

GLM 4.1V 9B Thinking は、チェーン・オブ・ソート(CoT)推論を備えた世界初のビジョン・ランゲージモデルです。ローカルデプロイを検討しているなら、重要な疑問は「必要なVRAMの量と、追加コストはどれくらいか」です。
GLM 4.1V 9B ThinkingのVRAM要件
GLM 4 9B 0414をベースに構築されたGLM 4.1V 9B Thinkingは、ビジョン・ランゲージAIにおける推論能力の向上を目指しています。新しい「思考優先」アプローチを採用し、強化学習技術を活用することで、マルチモーダル理解を次のレベルへと引き上げます。チェーン・オブ・ソート(CoT)推論を備えた先駆的なビジョン・ランゲージモデルとして、GLM 4.1V 9B Thinkingはテキストと画像の両方にわたる高度な推論の新たな基準を打ち立てています。
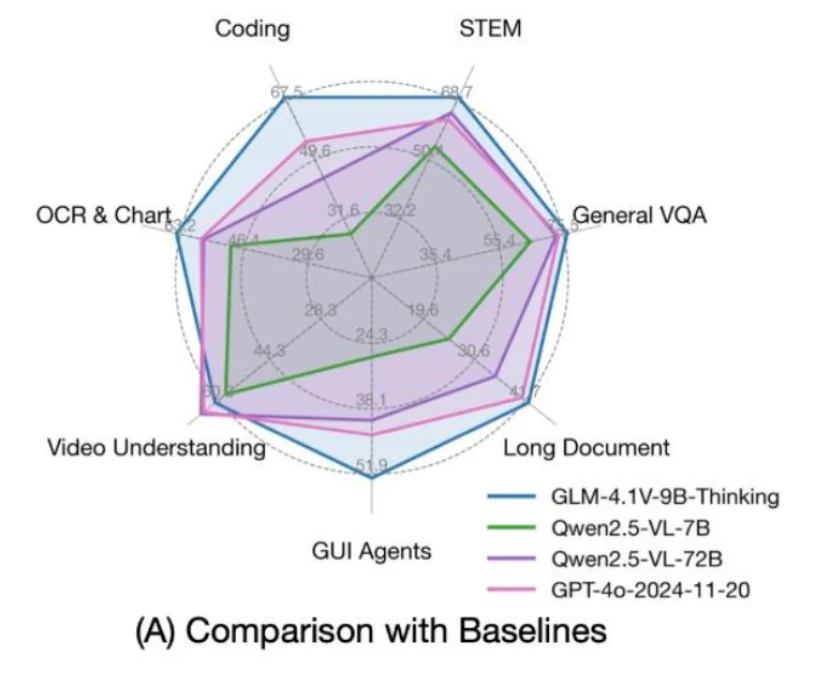
出典THUDM
詳細なハードウェア要件
さらに注目すべきは、GLM 4.1V 9B Thinkingのパラメータ数がわずか90億であることです。そのため、RTX 4090や3090といったコンシューマ向けGPUでもスムーズに動作する軽量さを実現しています。コンパクトなサイズにもかかわらず、GLMはトップレベルの結果を提供し、はるかに大きなモデルの多くを凌駕しています。
推論
| デバイス(シングルGPU) | フレームワーク | 最小メモリ | 速度 | 精度 |
|---|---|---|---|---|
| NVIDIA A100 | transformers | 22GB | 14~22 Tokens / s | BF16 |
| NVIDIA A100 | vLLM | 22GB | 60~70 Tokens / s | BF16 |
ファインチューニング
| デバイス(クラスター) | 戦略 | 最小メモリ / GPU数 | バッチサイズ(GPUあたり) | フリーズ |
|---|---|---|---|---|
| NVIDIA A100 | LORA | 21GB / 1 GPU | 1 | VITをフリーズ |
| NVIDIA A100 | FULL ZERO2 | 280GB / 4 GPU | 1 | VITをフリーズ |
| NVIDIA A100 | FULL ZERO3 | 192GB / 4 GPU | 1 | VITをフリーズ |
| NVIDIA A100 | FULL ZERO2 | 304GB / 4 GPU | 1 | フリーズなし |
| NVIDIA A100 | FULL ZERO3 | 210GB / 4 GPU | 1 | フリーズなし |
他のモデルとのVRAM要件比較
| 特徴 | GLM 4.1V 9B Thinking | Qwen 2.5 VL 72B |
|---|---|---|
| 総VRAM | 22 GB | 640 GB |
| 使用GPU数 | 1 GPU | 8 GPU |
GLM 4.1V 9B ThinkingをサポートするGPUの選び方のヒント
- アーキテクチャ
主要機能、運用効率、システム互換性を決定します。 - CUDA、Tensor、RTコア
モデルのトレーニングと推論の速度、およびグラフィックス性能に影響します。 - VRAMとメモリ帯域幅
扱える最大モデルサイズと、大規模データセット処理時の処理速度に影響します。 - FP8/FP16/FP32/FP64サポート
AIおよび科学アプリケーションにおける計算精度、消費電力、パフォーマンスに影響します。 - 消費電力(TDP)
電気代、冷却要件、ハードウェア計画に影響します。 - NVLink、MIG、ECC
スケーラビリティの向上、信頼性の強化、複数モデルの同時実行を可能にします。 - 理想的なユースケース
GPUがどのようなワークロードに最適かを示します。 - コストと導入
予算とGPUの入手・統合の容易さに影響します。
推奨GPU
| 仕様 | NVIDIA A100 Pcle | NVIDIA RTX 3090 |
|---|---|---|
| アーキテクチャ | Ampere | Ampere |
| 主な用途 | データセンター & HPC | ゲーミング & コンテンツ制作 |
| VRAM | 80 GB HBM2e | 24 GB GDDR6X |
| メモリインターフェース | 5120-bit | 384-bit |
| メモリ帯域幅 | 1,935 GB/s | 936 GB/s |
| CUDAコア | 6,912 | 10,496 |
| Tensorコア | 432(第3世代) | 328(第3世代) |
| RTコア | N/A | 82(第2世代) |
| FP32性能 | 19.5 TFLOPS | 約35.6 TFLOPS |
| Tensor性能 | 624 TFLOPS(FP16/BF16 スパーシティ利用) | 約142 TFLOPS(FP16 スパーシティ利用) |
| システムインターフェース | PCIe 4.0 x16 | PCIe 4.0 x16 |
| NVLinkサポート | あり(600 GB/s ブリッジ) | あり(112.5 GB/s ブリッジ) |
| 最大消費電力 | 300 W | 350 W |
| 特記事項 | MIG、ECC、FP64計算機能 | デスクトップAmpere、NVLink for Gaming |
上記GPUのコストは?
| GPUモデル | 発売時希望小売価格(USD) | 年間電気代(USD) | Novita AIのクラウドGPU |
|---|---|---|---|
| NVIDIA RTX 3090 | $1,499 | $521.22 | $0.21/hr |
| NVIDIA A100 Pcle 80GB | $11,000 | $446.76 | $1.60/hr |
GPUを購入するのは良いアイデアに思えるかもしれませんが、すべてのコストを合計すると、大容量メモリが必要ない場合でも、クラウドGPUの方が安くなることがよくあります。
小規模開発者にはクラウドGPUを選択
簡単に言えば、Novita AIのようなプラットフォームは、高額な初期投資や継続的なメンテナンスなしで強力なGPUを利用できます。この柔軟なアプローチにより、より迅速に実験と構築を進め、日常的なコストを削減し、AI技術の急速な変化に対応できます。
安定性とコスト効率に優れた選択肢:Novita AI
| 提供者 | GPUタイプ | 価格(USD/時間) |
|---|---|---|
| Novita AI | A100 Pcle | $1.60/hr |
| RTX3090 | $0.21/hr | |
| RunPod | A100 Pcle | $1.64/hr |
| RTX3090 | $0.46/hr |
ローカルGPUを選ぶべき場合
1. 継続的な高負荷使用
推論サーバーや定期的なモデルトレーニングなど、GPUを24時間稼働させる必要がある場合、長期的には独自ハードウェアの所有がコスト効率に優れる可能性があります。研究者の中には、RTX 3090がAWSなどのクラウドサービスと比較して約1年で元が取れると指摘する人もいます。
2. 低レイテンシーまたはローカルデータ要件
ロボティクスやエッジ分析などのリアルタイムアプリケーションでは、最小限のレイテンシーが求められます。クラウドソリューションでは必然的にネットワーク遅延が発生しますが、ローカルGPUはこれらの問題を完全に回避できます。
3. 機密性の高いデータや規制対象データの処理
医療や金融などの分野で機密性の高いデータや規制対象データを扱う場合、企業はデータを完全に管理するために、オンプレミスハードウェアまたはプライベートクラウドソリューションを好むことがよくあります。
クラウドGPUを利用するメリット
- コスト削減:使用した分だけ支払えばよく、大規模なハードウェアへの先行投資を避けられます。
- スケーラビリティ:ワークロードの増大に応じて、より多くの(またはより強力な)GPUに即座にアクセスできます。
- 柔軟性:必要に応じて、異なるGPUタイプや構成に簡単に切り替えられます。
- メンテナンス不要:ハードウェアの故障、アップデート、冷却などはクラウドプロバイダーに任せられるため、時間と手間を節約できます。
- グローバルアクセス:どこからでも作業でき、世界中のチームとコラボレーションできます。
- 迅速なイノベーション:ハードウェアの納品やセットアップを待つことなく、プロジェクトをすぐに開始し、実験できます。
Novita AIのようなクラウドGPUでGLM 4.1V 9B Thinkingにアクセスする方法
ステップ1:アカウント登録
Novita AIが初めての方は、まず当社ウェブサイトでアカウントを作成してください。登録後、「GPUs」タブに移動して、利用可能なリソースを確認し、旅を始めましょう。

ステップ2:テンプレートとGPUサーバーの探索
まず、プロジェクトのニーズに合ったテンプレート(PyTorch、TensorFlow、CUDAなど)を選択します。必要なバージョン(例:PyTorch 2.2.1、CUDA 11.8.0)を選びます。次に、A100 GPUサーバー構成を選択します。これは、十分なVRAM、RAM、ディスク容量を備え、要求の厳しいワークロードを処理する高性能を提供します。

ステップ3:デプロイメントのカスタマイズ
テンプレートとGPUを選択したら、オペレーティングシステムのバージョン(CUDA 11.8など)などのパラメータを調整して、デプロイ設定をカスタマイズします。その他の構成も調整して、環境をプロジェクトの特定の要件に合わせることができます。
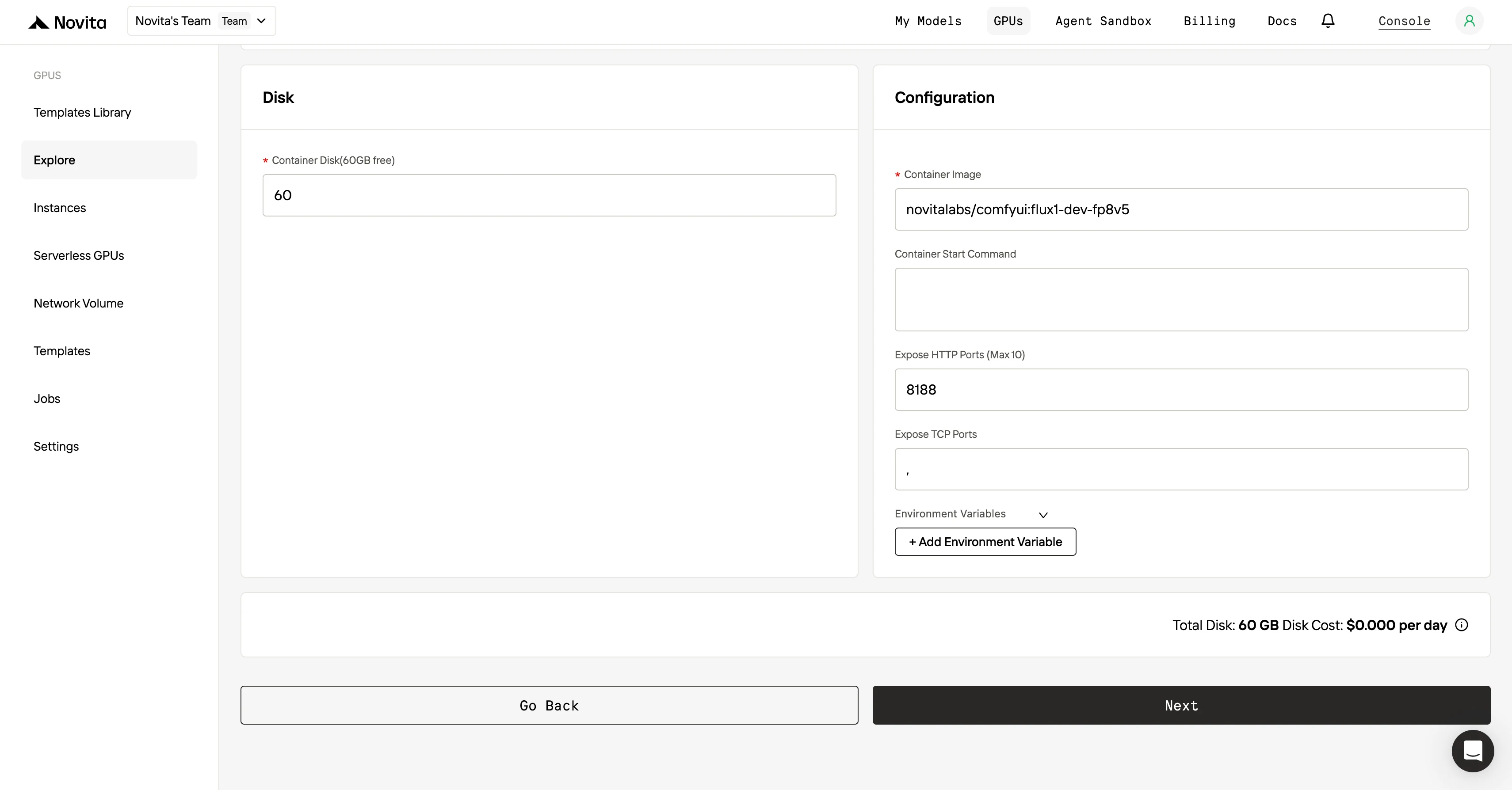
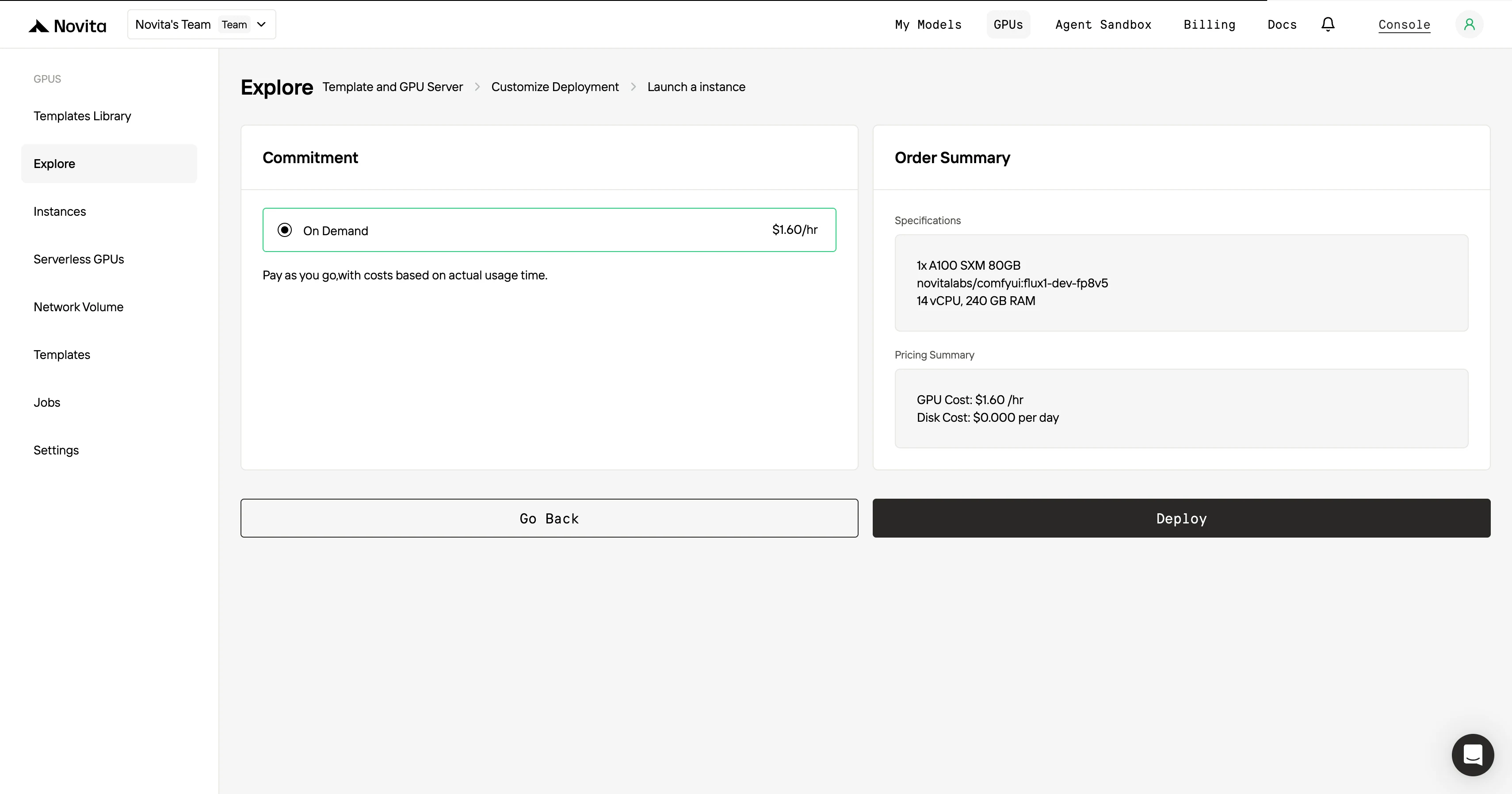
ステップ4:インスタンスの起動
テンプレートとデプロイ設定が完了したら、「Launch Instance」をクリックしてGPUインスタンスをセットアップします。これで環境のセットアップが開始され、AIタスクにGPUリソースを使用できるようになります。
最大の効率と利便性を求めるなら、APIを選択!
Novita AIは、65536コンテキスト ** のGLM 4.1V 9B Thinking APIを提供しており、コストは入力$0.035**、** 出力$0.138**です。
出典:Openrouter
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ2:モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。
ステップ3:無料トライアルを開始
選択したモデルの機能を探索するために、無料トライアルを開始します。
ステップ4:APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「Settings」ページに移動し、画像のようにAPIキーをコピーします。

ステップ5:APIをインストール
プログラミング言語に適したパッケージマネージャーを使用してAPIをインストールします。
インストール後、必要なライブラリを開発環境にインポートします。APIキーでAPIを初期化して、Novita AI LLMとの対話を開始します。以下は、Pythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_kgNdXtDPt2zYc95i-nDWPaW4Zl_e7nf4VDpukuIVBKpko1-LE8xCasG4YK7c-3c1xnPzGYRuocFk_DhkPUUQyQ==",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # or False
max_tokens = 4000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GLM 4.1V 9B Thinkingは、視覚言語推論の新たな基準を打ち立てています。最小VRAM要件は22GB(推論時)で、RTX 3090や4090などのコンシューマ向けGPUでもスムーズに動作します。これはサーバー級のハードウェアを必要とする巨大モデルよりもはるかにアクセスしやすいですが、それでもこれらのGPUの高価格、消費電力、冷却やシステムアップグレードの可能性を考慮する必要があります。ほとんどの開発者にとって、GLM 4.1V 9B Thinkingにアクセスするには、クラウドGPUが最も柔軟でコスト効率の高い選択肢であり続けます。
よくある質問
GLM 4.1V 9B Thinkingをローカルで実行するには、どれくらいのVRAMが必要ですか?
推論には少なくとも 22GBのVRAM が必要です。つまり、1枚のRTX 3090、4090、またはそれに相当するGPUで十分です。
ローカルGPUを購入するのはどのような場合に意味がありますか?
GPUをほぼ常時稼働させる場合、超低レイテンシーが必要な場合、または機密データを扱うためデータを外部に持ち出せない場合です。
GLM 4.1V 9B Thinkingを最も簡単に使う方法は?
Novita AI などのクラウドプロバイダーを利用し、API経由でモデルにアクセスすることです。ハードウェア、セットアップ、継続的なメンテナンスを心配する必要はありません。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできると同時に、手頃で信頼性の高いGPUクラウドを提供するAIクラウドプラットフォームです。スケーリングと構築を支援します。



