

GLM 4.1V 9B Thinking est le premier modèle vision-langage au monde à intégrer un raisonnement par chaîne de pensée (CoT). Si vous envisagez un déploiement local, une question clé se pose : de combien de VRAM avez-vous besoin, et quels sont les coûts supplémentaires potentiels ?
Exigences en VRAM de GLM 4.1V 9B Thinking
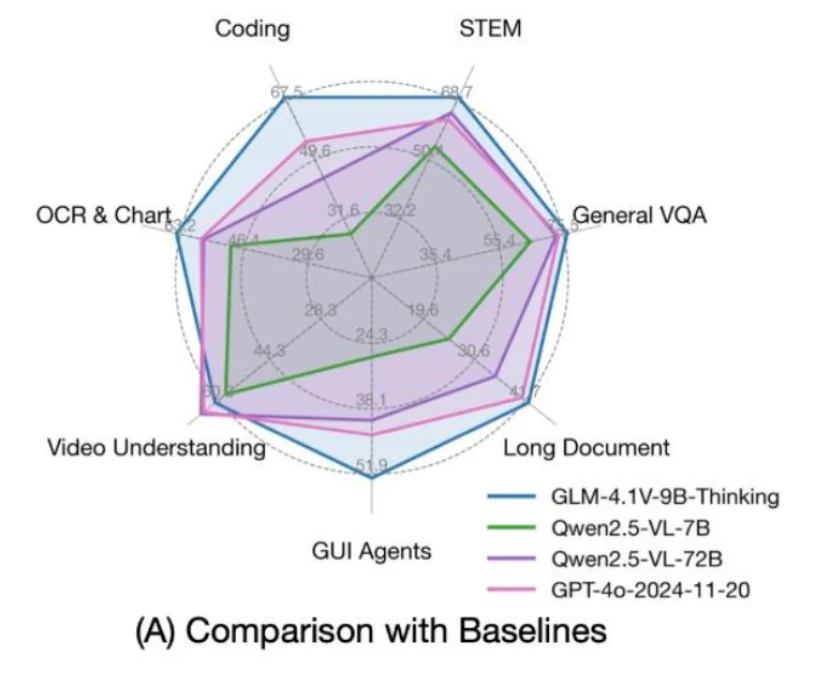
Construit sur la base de GLM 4 9B 0414, GLM 4.1V 9B Thinking vise à faire progresser les capacités de raisonnement dans l’IA vision-langage. En adoptant une nouvelle approche « penser d’abord » et en utilisant des techniques d’apprentissage par renforcement, ce modèle porte la compréhension multimodale à un niveau supérieur. En tant que modèle vision-langage pionnier doté d’un raisonnement par chaîne de pensée (CoT), GLM 4.1V 9B Thinking établit une nouvelle norme pour un raisonnement sophistiqué à la fois sur le texte et les images.
DeTHUDM
Exigences matérielles détaillées
Ce qui est encore plus remarquable, c’est que GLM 4.1V 9B Thinking ne compte que 9 milliards de paramètres, ce qui le rend suffisamment léger pour fonctionner sans problème sur des GPU grand public tels que le RTX 4090 ou même le 3090. Malgré sa taille compacte, GLM offre des résultats de premier ordre, surpassant de nombreux modèles beaucoup plus volumineux.
Inférence
| Appareil (GPU unique) | Framework | Mémoire minimale | Vitesse | Précision |
|---|---|---|---|---|
| NVIDIA A100 | transformers | 22 Go | 14 - 22 Tokens / s | BF16 |
| NVIDIA A100 | vLLM | 22 Go | 60 - 70 Tokens / s | BF16 |
Fine-tuning
| Appareil (Cluster) | Stratégie | Mémoire minimale / Nb de GPU | Taille de lot (par GPU) | Gel |
|---|---|---|---|---|
| NVIDIA A100 | LORA | 21 Go / 1 GPU | 1 | Geler VIT |
| NVIDIA A100 | FULL ZERO2 | 280 Go / 4 GPU | 1 | Geler VIT |
| NVIDIA A100 | FULL ZERO3 | 192 Go / 4 GPU | 1 | Geler VIT |
| NVIDIA A100 | FULL ZERO2 | 304 Go / 4 GPU | 1 | Sans gel |
| NVIDIA A100 | FULL ZERO3 | 210 Go / 4 GPU | 1 | Sans gel |
Comparaison des besoins en VRAM avec d’autres modèles
| Caractéristique | GLM 4.1V 9B Thinking | Qwen 2.5 VL 72B |
|---|---|---|
| VRAM totale | 22 Go | 640 Go |
| GPU utilisés | 1 GPU | 8 GPU |
Conseils pour choisir un GPU compatible avec GLM 4.1V 9B Thinking
- Architecture
Détermine les fonctionnalités clés, l’efficacité opérationnelle et la compatibilité système. - Cœurs CUDA, Tensor et RT
Affectent la vitesse d’entraînement et d’inférence du modèle, ainsi que les performances graphiques. - VRAM et bande passante mémoire
Impactent la taille maximale du modèle que vous pouvez utiliser et la vitesse de traitement lors de la manipulation de grands ensembles de données. - Prise en charge FP8/FP16/FP32/FP64
Influence la précision de calcul, la consommation d’énergie et les performances pour les applications IA et scientifiques. - Consommation électrique (TDP)
A des implications sur les coûts d’électricité, les besoins de refroidissement et la planification matérielle. - NVLink, MIG, ECC
Permettent une meilleure évolutivité, une fiabilité accrue et la prise en charge de l’exécution simultanée de plusieurs modèles. - Cas d’usage idéaux
Indiquent pour quels types de charges de travail le GPU est le mieux adapté. - Coût et déploiement
Affectent les considérations budgétaires et la facilité d’obtention et d’intégration du GPU.
GPU recommandés
| Spécification | NVIDIA A100 Pcle | NVIDIA RTX 3090 |
|---|---|---|
| Architecture | Ampere | Ampere |
| Cas d’usage principal | Data Center & HPC | Gaming & Création de contenu |
| VRAM | 80 Go HBM2e | 24 Go GDDR6X |
| Interface mémoire | 5120-bit | 384-bit |
| Bande passante mémoire | 1 935 Go/s | 936 Go/s |
| Cœurs CUDA | 6 912 | 10 496 |
| Cœurs Tensor | 432 (3e génération) | 328 (3e génération) |
| Cœurs RT | N/A | 82 (2e génération) |
| Performance FP32 | 19,5 TFLOPS | ~35,6 TFLOPS |
| Performance Tensor | 624 TFLOPS (FP16/BF16 avec sparsité) | ~142 TFLOPS (FP16 avec sparsité) |
| Interface système | PCIe 4.0 x16 | PCIe 4.0 x16 |
| Support NVLink | Oui (pont 600 Go/s) | Oui (pont 112,5 Go/s) |
| Consommation max | 300 W | 350 W |
| Fonctionnalités spéciales | MIG, ECC, Calcul FP64 | Ampere bureau, NVLink pour gaming |
Combien coûtent les GPU ci-dessus ?
| Modèle de GPU | Prix de lancement (USD) | Coût d’électricité sur 1 an (USD) | GPU Cloud sur Novita AI |
|---|---|---|---|
| NVIDIA RTX 3090 | 1 499 $ | 521,22 $ | 0,21 $/h |
| NVIDIA A100 Pcle 80 Go | 11 000 $ | 446,76 $ | 1,60 $/h |
Découvrez plus de prix de GPU Cloud
Acheter son propre GPU peut sembler une bonne idée, mais lorsque vous additionnez tous les coûts, utiliser des GPU cloud est souvent moins cher—même si vous n’avez pas besoin d’énormes quantités de mémoire.
Pour les petits développeurs, choisissez le GPU Cloud
En résumé, des plateformes comme Novita AI vous permettent d’accéder à des GPU puissants sans les coûts initiaux élevés ni la maintenance continue. Cette approche flexible vous aide à expérimenter et à construire plus rapidement, à réduire les dépenses quotidiennes et à suivre le rythme des évolutions rapides de la technologie IA.
Une option stable et très rentable : Novita AI
| Fournisseur | Type de GPU | Prix (USD/h) |
|---|---|---|
| Novita AI | A100 Pcle | 1,60 $/h |
| RTX3090 | 0,21 $/h | |
| RunPod | A100 Pcle | 1,64 $/h |
| RTX3090 | 0,46 $/h |
Quand choisir un GPU local
1. Utilisation intensive constante
Si vous avez besoin d’un GPU fonctionnant 24h/24 et 7j/7—par exemple pour des serveurs d’inférence ou un entraînement régulier de modèles—posséder votre propre matériel peut être plus rentable à long terme. Certains chercheurs ont constaté qu’un RTX 3090 peut s’amortir par rapport à des services cloud comme AWS en environ un an.
2. Faible latence ou exigences de données locales
Les applications en temps réel comme la robotique ou l’analyse en périphérie nécessitent une latence minimale. Les solutions cloud introduisent inévitablement des délais réseau, alors que les GPU locaux peuvent éviter ces problèmes.
3. Traitement de données sensibles ou réglementées
Lorsque vous travaillez avec des données hautement sensibles ou réglementées (par exemple dans les domaines médical ou financier), les entreprises préfèrent souvent du matériel sur site ou des solutions cloud privées pour garder un contrôle total sur leurs données.
Que pouvez-vous gagner en utilisant des GPU Cloud ?
- Économies : Ne payez que pour ce que vous utilisez, évitant ainsi de gros investissements matériels initiaux.
- Évolutivité : Accédez instantanément à plus (ou plus puissants) de GPU à mesure que votre charge de travail augmente.
- Flexibilité : Basculez facilement entre différents types et configurations de GPU pour répondre à vos besoins.
- Aucune maintenance : Gagnez du temps et des efforts en laissant le fournisseur cloud gérer les pannes matérielles, les mises à jour et le refroidissement.
- Accès mondial : Travaillez de n’importe où et collaborez avec des équipes dans le monde entier.
- Innovation plus rapide : Lancez rapidement des projets et expérimentez sans attendre la livraison ou la configuration du matériel.
Comment accéder à GLM 4.1V 9B Thinking sur un GPU Cloud comme Novita AI ?
Étape 1 : Créer un compte
Si vous êtes nouveau sur Novita AI, commencez par créer un compte sur notre site web. Une fois inscrit, dirigez-vous vers l’onglet « GPUs » pour explorer les ressources disponibles et commencer votre parcours.

Essayez les GPU haute performance de Novita AI
Étape 2 : Explorer les templates et les serveurs GPU
Commencez par sélectionner un template adapté aux besoins de votre projet, comme PyTorch, TensorFlow ou CUDA. Choisissez la version qui correspond à vos exigences, par exemple PyTorch 2.2.1 ou CUDA 11.8.0. Ensuite, sélectionnez la configuration de serveur GPU A100, qui offre des performances puissantes pour gérer des charges de travail exigeantes avec une VRAM, une RAM et une capacité disque suffisantes.

Étape 3 : Personnaliser votre déploiement
Après avoir sélectionné un template et un GPU, personnalisez les paramètres de déploiement en ajustant des paramètres comme la version du système d’exploitation (par exemple CUDA 11.8). Vous pouvez également modifier d’autres configurations pour adapter l’environnement aux besoins spécifiques de votre projet.
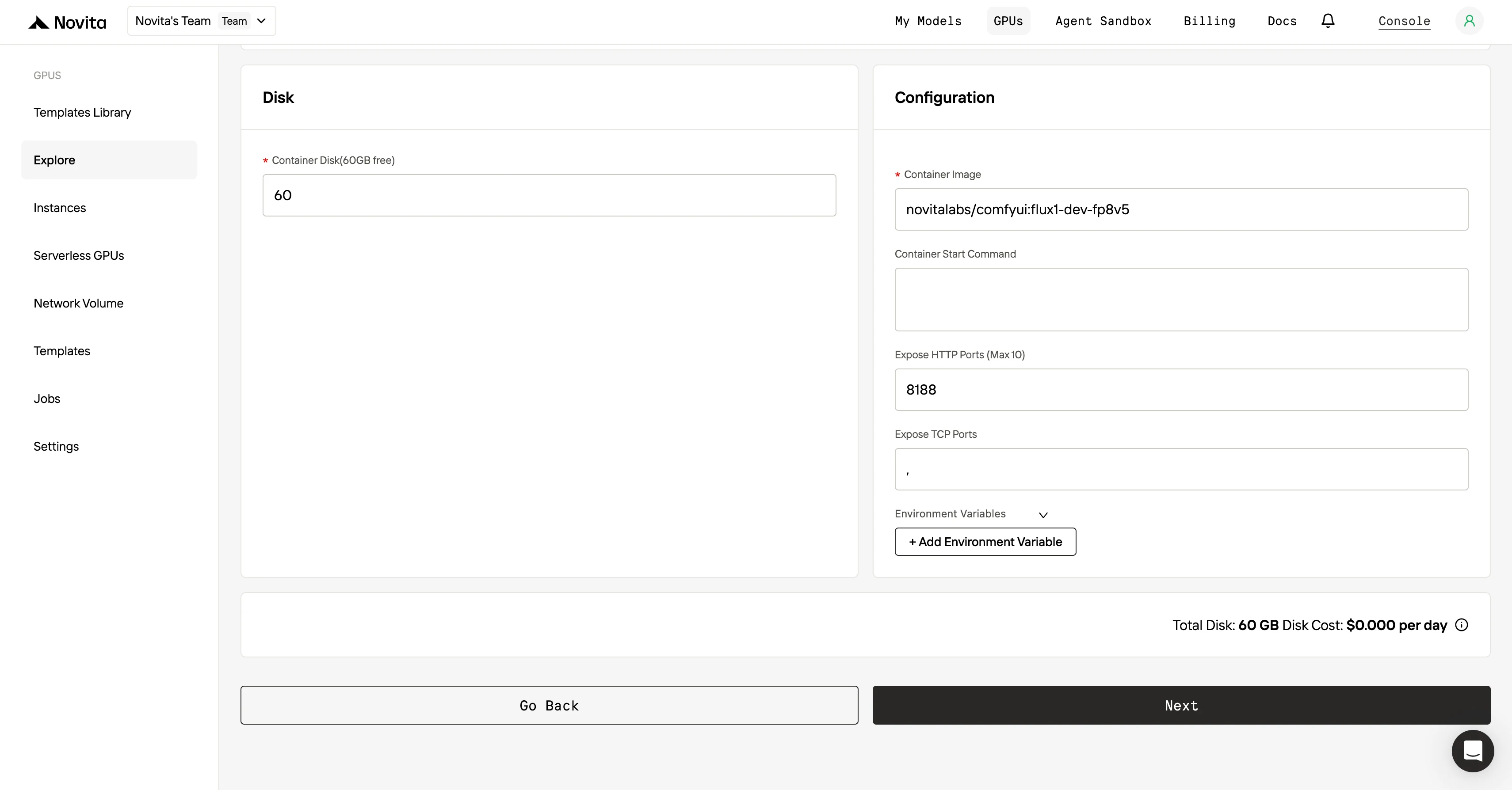
Étape 4 : Lancer une instance
Une fois le template et les paramètres de déploiement finalisés, cliquez sur « Lancer l’instance » pour configurer votre instance GPU. Cela démarrera la mise en place de l’environnement, vous permettant de commencer à utiliser les ressources GPU pour vos tâches IA.
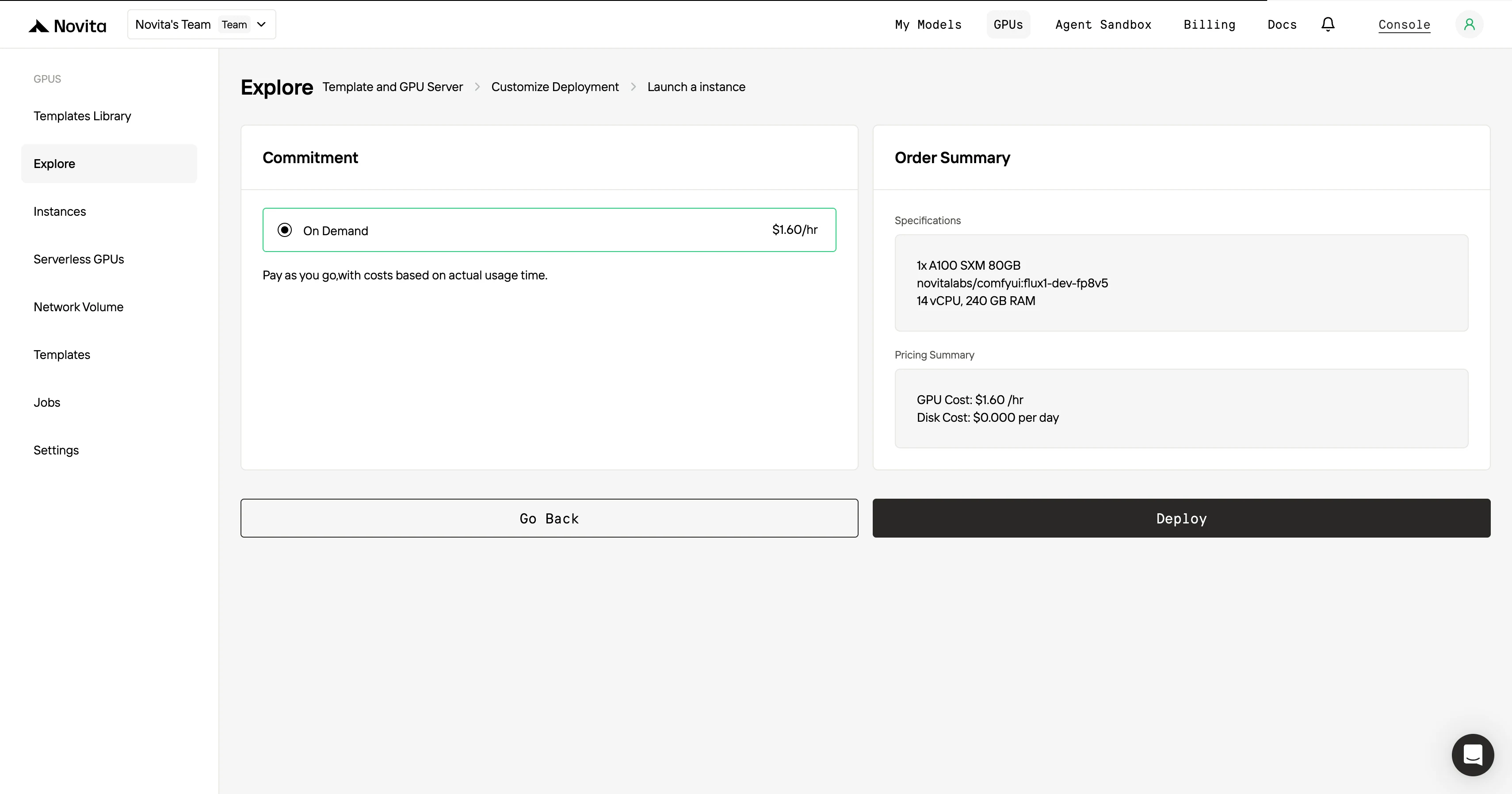
Pour une efficacité et une commodité maximales, choisissez l’API !
Novita AI fournit des API GLM 4.1V 9B Thinking avec 65536 de contexte, et des coûts de 0,035 $/entrée et 0,138 $/sortie.
De Openrouter
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez GLM 4.1V 9B maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Rendez-vous dans la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM Novita AI. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_kgNdXtDPt2zYc95i-nDWPaW4Zl_e7nf4VDpukuIVBKpko1-LE8xCasG4YK7c-3c1xnPzGYRuocFk_DhkPUUQyQ==",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # or False
max_tokens = 4000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GLM 4.1V 9B Thinking établit une nouvelle norme pour le raisonnement visuel-langage. Avec un besoin minimum de VRAM de 22 Go (pour l’inférence), il fonctionne sans problème sur des GPU grand public comme le RTX 3090 ou 4090. Bien que cela soit bien plus accessible que les modèles géants nécessitant du matériel de niveau serveur, vous devez toujours prendre en compte le prix élevé de ces GPU, la consommation électrique et les éventuelles mises à niveau de refroidissement ou système. Pour la plupart des développeurs, les GPU cloud restent le choix le plus flexible et le plus rentable pour accéder à GLM 4.1V 9B Thinking.
Questions fréquentes
De combien de VRAM ai-je besoin pour exécuter GLM 4.1V 9B Thinking en local ?
Au moins 22 Go de VRAM sont nécessaires pour l’inférence. Cela signifie qu’un seul RTX 3090, 4090 ou GPU similaire suffit.
Quand est-il judicieux d’acheter un GPU local ?
Si votre GPU sera occupé presque tout le temps, ou si vous avez besoin d’une latence ultra-faible, ou si vous travaillez avec des données sensibles qui ne peuvent pas quitter vos locaux.
Quelle est la façon la plus simple d’utiliser GLM 4.1V 9B Thinking ?
Utilisez un fournisseur cloud comme Novita AI et accédez au modèle via API—sans vous soucier du matériel, de la configuration ou de la maintenance continue.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API facile à utiliser, tout en fournissant un cloud GPU abordable et fiable pour construire et faire évoluer.



