

GLM 4.1V 9B Thinking 是全球首款具备思维链(Chain-of-Thought, CoT)推理能力的视觉语言模型。如果你正在考虑本地部署,一个关键问题是:你需要多少显存(VRAM),以及可能涉及哪些额外成本?
GLM 4.1V 9B Thinking 的 VRAM 需求
GLM 4.1V 9B Thinking 基于 GLM 4 9B 0414 基础,旨在提升视觉语言 AI 的推理能力。通过采用新颖的“思考优先”方法并利用强化学习技术,该模型将多模态理解提升到了新高度。作为首个具备思维链推理的视觉语言模型,GLM 4.1V 9B Thinking 为跨文本和图像的复杂推理设立了新标准。
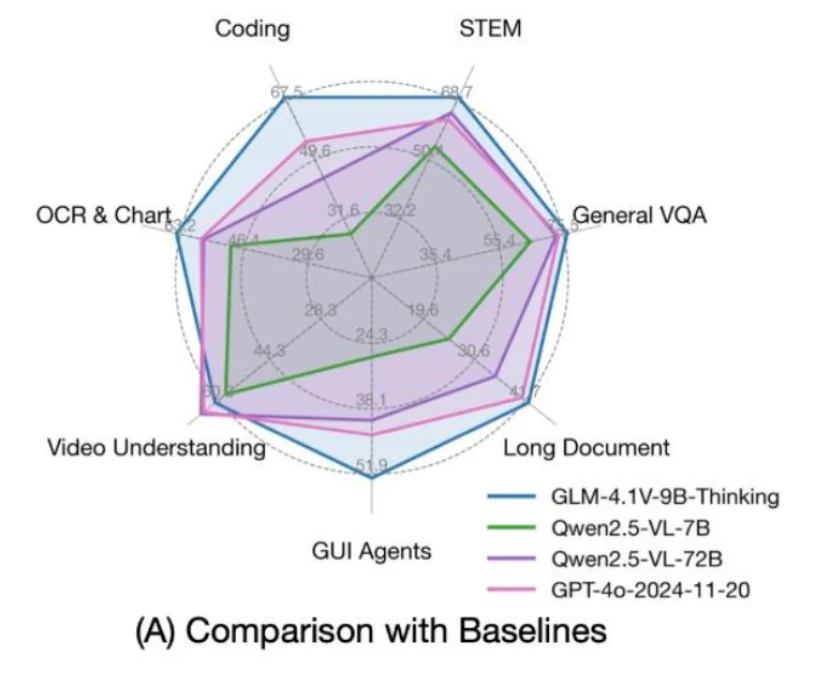
来源:THUDM
详细硬件需求
更令人瞩目的是,GLM 4.1V 9B Thinking 仅有 90 亿参数,轻量级的特性使其能够在 RTX 4090 甚至 3090 等消费级 GPU 上流畅运行。尽管体积小巧,GLM 仍能提供顶级结果,超越许多规模更大的模型。
推理
| 设备(单 GPU) | 框架 | 最小内存 | 速度 | 精度 |
|---|---|---|---|---|
| NVIDIA A100 | transformers | 22GB | 14 - 22 Tokens / s | BF16 |
| NVIDIA A100 | vLLM | 22GB | 60 - 70 Tokens / s | BF16 |
微调
| 设备(集群) | 策略 | 最小内存 / GPU 数量 | 批次大小(每 GPU) | 冻结层 |
|---|---|---|---|---|
| NVIDIA A100 | LoRA | 21GB / 1 GPU | 1 | 冻结 VIT |
| NVIDIA A100 | FULL ZERO2 | 280GB / 4 GPU | 1 | 冻结 VIT |
| NVIDIA A100 | FULL ZERO3 | 192GB / 4 GPU | 1 | 冻结 VIT |
| NVIDIA A100 | FULL ZERO2 | 304GB / 4 GPU | 1 | 不冻结 |
| NVIDIA A100 | FULL ZERO3 | 210GB / 4 GPU | 1 | 不冻结 |
与其他模型的 VRAM 需求对比
| **特性 ** | GLM 4.1V 9B Thinking | Qwen 2.5 VL 72B |
|---|---|---|
| 总显存 | 22 GB | 640 GB |
| 所用 GPU | 1 GPU | 8 GPU |
选择支持 GLM 4.1V 9B Thinking 的 GPU 小贴士
- 架构
决定关键特性、运行效率和系统兼容性。 - CUDA、Tensor 和 RT Core
影响模型训练和推理的速度,以及图形性能。 - VRAM 和显存带宽
影响可处理的最大模型规模以及处理大型数据集时的速度。 - FP8/FP16/FP32/FP64 支持
影响计算精度、能耗以及 AI 和科学应用的性能。 - 功耗(TDP)
涉及电力成本、散热需求和硬件规划。 - NVLink、MIG、ECC
实现更好的可扩展性、更高的可靠性,并支持同时运行多个模型。 - 理想用例
指示 GPU 最适合哪些类型的工作负载。 - 成本与部署
影响预算考量以及 GPU 获取和集成的难易程度。
推荐 GPU
| 规格 | NVIDIA A100 Pcle | NVIDIA RTX 3090 |
|---|---|---|
| 架构 | Ampere | Ampere |
| 主要用途 | 数据中心与 HPC | 游戏与内容创作 |
| VRAM | 80 GB HBM2e | 24 GB GDDR6X |
| 显存接口 | 5120-bit | 384-bit |
| 显存带宽 | 1,935 GB/s | 936 GB/s |
| CUDA 核心 | 6,912 | 10,496 |
| Tensor Core | 432(第 3 代) | 328(第 3 代) |
| RT Core | N/A | 82(第 2 代) |
| FP32 性能 | 19.5 TFLOPS | ~35.6 TFLOPS |
| Tensor 性能 | 624 TFLOPS(FP16/BF16,含稀疏性) | ~142 TFLOPS(FP16,含稀疏性) |
| 系统接口 | PCIe 4.0 x16 | PCIe 4.0 x16 |
| NVLink 支持 | 是(600 GB/s 桥接) | 是(112.5 GB/s 桥接) |
| 最大功耗 | 300 W | 350 W |
| 特殊功能 | MIG、ECC、FP64 计算 | 桌面级 Ampere、支持 NVLink(游戏) |
上述 GPU 的成本是多少?
| GPU 型号 | 初始建议零售价(美元) | 一年电费(美元) | Novita AI 云 GPU |
|---|---|---|---|
| NVIDIA RTX 3090 | $1,499 | $521.22 | $0.21/hr |
| NVIDIA A100 Pcle 80GB | $11,000 | $446.76 | $1.60/hr |
自己购买 GPU 可能看似不错,但把所有成本加起来后,使用云 GPU 往往更便宜——即使你不需要超大显存。
对于小型开发者,选择云 GPU
简而言之,像 Novita AI 这样的平台让你无需高昂的初始投资或持续的维护成本就能使用强大的 GPU。这种灵活的方式帮助你更快地进行实验和构建,降低日常开销,并跟上 AI 技术的快速变化。
稳定且高性价比的选择:Novita AI
| 提供商 | GPU 类型 | 价格(美元/小时) |
|---|---|---|
| Novita AI | A100 Pcle | $1.60/hr |
| RTX3090 | $0.21/hr | |
| RunPod | A100 Pcle | $1.64/hr |
| RTX3090 | $0.46/hr |
何时选择本地 GPU
1. 持续重型使用
如果你的 GPU 需要全天候运行——例如用于推理服务器或定期模型训练——长期来看拥有自有硬件可能更具成本效益。某些研究人员发现,RTX 3090 大约一年内就能从 AWS 等云服务的比较中回本。
2. 低延迟或本地数据需求
实时应用(如机器人或边缘分析)要求极低的延迟。云解决方案不可避免地会引入网络延迟,而本地 GPU 则可以完全避免这些问题。
3. 处理敏感或受监管数据
当处理高度敏感或受监管的数据(例如医疗或金融领域)时,企业通常更愿意使用本地硬件或私有云解决方案,以保持对数据的完全控制。
使用云 GPU 能带来哪些好处?
- 节省成本:按需付费,避免大额硬件投资。
- 可扩展性:随着工作负载增长,即时获得更多(或更强大)的 GPU。
- 灵活性:轻松切换不同的 GPU 类型和配置以匹配需求。
- 无需维护:由云提供商处理硬件故障、更新和散热,节省时间和精力。
- 全球访问:随时随地工作,并与全球团队协作。
- 加速创新:无需等待硬件交付或设置,快速启动项目并进行实验。
如何在 Novita AI 等云 GPU 上使用 GLM 4.1V 9B Thinking?
第一步:注册账户
如果你是 Novita AI 新用户,请先在官网创建账户。注册完成后,导航到“GPU”选项卡,探索可用资源并开始使用。

第二步:探索模板和 GPU 服务器
首先选择符合项目需求的模板,例如 PyTorch、TensorFlow 或 CUDA。选择合适的版本(如 PyTorch 2.2.1 或 CUDA 11.8.0)。然后选择 A100 GPU 服务器配置,该配置提供强大的性能,足以处理要求苛刻的工作负载,并配备充足的 VRAM、RAM 和磁盘容量。

第三步:定制部署
选择模板和 GPU 后,通过调整参数(如操作系统版本,例如 CUDA 11.8)来定制部署设置。你也可以微调其他配置,使环境更贴合项目的特定要求。
第四步:启动实例
完成模板和部署设置后,点击“启动实例”来设置你的 GPU 实例。这将开始环境搭建,使你能够开始使用 GPU 资源进行 AI 任务。
追求最高效率与便利?选择 API!
Novita AI 提供 GLM 4.1V 9B Thinking API,支持 **65536 上下文 **,费用为 **$0.035/输入 ** 和 $0.138/输出。
来源:Openrouter
第一步:登录并访问模型库
登录你的账户,点击 模型库 按钮。

第二步:选择模型
浏览可用选项,选择适合你需求的模型。
第三步:开始免费试用
开始免费试用,探索所选模型的功能。
第四步:获取 API 密钥
为了验证 API,我们将向你提供一个新的 API 密钥。进入“设置”页面,按图中所示复制 API 密钥。

第五步:安装 API
使用与你的编程语言对应的包管理器安装 API。
安装完成后,将必要的库导入开发环境。使用你的 API 密钥初始化客户端,开始与 Novita AI LLM 交互。以下是 Python 用户使用聊天补全 API 的示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_kgNdXtDPt2zYc95i-nDWPaW4Zl_e7nf4VDpukuIVBKpko1-LE8xCasG4YK7c-3c1xnPzGYRuocFk_DhkPUUQyQ==",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # or False
max_tokens = 4000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GLM 4.1V 9B Thinking 为视觉语言推理设立了新标准。它的最低 VRAM 需求仅为 22GB(推理时),能在 RTX 3090 或 4090 等消费级 GPU 上流畅运行。尽管这比需要服务器级硬件的大型模型容易得多,但你仍需考虑此类 GPU 的高昂价格、功耗以及潜在的散热或系统升级问题。对于大多数开发者而言,云 GPU 仍然是访问 GLM 4.1V 9B Thinking 最灵活、最具成本效益的选择。
常见问题
本地运行 GLM 4.1V 9B Thinking 需要多少 VRAM?
推理至少需要 22GB VRAM。这意味着单块 RTX 3090、4090 或类似 GPU 即可满足。
什么情况下购买本地 GPU 更划算?
如果你的 GPU 几乎始终满载运行,或者你需要极低延迟,又或者你处理的是不能离开本地的敏感数据。
使用 GLM 4.1V 9B Thinking 最简单的方式是什么?
使用像 Novita AI 这样的云服务商,通过 API 访问模型——无需担心硬件、设置或持续维护。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。



