

GLM 4.1V 9B Thinking 是世界上首個具備鏈式思維(CoT)推理能力的視覺語言模型。如果您考慮本地部署,一個關鍵問題是:您需要多少 VRAM,以及可能涉及哪些額外成本?
GLM 4.1V 9B Thinking 的 VRAM 需求
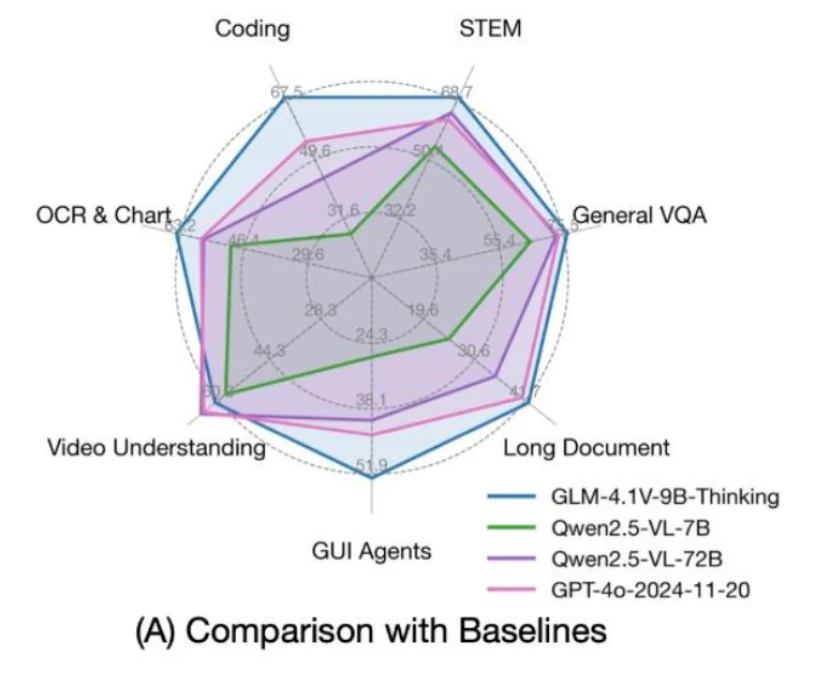
GLM 4.1V 9B Thinking 基於 GLM 4 9B 0414 基礎構建,旨在提升視覺語言 AI 的推理能力。通過採用新穎的「思考優先」方法並利用強化學習技術,該模型將多模態理解提升到新的水平。作為首個採用鏈式思維(CoT)推理的視覺語言模型,GLM 4.1V 9B Thinking 為跨文本和圖像的複雜推理樹立了新標準。
來自 THUDM
詳細硬體需求
更令人驚豔的是,GLM 4.1V 9B Thinking 僅有 90 億參數,使其輕量到足以在消費者級 GPU(如 RTX 4090 甚至 3090)上流暢運行。儘管體積小巧,GLM 仍能提供頂級結果,超越許多更大規模的模型。
推論
| 設備(單一 GPU) | 框架 | 最小記憶體 | 速度 | 精度 |
|---|---|---|---|---|
| NVIDIA A100 | transformers | 22GB | 14 - 22 Tokens / s | BF16 |
| NVIDIA A100 | vLLM | 22GB | 60 - 70 Tokens / s | BF16 |
微調
| 設備(叢集) | 策略 | 最小記憶體 / GPU 數量 | 批次大小(每 GPU) | 凍結 |
|---|---|---|---|---|
| NVIDIA A100 | LORA | 21GB / 1 GPU | 1 | 凍結 VIT |
| NVIDIA A100 | FULL ZERO2 | 280GB / 4 GPUs | 1 | 凍結 VIT |
| NVIDIA A100 | FULL ZERO3 | 192GB / 4 GPUs | 1 | 凍結 VIT |
| NVIDIA A100 | FULL ZERO2 | 304GB / 4 GPUs | 1 | 無凍結 |
| NVIDIA A100 | FULL ZERO3 | 210GB / 4 GPUs | 1 | 無凍結 |
與其他模型的 VRAM 需求比較
| **功能 ** | GLM 4.1V 9B Thinking | Qwen 2.5 VL 72B |
|---|---|---|
| 總 VRAM | 22 GB | 640 GB |
| 使用的 GPU | 1 GPU | 8 GPUs |
選擇支援 GLM 4.1V 9B Thinking 的 GPU 小技巧
- 架構
決定關鍵功能、操作效率及系統相容性。 - CUDA、張量及 RT 核心
影響模型訓練和推論的速度,以及圖形效能。 - VRAM 和記憶體頻寬
影響您能處理的最大模型規模,以及在處理大型資料集時的處理速度。 - FP8/FP16/FP32/FP64 支援
影響計算精度、能耗,以及 AI 和科學應用的效能。 - 功耗(TDP)
對電費、散熱需求和硬體規劃有影響。 - NVLink、MIG、ECC
實現更好的擴展性、增強可靠性,並支援同時運行多個模型。 - 理想使用案例
指出 GPU 最適合哪種類型的工作負載。 - 成本和部署
影響預算考量,以及取得和整合 GPU 的難易度。
推薦 GPU
| 規格 | NVIDIA A100 Pcle | NVIDIA RTX 3090 |
|---|---|---|
| 架構 | Ampere | Ampere |
| 主要用途 | 資料中心與 HPC | 遊戲與內容創作 |
| VRAM | 80 GB HBM2e | 24 GB GDDR6X |
| 記憶體介面 | 5120-bit | 384-bit |
| 記憶體頻寬 | 1,935 GB/s | 936 GB/s |
| CUDA 核心 | 6,912 | 10,496 |
| 張量核心 | 432 (第 3 代) | 328 (第 3 代) |
| RT 核心 | N/A | 82 (第 2 代) |
| FP32 效能 | 19.5 TFLOPS | ~35.6 TFLOPS |
| 張量效能 | 624 TFLOPS (FP16/BF16 含稀疏性) | ~142 TFLOPS (FP16 含稀疏性) |
| 系統介面 | PCIe 4.0 x16 | PCIe 4.0 x16 |
| NVLink 支援 | 是 (600 GB/s 橋接) | 是 (112.5 GB/s 橋接) |
| 最大功耗 | 300 W | 350 W |
| 特殊功能 | MIG、ECC、FP64 計算 | 桌面版 Ampere、NVLink 遊戲用 |
以上 GPU 的價格?
| GPU 型號 | 首發建議售價 (USD) | 一年電費 (USD) | Novita AI 雲端 GPU |
|---|---|---|---|
| NVIDIA RTX 3090 | $1,499 | $521.22 | $0.21/hr |
| NVIDIA A100 Pcle 80GB | $11,000 | $446.76 | $1.60/hr |
自行購買 GPU 可能看似划算,但當你將所有成本加總,使用雲端 GPU 往往更便宜——即使你不需要巨大的記憶體。
對於小型開發者,選擇雲端 GPU
簡而言之,像 Novita AI 這樣的平台讓你可以使用強大的 GPU,而無需高額的前期成本或持續的維護。這種靈活的方法幫助你更快地實驗和構建,降低日常開支,並跟上 AI 技術的快速變化。
一個穩定且高成本效益的選擇:Novita AI
| 提供商 | GPU 類型 | 價格 (USD/hr) |
|---|---|---|
| Novita AI | A100 Pcle | $1.60/hr |
| RTX3090 | $0.21/hr | |
| RunPod | A100 Pcle | $1.64/hr |
| RTX3090 | $0.46/hr |
何時選擇本地 GPU
1. 持續高負載使用
如果您的 GPU 需要全天候運行——例如用於推論伺服器或定期模型訓練——長期來看,擁有自己的硬體可能更具成本效益。部分研究人員發現,RTX 3090 相較於 AWS 等雲端服務,大約一年即可回本。
2. 低延遲或本地資料需求
機器人技術或邊緣分析等即時應用需要極低的延遲。雲端解決方案不可避免地會引入網路延遲,但本地 GPU 可以完全避免這些問題。
3. 處理敏感或受監管資料
當您處理高度敏感或受監管的資料時(例如在醫療或金融領域),企業通常偏好使用本地硬體或私有雲端解決方案,以完全掌握資料控制權。
使用雲端 GPU 能獲得什麼?
- 節省成本:按使用量付費,避免大額前期硬體投資。
- 可擴展性:隨著工作負載增加,即時存取更多(或更強大)的 GPU。
- 靈活性:輕鬆切換不同的 GPU 類型和配置,以符合您的需求。
- 無需維護:由雲端提供商處理硬體故障、更新和散熱,節省時間和精力。
- 全球存取:可從任何地方工作,並與全球團隊協作。
- 更快創新:無需等待硬體到貨或設定,快速啟動專案進行實驗。
如何在像 Novita AI 這樣的雲端 GPU 上使用 GLM 4.1V 9B Thinking?
步驟 1:註冊帳戶
如果您是 Novita AI 的新用戶,請先在我們網站上建立帳戶。註冊後,前往「GPUs」分頁探索可用資源,開始您的旅程。

步驟 2:探索模板和 GPU 伺服器
開始選擇符合您專案需求的模板,例如 PyTorch、TensorFlow 或 CUDA。選擇適合您需求的版本,例如 PyTorch 2.2.1 或 CUDA 11.8.0。然後,選擇 A100 GPU 伺服器配置,提供強大效能以處理需要大量 VRAM、RAM 和磁碟容量的苛刻工作負載。

步驟 3:自訂您的部署
選擇模板和 GPU 後,自訂部署設定,調整作業系統版本等參數(例如 CUDA 11.8)。您也可以調整其他設定,以根據專案的特定需求量身打造環境。
步驟 4:啟動執行個體
確認模板和部署設定後,按一下「啟動執行個體」來設定您的 GPU 執行個體。這將啟動環境設定,讓您開始使用 GPU 資源進行 AI 任務。
為了極致效率和便利性,請選擇 API!
Novita AI 提供 GLM 4.1V 9B Thinking API,具有 **65536 上下文 **,成本為 **$0.035/輸入 ** 和 $0.138/輸出。
來自 Openrouter
步驟 1:登入並存取模型庫
登入您的帳戶,然後按一下 模型庫 按鈕。

步驟 2:選擇您的模型
瀏覽可用選項,選擇符合您需求的模型。
步驟 3:開始免費試用
開始免費試用,探索所選模型的功能。
步驟 4:取得您的 API 金鑰
為了對 API 進行身分驗證,我們會提供您一個新的 API 金鑰。進入「設定」頁面,您可以按照圖示複製 API 金鑰。

步驟 5:安裝 API
使用您程式語言的套件管理器安裝 API。
安裝完成後,將必要的函式庫匯入您的開發環境。使用您的 API 金鑰初始化 API,開始與 Novita AI LLM 互動。以下是 Python 使用者使用聊天補全 API 的範例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_kgNdXtDPt2zYc95i-nDWPaW4Zl_e7nf4VDpukuIVBKpko1-LE8xCasG4YK7c-3c1xnPzGYRuocFk_DhkPUUQyQ==",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # or False
max_tokens = 4000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GLM 4.1V 9B Thinking 為視覺語言推理樹立了新標準。最低 VRAM 需求為 22GB(推論),可在 RTX 3090 或 4090 等消費級 GPU 上流暢運行。雖然這比需要伺服器級硬體的巨型模型更容易取得,但仍需考慮這些 GPU 的高昂價格、功耗以及潛在的冷卻或系統升級需求。對大多數開發者而言,雲端 GPU 仍是存取 GLM 4.1V 9B Thinking 最靈活且最具成本效益的選擇。
常見問題
本地運行 GLM 4.1V 9B Thinking 需要多少 VRAM?
推論至少需要 22GB VRAM。這意味著一個 RTX 3090、4090 或類似 GPU 即足夠。
何時購買本地 GPU 有意義?
如果您的 GPU 幾乎一直滿載運行,或者您需要極低延遲,又或者您處理的敏感資料無法離開您的場所。
使用 GLM 4.1V 9B Thinking 最簡單的方式是什麼?
使用像 Novita AI 這樣的雲端提供商,並透過 API 存取模型——無需擔心硬體、設定或持續維護。
Novita AI 是一個 AI 雲端平台,為開發者提供使用簡單 API 部署 AI 模型的簡便方式,同時提供經濟實惠且可靠的 GPU 雲端,用於構建和擴展。



