros |
| Arquitectura | GQA | GQA |
| Soporte de idiomas | 100+ idiomas, fuerte soporte para chino | 8 idiomas (inglés, español, francés, alemán, etc.) |
| Soporte multimodal | Solo texto (sin soporte directo de imagen/audio) | Solo texto (sin soporte directo de imagen/audio) |
| Longitud de contexto | 128k | 128k |
| Datos de entrenamiento | Destilado por Qwen 3 32B (incluye datos de RL) | Preentrenado con ~15 billones de tokens de fuentes públicas. |
Una innovación clave de Qwen3 es la integración de modos de “pensamiento” y “no pensamiento” dentro de un mismo modelo. Además, cabe destacar que gracias a sus habilidades de uso de herramientas, Qwen3 puede actuar de forma multimodal llamando a APIs externas.
Qwen 3 8B vs Llama 3.1 8B: Comparativa de rendimiento
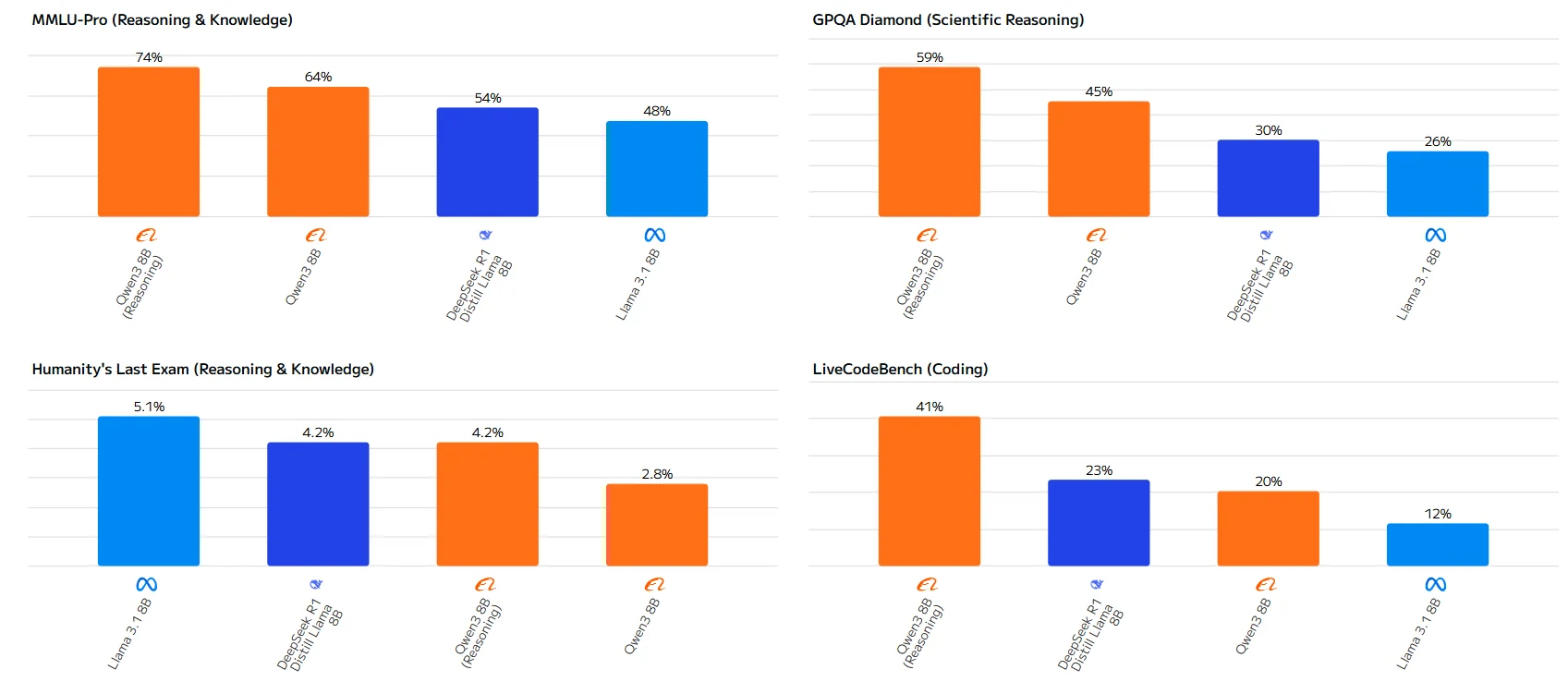
Fuente: Artificial Analysis
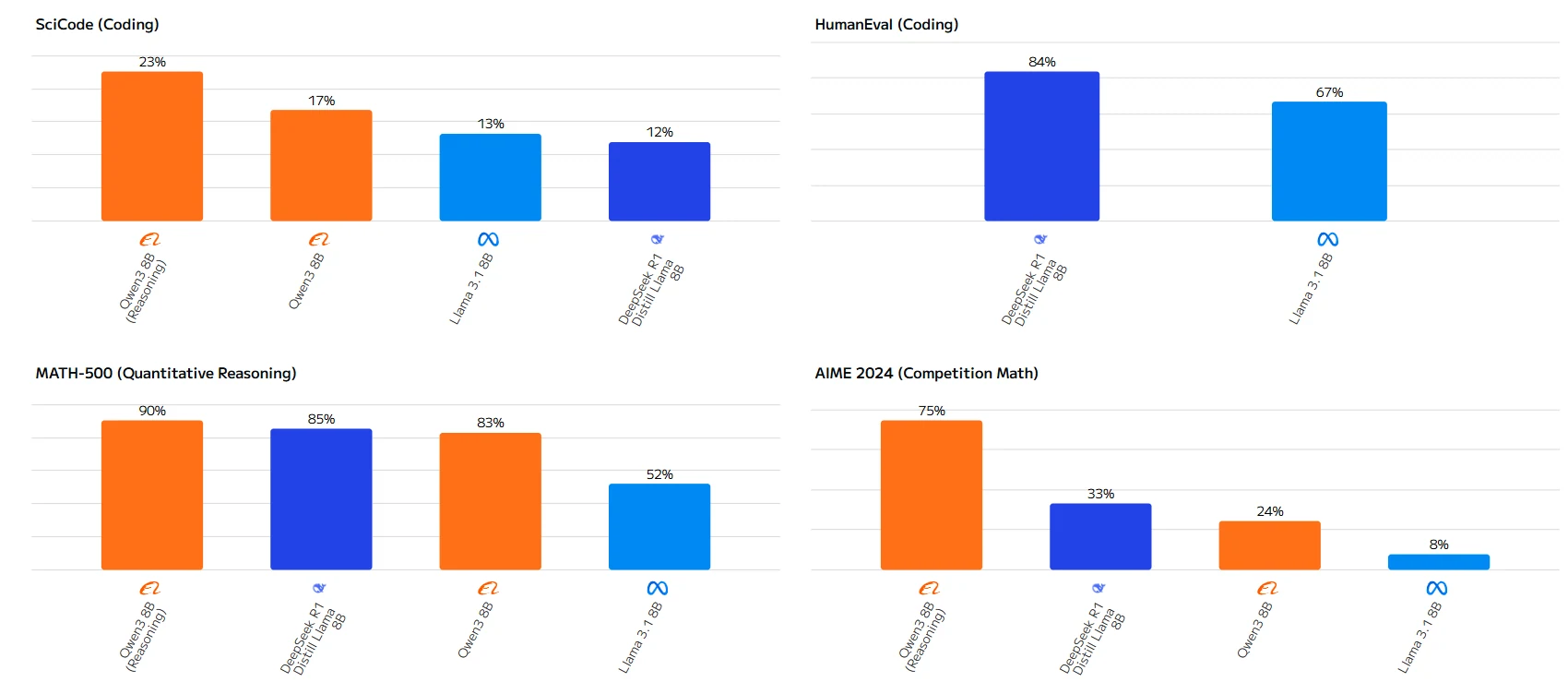
Fuente: Artificial Analysis
La brecha de rendimiento es especialmente notable en tareas matemáticas, donde Qwen-3 8B supera a Llama 3.1 8B por amplios márgenes. Mientras que Llama 3.1 8B se impone ligeramente en Humanity’s Last Exam, Qwen-3 8B demuestra capacidades superiores en la mayoría de las aplicaciones prácticas.
Qwen 3 8B vs Llama 3.1 8B: Requisitos de hardware
| Precisión | Tamaño del modelo Qwen3-8B | Tamaño del modelo LLaMA 3.1–8B |
|---|---|---|
| FP32 (coma flotante de 32 bits) | ≈ 33 GB (8.2B × 4 bytes) | ≈ 32 GB (8.0B × 4 bytes) |
| FP16/BF16 (16 bits) | ≈ 16.4 GB (8.2B × 2 bytes) | ≈ 16 GB (8.0B × 2 bytes) |
| INT8 (cuantizado a 8 bits) | ≈ 8.2 GB (8.2B × 1 byte) | ≈ 8.0 GB (8.0B × 1 byte) |
| INT4 (cuantizado a 4 bits) | ≈ 4.1 GB (8.2B × 0.5 byte) | ≈ 4.0 GB (8.0B × 0.5 byte) |
- Entre ambos, no hay una gran diferencia en requisitos de hardware – pertenecen a la misma clase. En todo caso, el modo pensante de Qwen3-8B podría ralentizar un poco la inferencia al generar razonamiento verbose, pero se puede desactivar para ganar velocidad si es necesario.
Qwen 3 8B vs Llama 3.1 8B: Velocidad
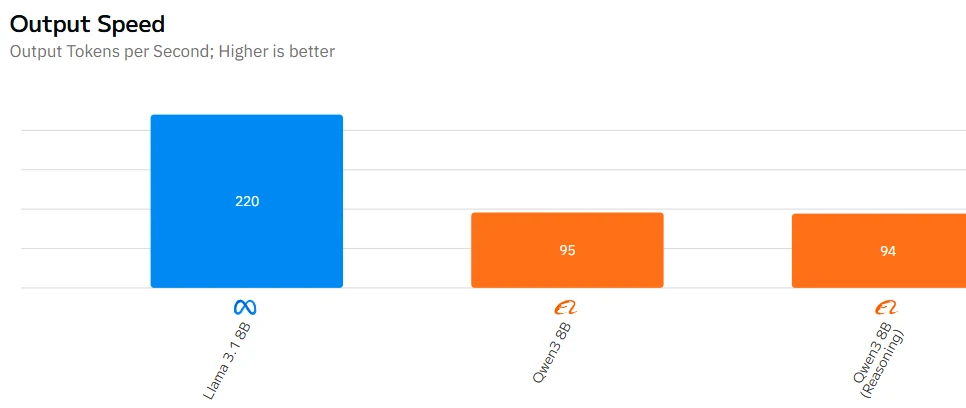
Fuente: Artificial Analysis
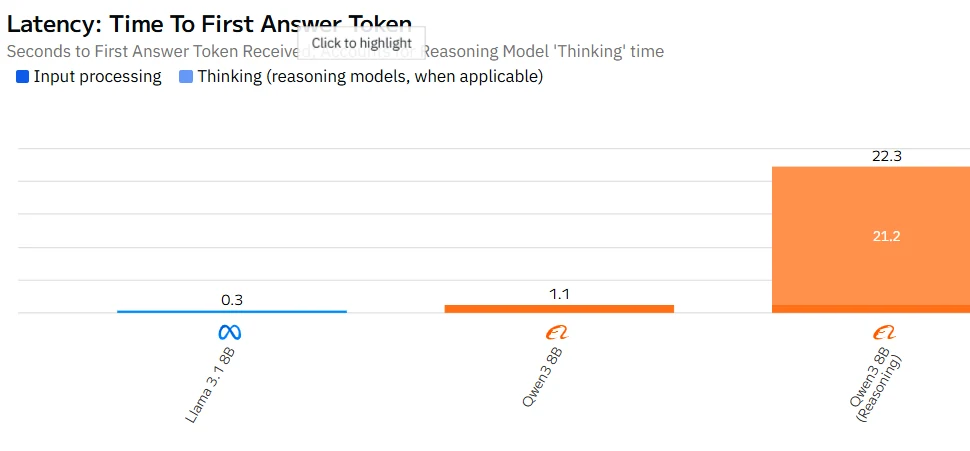
Fuente: Artificial Analysis
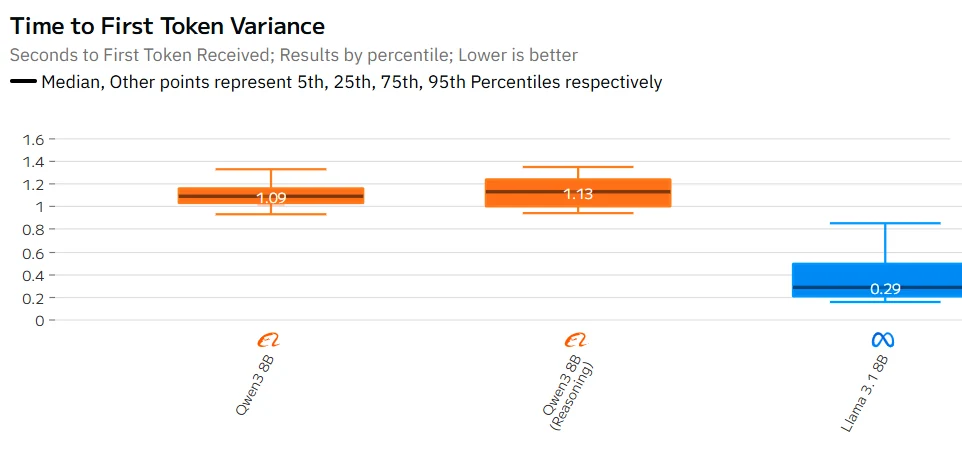
Fuente: Artificial Analysis
Qwen 3 8B vs Llama 3.1 8B: La mejor opción para la IA en educación
| Característica | Qwen 3 8B | LLaMA 3.1 8B |
|---|---|---|
| Capacidad de razonamiento | ✅ Razonamiento avanzado de cadena de pensamiento usando tokens thinking |
⚠️ Profundidad de razonamiento limitada |
| Tareas de matemáticas y lógica | ✅ Rendimiento sólido en benchmarks | ❌ Más débil en resolución de problemas complejos |
| Explicaciones paso a paso | ✅ Sí, gracias al “modo pensante” | ⚠️ Respuestas menos estructuradas |
| Soporte de idiomas | ✅ 100+ idiomas (incluye fuerte chino) | ❌ Solo 8 idiomas |
| Integración de herramientas | ✅ Puede llamar a APIs externas para funcionalidad extendida | ❌ Sin capacidades de uso de herramientas |
| Velocidad | ⚠️ Ligeramente más lento debido al modo pensante | ✅ Inferencia más rápida |
Otra forma de acelerar Qwen 3 8B: Prueba Novita API
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Entra en la página de “Settings” y copia la clave de API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico para tu lenguaje de programación.
Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<TU CLAVE DE API DE Novita AI>",
)
model = "qwen/qwen3-8b-fp8"
stream = True # o False
max_tokens = 2048
system_content = """Sé un asistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "¡Hola!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Para aplicaciones educativas, tareas de razonamiento y entornos multilingües, Qwen 3 8B es el modelo superior. Aunque LLaMA 3.1 8B es ligeramente más rápido, carece de la profundidad y flexibilidad que ofrece Qwen. Para aumentar la velocidad y facilitar el despliegue de Qwen, usar la API de Novita es una solución práctica y amigable para desarrolladores.
Preguntas frecuentes
¿Es Qwen 3 8B más lento que LLaMA 3.1 8B?
Ligeramente, debido a su modo de razonamiento, pero esto se puede desactivar para una inferencia más rápida.
¿Qué hace que Qwen 3 8B sea mejor para la educación?
Proporciona explicaciones estructuradas, mejor rendimiento en matemáticas y soporte multilingüe.
¿Cómo puedo desplegar Qwen 3 8B fácilmente?
Usa la API de Novita para una integración rápida, selección flexible de modelos y una opción de prueba gratuita.
*Novita AI *es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA mediante su API simple, al mismo tiempo que proporciona una GPU en la nube asequible y confiable para construir y escalar.



