

النقاط الرئيسية
فوائد استخدام واجهة برمجة التطبيقات (API): تجنب أخطاء الشبكة: تخطي فترات التوقف الناتجة عن كثافة الحركة (كما ظهر في مشاكل تطبيق DeepSeek الأخيرة) بالاعتماد على بنية تحتية قابلة للتوسع لواجهات البرمجة. تجنب متاعب النشر المحلي: الاستغناء عن الحاجة لوحدات معالجة رسوميات عالية المستوى، وتركيبات معقدة، وقيود الذاكرة.
كيفية اختيار موفر واجهة برمجة التطبيقات: أقصى إخراج: إعطاء الأولوية للموفرين الذين يدعمون ≥8k توكن للمهام الطويلة. كفاءة التكلفة: مقارنة تكاليف الإدخال والإخراج. زمن الاستجابة: أمر حاسم للتطبيقات الفورية. الإنتاجية: ضمان التزامن العالي.
أفضل 3 موفري واجهة برمجة تطبيقات DeepSeek R1: Novita AI، Minimax، Nebius AI
Novita AI يطلق إصدار Turbo عالي الأداء لـ DeepSeek R1/V3! تحسين أداء الإنتاجية بمقدار 3 مرات، خصم 20% لفترة محدودة.
في مشهد الذكاء الاصطناعي المتطور اليوم، يعد اختيار موفر واجهة برمجة التطبيقات المناسب أمرًا ضروريًا للاستفادة الفعالة من نماذج اللغة المتقدمة. مع ظهور نماذج ضخمة مثل DeepSeek، أصبح النشر المحلي صعبًا ومكلفًا. الوصول إلى هذه النماذج عبر واجهات برمجة التطبيقات لا يتجنب فقط الاستثمار في الأجهزة والتكوين التقني، بل يضمن أيضًا خدمة مستقرة وموثوقة. تستكشف هذه المقالة الفوائد الرئيسية لاختيار واجهات البرمجة، وتحلل كيفية تقييم الموفرين المختلفين، وتقدم أبرز خدمات واجهة برمجة تطبيقات DeepSeek R1 المتاحة في السوق.
فوائد استخدام واجهة برمجة التطبيقات
تجنب أخطاء الشبكة بسبب الحركة الهائلة
مؤخرًا، شهد تطبيق DeepSeek انقطاعات كبيرة بسبب الطلب الهائل من المستخدمين، مما أدى إلى فترات توقف طويلة وأداء غير متناسق. يبرز هذا الموقف أهمية اختيار موفر واجهة برمجة تطبيقات قوي يمكنه ضمان وصول موثوق ومستمر لقدرات DeepSeek R1 القوية حتى خلال فترات الاستخدام القصوى.
من Reddit
تجنب متاعب الوصول المحلي
الحجم الهائل لـ DeepSeek R1 يخلق عقبات كبيرة للتطبيق المحلي. تشغيل هذا النموذج بفعالية يتطلب موارد حوسبة استثنائية—تحديدًا، تكوين أدنى من 8x من وحدات معالجة الرسوميات H100، مما يمثل استثمارًا كبيرًا في الأجهزة. باستخدام خدمات واجهة برمجة التطبيقات بدلاً من ذلك، يمكنك تسخير إمكانات النموذج الكاملة بسلاسة دون القلق بشأن مواصفات الأجهزة، أو إجراءات التثبيت المعقدة، أو التكوينات التقنية، أو قيود الذاكرة.
من Reddit
كيفية اختيار موفر واجهة برمجة التطبيقات (4 مقاييس)
| المقياس | التعريف | تأثير مرتفع/منخفض |
|---|---|---|
| أقصى إخراج | أقصى عدد من التوكنات يمكن للنموذج توليدها في استجابة واحدة. | أعلى = أفضل |
| تكلفة الإدخال | التكلفة لكل مليون توكن إدخال تمت معالجتها (مثل مطالبات المستخدم، السياق). | أقل = أفضل |
| تكلفة الإخراج | التكلفة لكل مليون توكن إخراج تم توليدها (مثل استجابات النموذج). | أقل = أفضل |
| زمن الاستجابة | التأخير الزمني بين إرسال الطلب واستلام أول بايت من الاستجابة. | أقل = أفضل |
| الإنتاجية | عدد الطلبات المعالجة في الثانية (سعة النظام). | أعلى = أفضل |
بالإضافة إلى ذلك، يمكنك التركيز على مقاييس مختلفة حسب حالات الاستخدام الخاصة بك.
| نوع التطبيق | أمثلة حالات الاستخدام | الأبعاد ذات الأولوية (مرتبة) |
|---|---|---|
| التطبيقات الفورية | دعم العملاء، روبوتات المحادثة، الترجمة الفورية | 1. زمن الاستجابة (<500ms) 2. الإنتاجية (100+ req/sec) 3. التكلفة (ثانوية إلا على نطاق واسع) |
| توليد المحتوى الطويل | التقارير، كتابة المقالات، توليد الأكواد | 1. أقصى إخراج (≥8k توكن) 2. تكلفة الإخراج ($1.10/مليون توكن) 3. زمن الاستجابة (2-3s مقبول) |
| المعالجة الدفعية الحساسة للتكلفة | تلخيص كميات كبيرة، تصنيف البيانات | 1. تكلفة الإدخال ($0.07/مليون توكن) 2. الإنتاجية (1k+ req/hour) 3. أقصى إخراج (أولوية أقل) |
| الاستدلال متعدد الوسائط/المعقد | التنبؤ المالي، التشخيص الطبي | 1. قدرة النموذج (الدقة) 2. أقصى إخراج (استدلال مفصل) 3. زمن الاستجابة (10s+ مقبول) |
| النشر على الحافة/الجهاز | أجهزة إنترنت الأشياء، تطبيقات الجوال | 1. زمن الاستجابة (<200ms) 2. الإنتاجية (نماذج خفيفة) 3. التكلفة (أقل أهمية) |
أفضل 3 موفري واجهة برمجة تطبيقات DeepSeek R1
| الموفر لـ DeepSeek R1 | السياق | أقصى إخراج | تكلفة الإدخال | تكلفة الإخراج | الإنتاجية |
|---|---|---|---|---|---|
| Minimax | 64K | 64K | $0.55 | $2.19 | 19.83 t/s |
| Novita AI Turbo | 64K | 16K | $0.7 | $2.5 | 30 tokens/s |
| Nebius AI Studio | 128K | 128K | $0.8 | $2.4 | 13.20 t/s |
1. Novita AI
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة تطبيقات بسيطة، مع توفير سحابة وحدات معالجة رسوميات ميسورة التكلفة وموثوقة للبناء والتوسع.

لماذا تختارها؟
- كفاءة التطوير: الوصول إلى مكتبة واسعة من النماذج متعددة الوسائط المدمجة مسبقًا، والتي تضم قادة الصناعة مثل DeepSeek V3 و DeepSeek R1 و Llama 3.3 70B و Qwen 2.5 و QWQ وعشرات الخيارات المتطورة الأخرى.
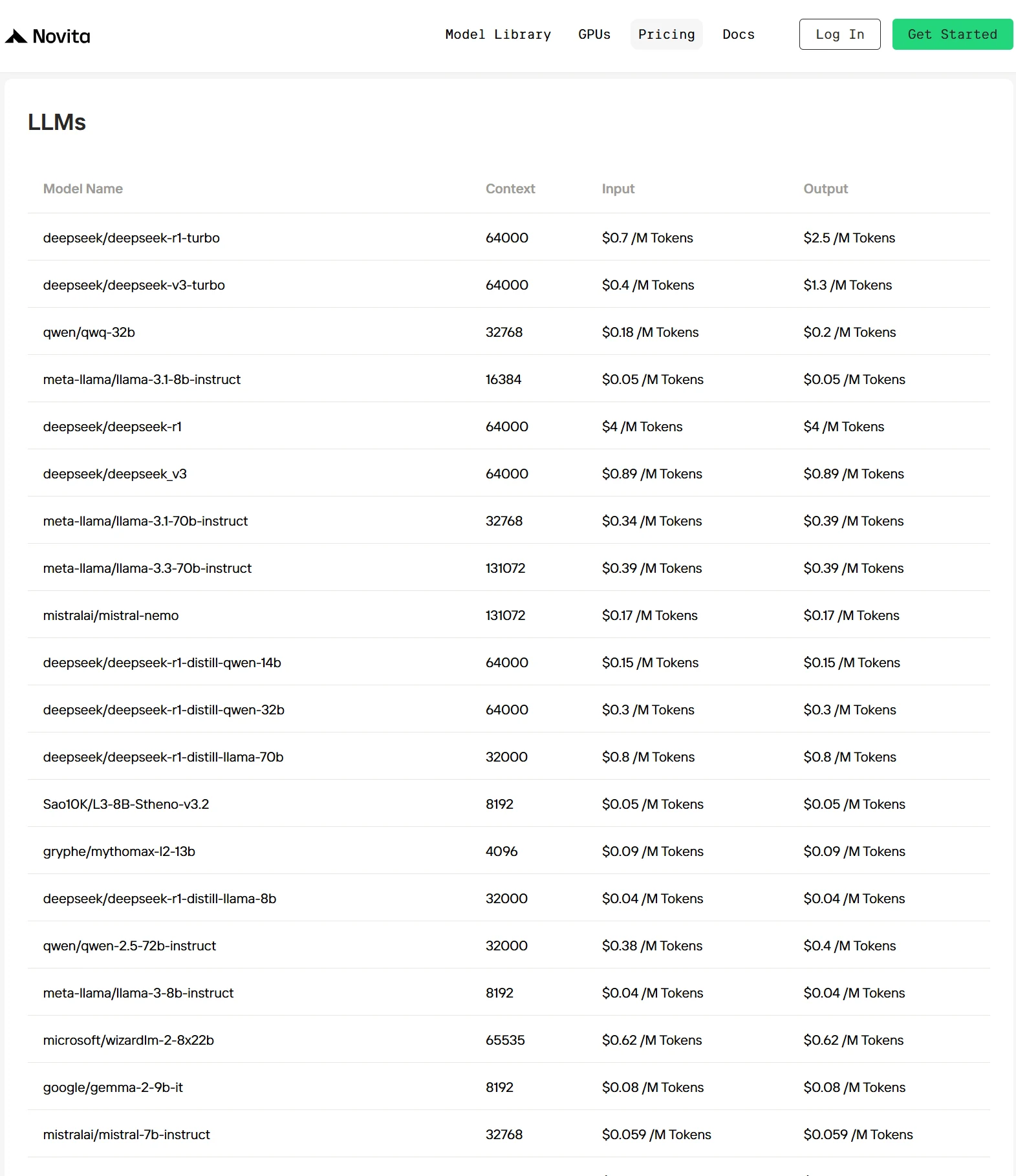
- ميزة التكلفة: اقتصاديات متفوقة دون المساس بالأداء
على غرار DeepSeek R1 و DeepSeek V3، تطلق Novita AI إصدار Turbo مع إنتاجية مضاعفة 3 مرات وخصم 20% لفترة محدودة!

كيفية الوصول إلى DeepSeek R1 من خلالها؟
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة وحدد النموذج الذي يناسب احتياجاتك.

جرب عرض DeepSeek R1 Turbo التجريبي الآن!
الخطوة 3: ابدأ الفترة التجريبية المجانية
ابدأ الفترة التجريبية المجانية لاستكشاف قدرات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع واجهة برمجة التطبيقات، سنقدم لك مفتاح API جديد. بالدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت واجهة برمجة التطبيقات
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة الخاصة بك.

بعد التثبيت، قم باستيراد المكتبات اللازمة في بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام API لإكمال المحادثة لمستخدمي بايثون.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-r1-turbo"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
عند التسجيل، توفر Novita AI رصيدًا بقيمة $0.5 لتبدأ!
إذا نفد الرصيد المجاني، يمكنك الدفع لمواصلة الاستخدام.
2. Minimax
MiniMax، شركة رائدة في مجال التكنولوجيا الآسيوية، تقدم قدرات استثنائية متعددة الوسائط للذكاء الاصطناعي من خلال نماذج مملوكة تغطي النصوص والكلام والموسيقى والصور والفيديو، مما يغذي التطبيقات العالمية لملايين المستخدمين وأكثر من 40,000 مؤسسة حول العالم.

لماذا تختارها؟
- تعدد الوسائط غير المسبوق: تقدم MiniMax قدرات استثنائية للذكاء الاصطناعي عبر النصوص والكلام والموسيقى والصور والفيديو من خلال نماذج مملوكة مثل Linear Attention LLMs ونظام Hailuo للفيديو المشهور.
- اقتصاديات معطلة للصناعة: تقدم MiniMax ذكاءً اصطناعيًا متميزًا بجزء بسيط من تكاليف المنافسين—تقدم أداءً بمستوى R1 (671B معلمة) بسعر $0.55/$2.19 لكل مليون توكن مع نوافذ سياق سخية بحجم 64K وإنتاجية عالية.
كيفية الوصول إلى DeepSeek R1 من خلالها؟
قم بتوليد استجابة نموذج باستخدام نقطة نهاية المحادثة الخاصة بـ DeepSeek-R1.
curl --location "https://api.minimaxi.chat/v1/text/chatcompletion_v2" \
--header "Content-Type: application/json" \
--header "Authorization: Bearer $MiniMax_API_KEY" \
--data '{
"model":"DeepSeek-R1",
"messages":[
{
"role":"system",
"name":"MM Intelligent Assistant",
"content":"MM Intelligent Assistant is a large language model that is self-developed by MiniMax and does not call the interface of other products. "
},
{
"role":"user",
"name":"user",
"content":"Hello"
}
]
}'
3. Nebius AI
Nebius هي منصة تطوير ذكاء اصطناعي شاملة تقدم بناء النماذج وضبطها ونشرها بسلاسة على وحدات معالجة رسوميات NVIDIA® الممتازة بكفاءة وأداء رائدين في الصناعة.

لماذا تختارها؟
بنية تحتية قوية: تستفيد منصة Nebius السحابية المخصصة للذكاء الاصطناعي من أحدث وحدات معالجة الرسوميات NVIDIA H100/H200 المتصلة عبر شبكات InfiniBand، مما يوفر قدرات استثنائية لضبط النماذج وتوسيعها إلى جانب واجهات برمجة تطبيقات مرنة لمعالجة البيانات عالية الأداء منخفضة زمن الاستجابة ونشر التطبيقات.

كيفية الوصول إلى DeepSeek R1 من خلالها؟
قم بتوليد استجابة نموذج باستخدام نقطة نهاية المحادثة الخاصة بـ DeepSeek R1.
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1",
max_tokens=8192,
temperature=0.6,
top_p=0.95,
messages=[]
)
print(response.to_json())
في الختام، يعد اختيار موفر واجهة برمجة التطبيقات المناسب لـ DeepSeek R1 أمرًا بالغ الأهمية لتطوير ذكاء اصطناعي فعال من حيث التكلفة والأداء. من خلال فهم فوائد استخدام واجهة برمجة التطبيقات والنظر بعناية في عوامل مثل طول الإخراج والتكلفة وزمن الاستجابة والإنتاجية، يمكنك اختيار موفر يناسب احتياجاتك بشكل أفضل.
الأسئلة المتكررة
ما هي الأجهزة المطلوبة لتشغيل DeepSeek R1 محليًا؟
كحد أدنى، يلزم وجود 8x من وحدات معالجة الرسوميات NVIDIA H100 للنشر المحلي.
كيف يقارن DeepSeek R1 بالنماذج الأخرى؟
يتفوق على العديد من النماذج مفتوحة المصدر وينافس النماذج المملوكة مثل GPT-4 في مهام الاستدلال والبرمجة.
ما هي القدرات الرئيسية لـ DeepSeek R1؟
الاستدلال المتقدم، الرياضيات، البرمجة، وحل المشكلات متعددة الخطوات.
Novita AI هي المنصة السحابية الشاملة التي تمكن طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، بدون خادم، مثيل GPU—الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجانًا، وحقق رؤيتك في الذكاء الاصطناعي.



