

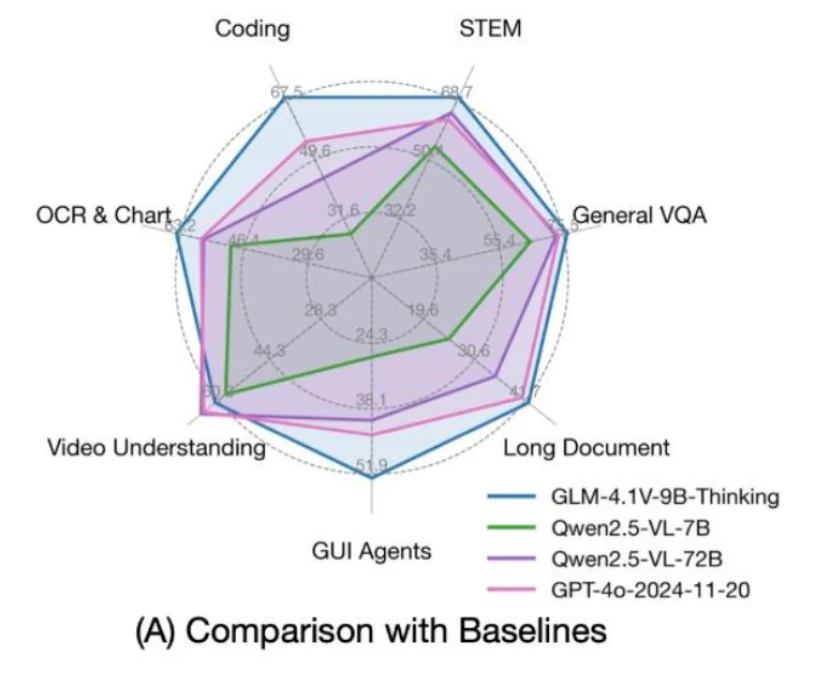
GLM 4.1V 9B Thinking — первая в мире модель «зрения-язык» с цепочкой рассуждений (CoT). Если вы рассматриваете локальное развёртывание, ключевой вопрос: сколько VRAM потребуется и какие дополнительные расходы могут возникнуть?
Требования GLM 4.1V 9B Thinking к видеопамяти
Построенная на базе GLM 4 9B 0414, модель GLM 4.1V 9B Thinking нацелена на развитие способностей к рассуждению в мультимодальном ИИ. Благодаря новому подходу «сначала думать» и использованию методов обучения с подкреплением эта модель выводит понимание изображений и текста на новый уровень. Будучи пионером среди моделей «зрение-язык», поддерживающих цепочку рассуждений (CoT), GLM 4.1V 9B Thinking устанавливает новый стандарт для сложных рассуждений как по тексту, так и по изображениям.
ИзTHUDM
Детальные требования к оборудованию
Что ещё более примечательно, GLM 4.1V 9B Thinking имеет всего 9 миллиардов параметров, что делает её достаточно лёгкой для плавной работы даже на потребительских GPU, таких как RTX 4090 или RTX 3090. Несмотря на компактный размер, GLM демонстрирует результаты топ-уровня, превосходя многие значительно более крупные модели.
Инференс
| Устройство (одна GPU) | Фреймворк | Мин. память | Скорость | Точность |
|---|---|---|---|---|
| NVIDIA A100 | transformers | 22 ГБ | 14–22 токенов/с | BF16 |
| NVIDIA A100 | vLLM | 22 ГБ | 60–70 токенов/с | BF16 |
Тонкая настройка (Fine-tuning)
| Устройство (кластер) | Стратегия | Мин. память / кол-во GPU | Размер батча (на GPU) | Заморозка |
|---|---|---|---|---|
| NVIDIA A100 | LORA | 21 ГБ / 1 GPU | 1 | Freeze VIT |
| NVIDIA A100 | FULL ZERO2 | 280 ГБ / 4 GPU | 1 | Freeze VIT |
| NVIDIA A100 | FULL ZERO3 | 192 ГБ / 4 GPU | 1 | Freeze VIT |
| NVIDIA A100 | FULL ZERO2 | 304 ГБ / 4 GPU | 1 | Без заморозки |
| NVIDIA A100 | FULL ZERO3 | 210 ГБ / 4 GPU | 1 | Без заморозки |
Сравнение требований к VRAM с другими моделями
| Характеристика | GLM 4.1V 9B Thinking | Qwen 2.5 VL 72B |
|---|---|---|
| Общий объём VRAM | 22 ГБ | 640 ГБ |
| Используемые GPU | 1 GPU | 8 GPU |
Советы по выбору GPU для работы с GLM 4.1V 9B Thinking
- Архитектура — определяет ключевые особенности, эффективность работы и совместимость с системой.
- Ядра CUDA, Tensor и RT — влияют на скорость обучения и инференса модели, а также на производительность графики.
- VRAM и пропускная способность памяти — влияют на максимальный размер модели, с которым вы можете работать, и скорость обработки больших объёмов данных.
- Поддержка FP8/FP16/FP32/FP64 — влияет на точность вычислений, энергопотребление и производительность для ИИ и научных приложений.
- Энергопотребление (TDP) — влияет на затраты на электроэнергию, требования к охлаждению и планирование оборудования.
- NVLink, MIG, ECC — обеспечивают лучшую масштабируемость, повышенную надёжность и поддержку одновременного запуска нескольких моделей.
- Идеальные сценарии использования — указывают, для каких типов нагрузок GPU подходит лучше всего.
- Стоимость и развёртывание — влияет на бюджет considerations и доступность GPU.
Рекомендуемые GPU
| Характеристика | NVIDIA A100 Pcle | NVIDIA RTX 3090 |
|---|---|---|
| Архитектура | Ampere | Ampere |
| Основное применение | ЦОД и HPC | Игры и создание контента |
| VRAM | 80 ГБ HBM2e | 24 ГБ GDDR6X |
| Интерфейс памяти | 5120-битный | 384-битный |
| Пропускная способность памяти | 1 935 ГБ/с | 936 ГБ/с |
| Ядра CUDA | 6 912 | 10 496 |
| Tensor Cores | 432 (3-го поколения) | 328 (3-го поколения) |
| RT Cores | Н/Д | 82 (2-го поколения) |
| Производительность FP32 | 19.5 TFLOPS | ~35.6 TFLOPS |
| Производительность Tensor | 624 TFLOPS (FP16/BF16 с разреженностью) | ~142 TFLOPS (FP16 с разреженностью) |
| Системный интерфейс | PCIe 4.0 x16 | PCIe 4.0 x16 |
| Поддержка NVLink | Да (мост 600 ГБ/с) | Да (мост 112.5 ГБ/с) |
| Максимальное энергопотребление | 300 Вт | 350 Вт |
| Особые возможности | MIG, ECC, FP64 | Desktop Ampere, NVLink для игр |
Сколько стоят указанные GPU?
| Модель GPU | Стартовая цена (USD) | Стоимость электроэнергии за 1 год (USD) | Облачный GPU на Novita AI |
|---|---|---|---|
| NVIDIA RTX 3090 | $1,499 | $521.22 | $0.21/ч |
| NVIDIA A100 Pcle 80ГБ | $11,000 | $446.76 | $1.60/ч |
Посмотреть другие цены на облачные GPU
Покупка собственного GPU может показаться хорошей идеей, но при учёте всех затрат использование облачных GPU часто оказывается дешевле — даже если вам не нужны огромные объёмы памяти.
Для небольших разработчиков выбирайте облачный GPU
Проще говоря, такие платформы, как Novita AI, позволяют получить доступ к мощным GPU без высоких первоначальных затрат и постоянного обслуживания. Этот гибкий подход помогает быстрее экспериментировать и создавать продукты, сокращать ежедневные расходы и не отставать от стремительных изменений в области ИИ.
Стабильный и высокорентабельный вариант: Novita AI
| Провайдер | Тип GPU | Цена (USD/ч) |
|---|---|---|
| Novita AI | A100 Pcle | $1.60/ч |
| RTX3090 | $0.21/ч | |
| RunPod | A100 Pcle | $1.64/ч |
| RTX3090 | $0.46/ч |
Когда стоит выбирать локальный GPU
1. Постоянная интенсивная нагрузка
Если GPU требуется круглосуточно (например, для серверов инференса или регулярного обучения моделей), собственное оборудование может быть более выгодным в долгосрочной перспективе. Некоторые исследователи обнаружили, что RTX 3090 может окупиться по сравнению с облачными сервисами, такими как AWS, примерно за год.
2. Низкая задержка или требования к локальным данным
Приложения реального времени, такие как робототехника или периферийная аналитика, требуют минимальной задержки. Облачные решения неизбежно вносят сетевые задержки, которых можно полностью избежать с помощью локальных GPU.
3. Работа с конфиденциальными или регулируемыми данными
При работе с высокочувствительными или регулируемыми данными (например, в медицинской или финансовой сфере) компании часто предпочитают локальное оборудование или частные облачные решения для полного контроля над данными.
Что вы получаете, используя облачные GPU?
- Экономия средств: платите только за то, что используете, избегая крупных первоначальных вложений в оборудование.
- Масштабируемость: мгновенно получайте доступ к большему количеству (или более мощных) GPU по мере роста нагрузки.
- Гибкость: легко переключайтесь между различными типами и конфигурациями GPU в соответствии с вашими потребностями.
- Отсутствие обслуживания: экономьте время и силы, позволяя облачному провайдеру заниматься аппаратными сбоями, обновлениями и охлаждением.
- Глобальный доступ: работайте из любой точки мира и сотрудничайте с командами по всему земному шару.
- Более быстрые инновации: быстро запускайте проекты и экспериментируйте без ожидания доставки или настройки оборудования.
Как получить доступ к GLM 4.1V 9B Thinking на облачном GPU, таком как Novita AI?
Шаг 1: Зарегистрируйте аккаунт
Если вы новичок в Novita AI, создайте аккаунт на нашем сайте. После регистрации перейдите на вкладку «GPUs», чтобы изучить доступные ресурсы и начать работу.

Попробуйте высокопроизводительные GPU Novita AI
Шаг 2: Изучите шаблоны и GPU-серверы
Начните с выбора шаблона, соответствующего потребностям вашего проекта, например PyTorch, TensorFlow или CUDA. Выберите подходящую версию, например PyTorch 2.2.1 или CUDA 11.8.0. Затем выберите конфигурацию GPU-сервера A100, который обеспечивает высокую производительность для работы с требовательными задачами, имея достаточный объём VRAM, RAM и дискового пространства.

Шаг 3: Настройте развёртывание
После выбора шаблона и GPU настройте параметры развёртывания, отрегулировав такие параметры, как версия операционной системы (например, CUDA 11.8). Вы также можете изменить другие конфигурации, чтобы адаптировать среду под конкретные требования вашего проекта.
Шаг 4: Запустите инстанс
После того как вы окончательно настроили шаблон и параметры развёртывания, нажмите «Launch Instance», чтобы создать инстанс GPU. Это запустит настройку среды, позволяя начать использование GPU-ресурсов для ваших задач ИИ.
Для максимальной эффективности и удобства выбирайте API!
Novita AI предоставляет API для GLM 4.1V 9B Thinking с контекстом 65536 и стоимостью $0.035/вход и $0.138/выход.
Источник: Openrouter
Шаг 1: Войдите в систему и откройте библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Model Library.

Попробуйте GLM 4.1V 9B сейчас!
Шаг 2: Выберите модель
Просмотрите доступные варианты и выберите модель, которая подходит для ваших нужд.
Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Шаг 4: Получите API-ключ
Для аутентификации в API мы предоставим новый API-ключ. Перейдя на страницу «Settings», вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с помощью вашего API-ключа, чтобы начать взаимодействие с языковой моделью Novita AI. Пример использования chat completions API для пользователей Python:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_kgNdXtDPt2zYc95i-nDWPaW4Zl_e7nf4VDpukuIVBKpko1-LE8xCasG4YK7c-3c1xnPzGYRuocFk_DhkPUUQyQ==",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # or False
max_tokens = 4000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GLM 4.1V 9B Thinking устанавливает новый стандарт для визуально-языковых рассуждений. С минимальными требованиями к VRAM 22 ГБ (для инференса) модель плавно работает на потребительских GPU, таких как RTX 3090 или 4090. Хотя это гораздо доступнее, чем гигантские модели, требующие серверного оборудования, необходимо учитывать высокую стоимость таких GPU, энергопотребление, а также возможное обновление системы или охлаждения. Для большинства разработчиков облачные GPU остаются наиболее гибким и экономически эффективным выбором для доступа к GLM 4.1V 9B Thinking.
Часто задаваемые вопросы
Сколько VRAM нужно для локального запуска GLM 4.1V 9B Thinking?
Для инференса требуется как минимум 22 ГБ VRAM. Это означает, что достаточно одного RTX 3090, 4090 или аналогичного GPU.
Когда имеет смысл покупать локальный GPU?
Если ваш GPU будет загружен почти всё время, или вам нужна сверхнизкая задержка, или вы работаете с конфиденциальными данными, которые не могут покинуть ваше помещение.
Какой самый простой способ использовать GLM 4.1V 9B Thinking?
Используйте облачного провайдера, например Novita AI, и обращайтесь к модели через API — не нужно беспокоиться об оборудовании, настройке или постоянном обслуживании.
Novita AI — это облачная платформа ИИ, которая предоставляет разработчикам лёгкий способ развёртывания моделей с помощью простого API, а также предлагает доступный и надёжный облачный GPU для создания и масштабирования продуктов.



