

Key Highlights
The Benefits of Using an API:
Avoid Network Errors: Overcome downtime caused by high traffic (as seen in DeepSeek’s recent app issues) by relying on scalable API infrastructure.
Eliminate Local Deployment Hassles: Bypass the need for high-end GPUs, complex installations, and memory constraints.
How to Choose an API Provider:
Max Output: Prioritize providers supporting ≥8k tokens for long-form tasks.
Cost Efficiency: Compare input and output costs.
Latency: Critical for real-time apps
Throughput: Ensure high concurrency
Top 3 API Providers of DeepSeek R1:
Novita AI, Minimax,Nebius AI
Novita AI launches high-performance Deepseek R1/V3 Turbo! 3x improved throughput performance, limited-time 20% discount
In today’s rapidly evolving AI landscape, choosing the right API provider is essential for effectively utilizing advanced language models. With the emergence of massive models like DeepSeek, local deployment has become difficult and cost-prohibitive. Accessing these models through APIs not only avoids hardware investment and technical configuration issues but also ensures stable and reliable service. This article explores the main benefits of choosing APIs, analyzes how to evaluate different providers, and introduces the leading DeepSeek R1 API services available in the market.
The Benefits of Using an API
Avoid Network Errors Due to Huge Traffic
Recently, the DeepSeek app has experienced significant disruptions due to overwhelming user demand, resulting in extended downtime and inconsistent performance. This situation underscores the critical importance of selecting a robust API provider that can guarantee reliable, uninterrupted access to DeepSeek R1’s powerful capabilities even during peak usage periods.
from Reddit
Avoid Trouble of Accessing Locally
The formidable size of DeepSeek R1 creates substantial barriers to local implementation. Running this model effectively requires exceptional computing resources—specifically, a minimum configuration of 8x H100 GPUs, representing a significant hardware investment. By utilizing API services instead, you can seamlessly harness the model’s full potential without concerns about hardware specifications, complex installation procedures, technical configurations, or memory constraints.
from Reddit
How to Choose an API Provider (4 metrics)
| Metric | Definition | High/Low Impact |
|---|---|---|
| Max Output | Maximum tokens the model can generate in a single response. | Higher = Better |
| Input Cost | Cost per million input tokens processed (e.g., user prompts, context). | Lower = Better |
| Output Cost | Cost per million output tokens generated (e.g., model responses). | Lower = Better |
| Latency | Time delay between sending a request and receiving the first response byte. | Lower = Better |
| Throughput | Number of requests processed per second (system capacity). | Higher = Better |
Besides, you can focus on different metrics depending on your uses cases.
| Application Type | Example Use Cases | Priority Dimensions (Ranked) |
|---|---|---|
| Real-Time Applications | Customer support, chatbots, live translation | 1. Latency (<500ms) 2. Throughput (100+ req/sec) 3. Cost (secondary except at scale) |
| Long-Form Content Generation | Reports, article writing, code generation | 1. Max Output (≥8k tokens) 2. Output Cost ($1.10/million tokens) 3. Latency (2-3s acceptable) |
| Cost-Sensitive Batch Processing | Bulk summarization, data labeling | 1. Input Cost ($0.07/million tokens) 2. Throughput (1k+ req/hour) 3. Max Output (lower priority) |
| Multimodal/Complex Reasoning | Financial forecasting, medical diagnosis | 1. Model Capability (accuracy) 2. Max Output (detailed reasoning) 3. Latency (10s+ acceptable) |
| Edge/On-Device Deployment | IoT devices, mobile apps | 1. Latency (<200ms) 2. Throughput (lightweight models) 3. Cost (less important) |
Top 3 API Providers of DeepSeek R1
| Provider for DeepSeek R1 | Context | Max Output | Input Cost | Output Cost | Throughput |
|---|---|---|---|---|---|
| Minimax | 64K | 64K | $0.55 | $2.19 | 19.83 t/s |
| Novita AI Turbo | 64K | 16K | $0.7 | $2.5 | 30 tokens/s |
| Nebius AI Studio | 128K | 128K | $0.8 | $2.4 | 13.20 t/s |
1.Novita AI
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.

Why Choose it?
- Development Efficiency: Access extensive library of pre-integrated multimodal models, featuring industry leaders like DeepSeek V3, DeepSeek R1, Llama 3.3 70B, Qwen 2.5, QWQ, and dozens more cutting-edge options.
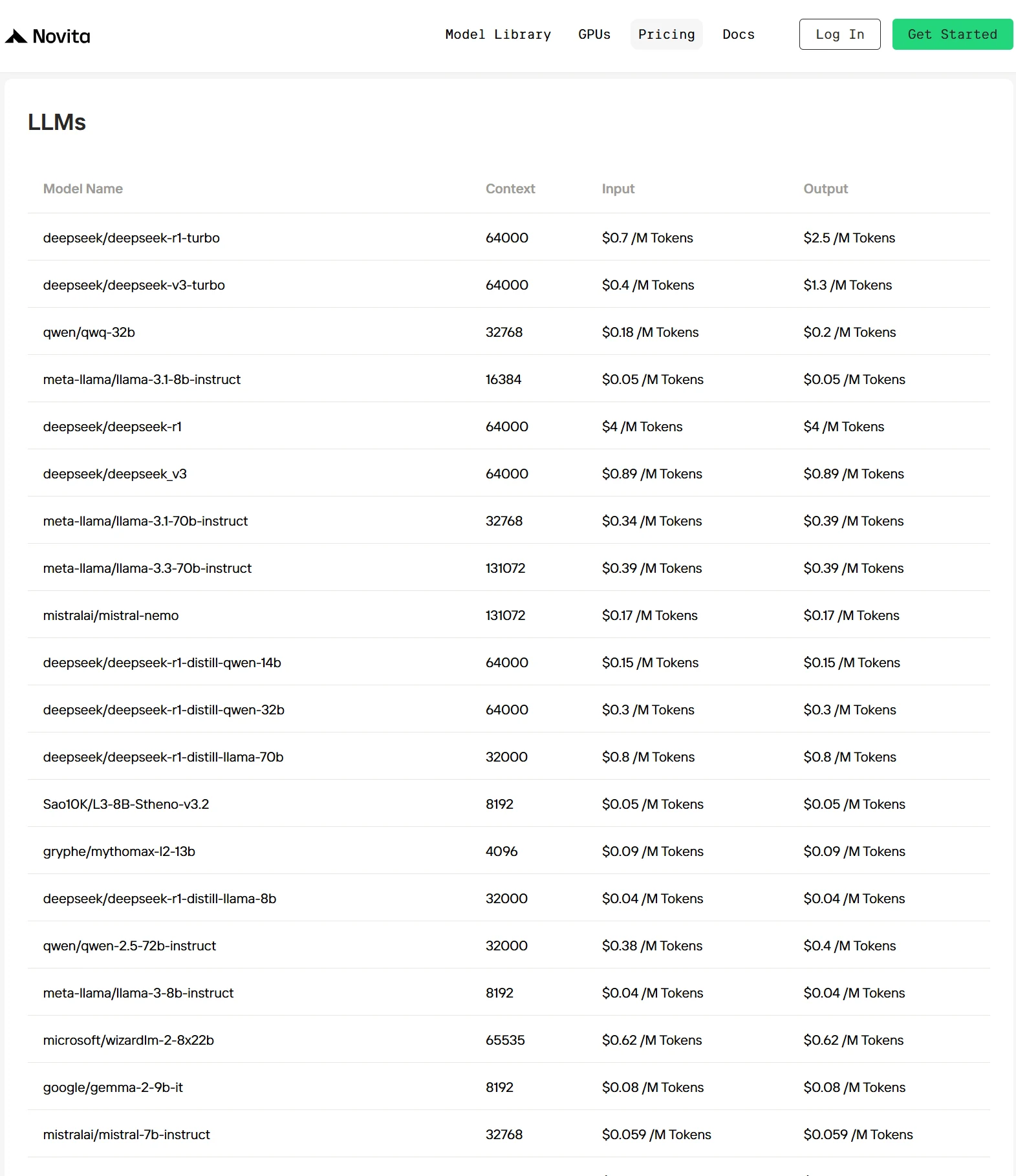
- Cost Advantage: Superior Economics Without Performance Compromise
Similar to Deepseek R1 and Deepseek V3, Novita AI launches a Turbo version with 3x throughput and a limited-time 20% discount!

How to Access Deepseek R1 through it?
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Try DeepSeek R1 Turbo Demo Now!
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-r1-turbo"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Upon registration, Novita AI provides a $0.5 credit to get you started!
If the free credits is used up, you can pay to continue using it.
2.Minimax
MiniMax, a pioneering Asian tech leader, delivers exceptional multimodal AI capabilities through proprietary models spanning text, speech, music, image, and video, powering global applications for millions of users and 40,000+ enterprises worldwide.

Why Choose it?
- Unparalleled Multimodality: MiniMax delivers exceptional AI across text, speech, music, image, and video through proprietary models like Linear Attention LLMs and the acclaimed Hailuo video system.
- Industry-Disrupting Economics: Offering premium AI at fraction of competitor costs—MiniMax delivers R1-caliber (671B parameter) performance at just $0.55/$2.19 per million tokens with generous 64K context windows and high throughput.
How to Access Deepseek R1 through it?
Generate a model response using the chat endpoint of Deepseek-R1.
curl --location "https://api.minimaxi.chat/v1/text/chatcompletion_v2" \
--header "Content-Type: application/json" \
--header "Authorization: Bearer $MiniMax_API_KEY" \
--data '{
"model":"DeepSeek-R1",
"messages":[
{
"role":"system",
"name":"MM Intelligent Assistant",
"content":"MM Intelligent Assistant is a large language model that is self-developed by MiniMax and does not call the interface of other products. "
},
{
"role":"user",
"name":"user",
"content":"Hello"
}
]
}'3.Nebius AI
Nebius is a comprehensive AI development platform offering seamless model building, fine-tuning, and deployment on premium NVIDIA® GPUs with industry-leading efficiency and performance.

Why Choose it?
Powerhouse Infrastructure: Nebius’s AI-native cloud platform harnesses cutting-edge NVIDIA H100/H200 GPUs connected via InfiniBand networks, delivering exceptional model fine-tuning and expansion capabilities alongside flexible APIs for high-performance, low-latency data processing and application deployment.

How to Access Deepseek R1 through it?
Generate a model response using the chat endpoint of Deepseek R1.
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1",
max_tokens=8192,
temperature=0.6,
top_p=0.95,
messages=[]
)
print(response.to_json())In conclusion, Choosing the right API provider for DeepSeek R1 is crucial for efficient and cost-effective AI development. By understanding the benefits of using an API and carefully considering factors such as output length, cost, latency, and throughput, you can select a provider that best fits your needs.
Frequently Asked Questions
What hardware is required to run DeepSeek R1 locally?
At minimum, 8x NVIDIA H100 GPUs are required for local deployment.
How does DeepSeek R1 compare to other models?
It outperforms many open-source models and rivals proprietary models like GPT-4 in reasoning and coding tasks.
What are DeepSeek R1’s main capabilities?
Advanced reasoning, mathematics, coding, and multi-step problem-solving.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.



