

Destaques Principais
Os Benefícios de Usar uma API:
Evite Erros de Rede: Supere paralisações causadas por alto tráfego (como visto nos recentes problemas do aplicativo DeepSeek) confiando em infraestrutura de API escalável.
Elimine Dificuldades de Implantação Local: Dispense a necessidade de GPUs de alto desempenho, instalações complexas e limitações de memória.
Como Escolher um Provedor de API:
Saída Máxima: Priorize provedores que suportem ≥8k tokens para tarefas de texto longo.
Eficiência de Custo: Compare custos de entrada e saída.
Latência: Crítica para aplicações em tempo real
Taxa de Transferência: Garanta alta concorrência
Top 3 Provedores de API do DeepSeek R1:
Novita AI, Minimax, Nebius AI
A Novita AI lança o Deepseek R1/V3 Turbo de alto desempenho! 3x mais desempenho de taxa de transferência, desconto limitado de 20% por tempo limitado
No cenário atual de IA em rápida evolução, escolher o provedor de API certo é essencial para utilizar eficazmente modelos de linguagem avançados. Com o surgimento de modelos massivos como o DeepSeek, a implantação local se tornou difícil e proibitivamente cara. Acessar esses modelos por meio de APIs não apenas evita investimentos em hardware e problemas de configuração técnica, mas também garante um serviço estável e confiável. Este artigo explora os principais benefícios de escolher APIs, analisa como avaliar diferentes provedores e apresenta os principais serviços de API DeepSeek R1 disponíveis no mercado.
Os Benefícios de Usar uma API
Evite Erros de Rede Devido ao Tráfego Intenso
Recentemente, o aplicativo DeepSeek sofreu interrupções significativas devido à demanda esmagadora dos usuários, resultando em longos períodos de inatividade e desempenho inconsistente. Essa situação destaca a importância crítica de selecionar um provedor de API robusto que possa garantir acesso confiável e ininterrupto às poderosas capacidades do DeepSeek R1, mesmo durante períodos de pico de uso.
do Reddit
Evite Problemas de Acesso Local
O tamanho formidável do DeepSeek R1 cria barreiras substanciais para a implementação local. Executar este modelo de forma eficaz requer recursos computacionais excepcionais — especificamente, uma configuração mínima de 8x GPUs H100, representando um investimento significativo em hardware. Ao utilizar serviços de API, você pode aproveitar perfeitamente todo o potencial do modelo sem se preocupar com especificações de hardware, procedimentos complexos de instalação, configurações técnicas ou limitações de memória.
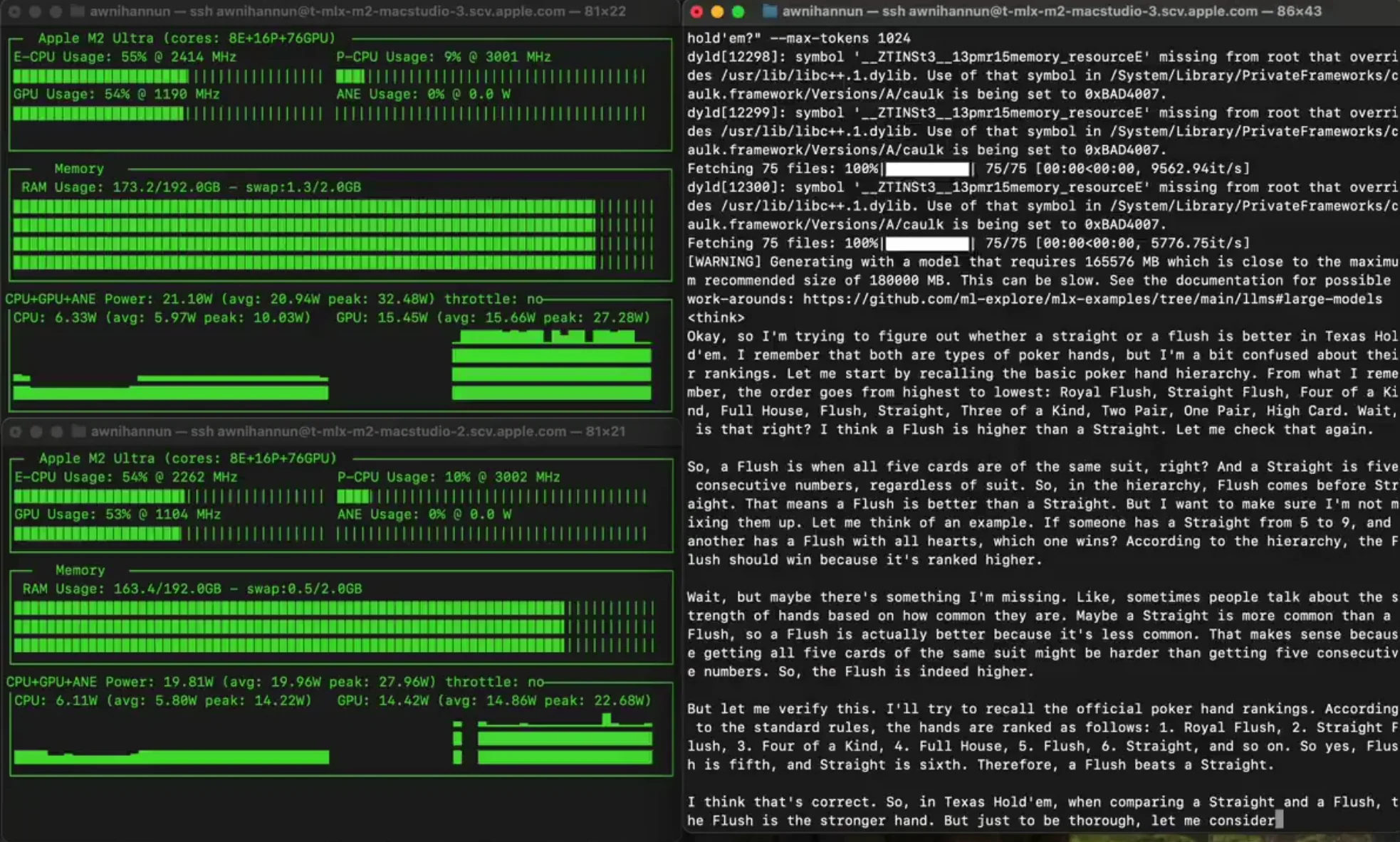
do Reddit
Como Escolher um Provedor de API (4 métricas)
| Métrica | Definição | Impacto Alto/Baixo |
|---|---|---|
| Saída Máxima | Máximo de tokens que o modelo pode gerar em uma única resposta. | Maior = Melhor |
| Custo de Entrada | Custo por milhão de tokens de entrada processados (ex.: prompts do usuário, contexto). | Menor = Melhor |
| Custo de Saída | Custo por milhão de tokens de saída gerados (ex.: respostas do modelo). | Menor = Melhor |
| Latência | Atraso de tempo entre o envio de uma solicitação e o recebimento do primeiro byte de resposta. | Menor = Melhor |
| Taxa de Transferência | Número de solicitações processadas por segundo (capacidade do sistema). | Maior = Melhor |
Além disso, você pode focar em métricas diferentes dependendo dos seus casos de uso.
| Tipo de Aplicação | Exemplos de Casos de Uso | Dimensões Prioritárias (Ordenadas) |
|---|---|---|
| Aplicações em Tempo Real | Suporte ao cliente, chatbots, tradução ao vivo | 1. Latência (<500ms) 2. Taxa de Transferência (100+ req/s) 3. Custo (secundário exceto em escala) |
| Geração de Conteúdo Longo | Relatórios, redação de artigos, geração de código | 1. Saída Máxima (≥8k tokens) 2. Custo de Saída ($1,10/milhão de tokens) 3. Latência (2-3s aceitável) |
| Processamento em Lote Sensível a Custo | Resumo em massa, rotulagem de dados | 1. Custo de Entrada ($0,07/milhão de tokens) 2. Taxa de Transferência (1k+ req/hora) 3. Saída Máxima (prioridade menor) |
| Raciocínio Multimodal/Complexo | Previsões financeiras, diagnóstico médico | 1. Capacidade do Modelo (precisão) 2. Saída Máxima (raciocínio detalhado) 3. Latência (10s+ aceitável) |
| Implantação em Borda/Dispositivo | Dispositivos IoT, aplicativos móveis | 1. Latência (<200ms) 2. Taxa de Transferência (modelos leves) 3. Custo (menos importante) |
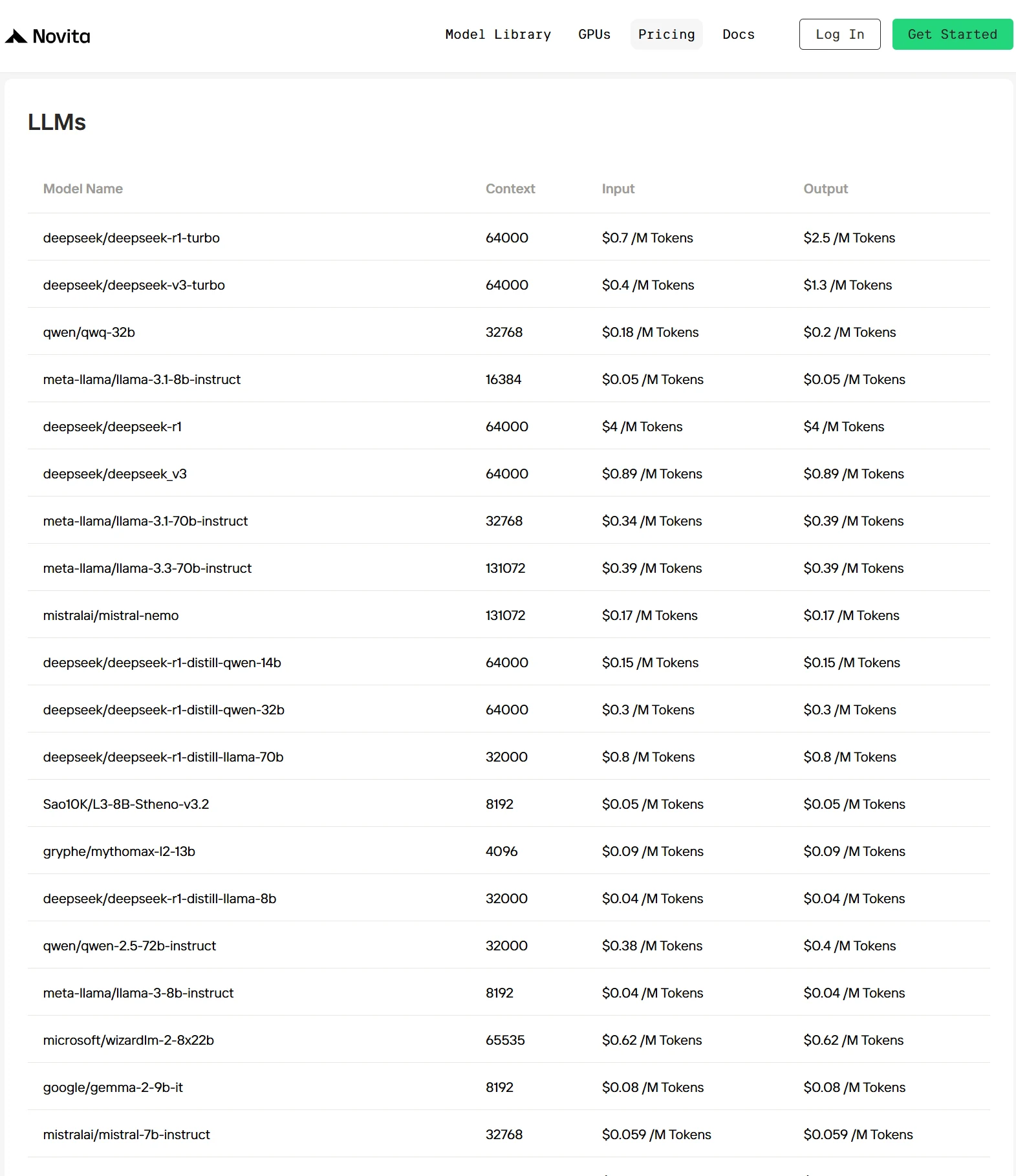
Top 3 Provedores de API do DeepSeek R1
| Provedor para DeepSeek R1 | Contexto | Saída Máxima | Custo de Entrada | Custo de Saída | Taxa de Transferência |
|---|---|---|---|---|---|
| Minimax | 64K | 64K | $0,55 | $2,19 | 19,83 t/s |
| Novita AI Turbo | 64K | 16K | $0,7 | $2,5 | 30 tokens/s |
| Nebius AI Studio | 128K | 128K | $0,8 | $2,4 | 13,20 t/s |
1.Novita AI
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer nuvem de GPU acessível e confiável para construir e escalar.

Por que Escolhê-la?
- Eficiência de Desenvolvimento: Acesse uma extensa biblioteca de modelos multimodais pré-integrados, apresentando líderes do setor como DeepSeek V3, DeepSeek R1, Llama 3.3 70B, Qwen 2.5, QWQ e dezenas de outras opções de ponta.
- Vantagem de Custo: Economia Superior Sem Compromisso de Desempenho
Semelhante ao Deepseek R1 e Deepseek V3, a Novita AI lança uma versão Turbo com taxa de transferência 3x maior e um desconto limitado de 20% por tempo limitado!

Como Acessar o Deepseek R1 através dela?
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Experimente o DeepSeek R1 Turbo Demo Agora!
Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
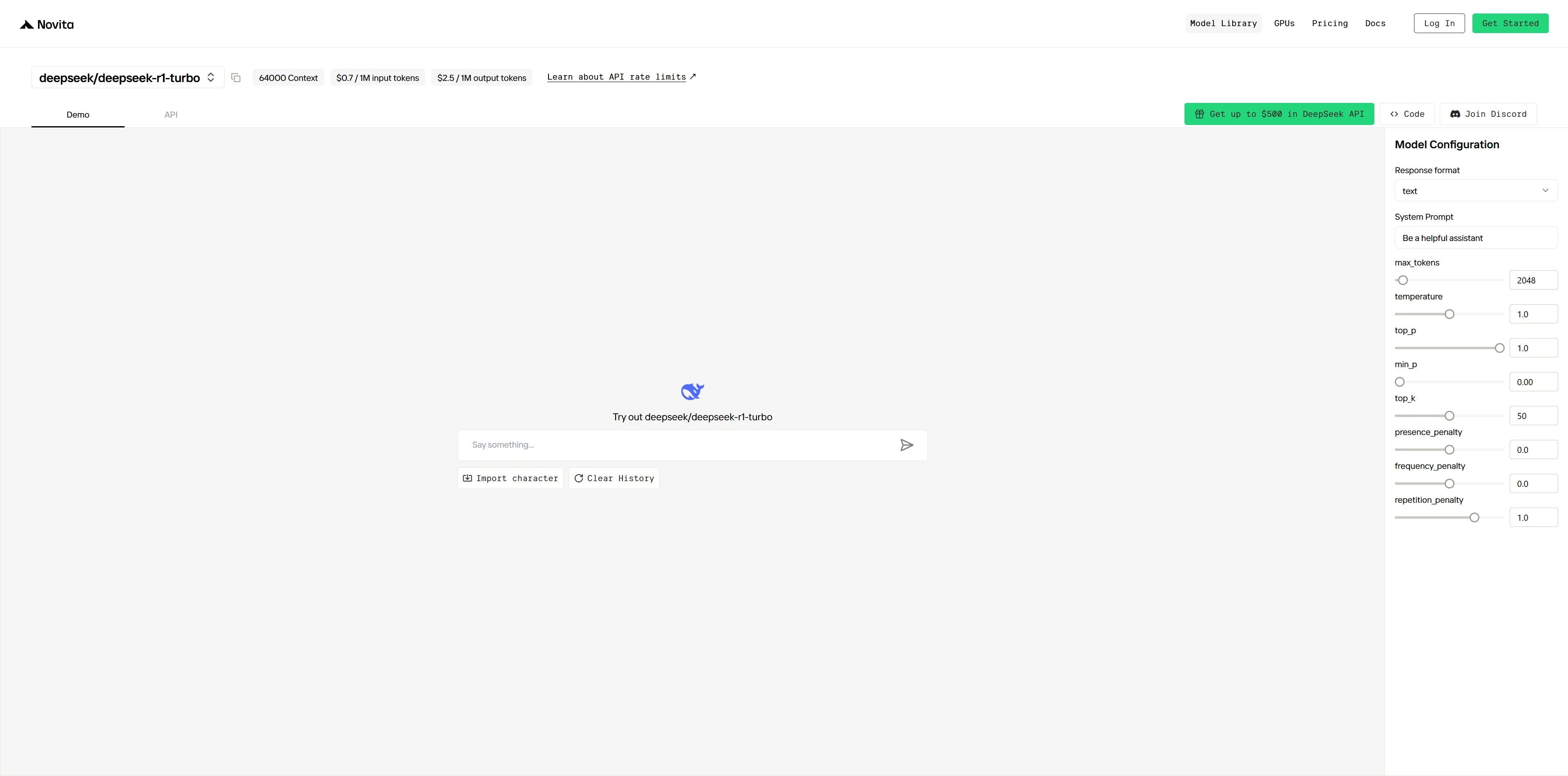
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acessando a página “Settings”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o Novita AI LLM. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<SUA Chave de API Novita AI>",
)
model = "deepseek/deepseek-r1-turbo"
stream = True # or False
max_tokens = 2048
system_content = """Seja um assistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Olá!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Ao se registrar, a Novita AI fornece um crédito de $0,5 para você começar!
Se os créditos gratuitos forem usados, você pode pagar para continuar usando.
2.Minimax
MiniMax, um líder pioneiro em tecnologia asiática, oferece capacidades multimodais de IA excepcionais por meio de modelos proprietários que abrangem texto, fala, música, imagem e vídeo, impulsionando aplicações globais para milhões de usuários e mais de 40.000 empresas em todo o mundo.

Por que Escolhê-lo?
- Multimodalidade Inigualável: MiniMax oferece IA excepcional em texto, fala, música, imagem e vídeo por meio de modelos proprietários como LLMs de Atenção Linear e o aclamado sistema de vídeo Hailuo.
- Economia Inovadora: Oferecendo IA premium a uma fração dos custos dos concorrentes — MiniMax entrega desempenho de nível R1 (671B parâmetros) por apenas $0,55/$2,19 por milhão de tokens, com janelas de contexto generosas de 64K e alta taxa de transferência.
Como Acessar o Deepseek R1 através dele?
Gere uma resposta do modelo usando o endpoint de chat do Deepseek-R1.
curl --location "https://api.minimaxi.chat/v1/text/chatcompletion_v2" \
--header "Content-Type: application/json" \
--header "Authorization: Bearer $MiniMax_API_KEY" \
--data '{
"model":"DeepSeek-R1",
"messages":[
{
"role":"system",
"name":"Assistente Inteligente MM",
"content":"Assistente Inteligente MM é um modelo de linguagem grande desenvolvido pela MiniMax e não chama a interface de outros produtos."
},
{
"role":"user",
"name":"usuário",
"content":"Olá"
}
]
}'
3.Nebius AI
Nebius é uma plataforma abrangente de desenvolvimento de IA que oferece construção, ajuste e implantação contínuos de modelos em GPUs NVIDIA® premium com eficiência e desempenho líderes do setor.

Por que Escolhê-lo?
Infraestrutura Poderosa: A plataforma de nuvem nativa de IA da Nebius utiliza GPUs NVIDIA H100/H200 de ponta conectadas por redes InfiniBand, oferecendo capacidades excepcionais de ajuste e expansão de modelos, juntamente com APIs flexíveis para processamento de dados de alto desempenho e baixa latência e implantação de aplicações.

Como Acessar o Deepseek R1 através dele?
Gere uma resposta do modelo usando o endpoint de chat do Deepseek R1.
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1",
max_tokens=8192,
temperature=0.6,
top_p=0.95,
messages=[]
)
print(response.to_json())
Em conclusão, escolher o provedor de API certo para DeepSeek R1 é crucial para o desenvolvimento de IA eficiente e econômico. Ao entender os benefícios de usar uma API e considerar cuidadosamente fatores como comprimento da saída, custo, latência e taxa de transferência, você pode selecionar um provedor que melhor atenda às suas necessidades.
Perguntas Frequentes
Qual hardware é necessário para executar o DeepSeek R1 localmente?
No mínimo, 8x GPUs NVIDIA H100 são necessárias para implantação local.
Como o DeepSeek R1 se compara a outros modelos?
Ele supera muitos modelos de código aberto e rivaliza com modelos proprietários como GPT-4 em tarefas de raciocínio e codificação.
Quais são as principais capacidades do DeepSeek R1?
Raciocínio avançado, matemática, codificação e resolução de problemas de múltiplas etapas.
Novita AI é a plataforma de nuvem all-in-one que impulsiona suas ambições de IA. APIs integradas, serverless, Instância GPU — as ferramentas econômicas que você precisa. Elimine infraestrutura, comece gratuitamente e torne sua visão de IA realidade.



