

Points clés
Les avantages de l’utilisation d’une API :
Évitez les erreurs réseau : Surmontez les interruptions dues à un trafic élevé (comme observé avec les récents problèmes de l’application DeepSeek) en vous appuyant sur une infrastructure API scalable.
Éliminez les tracas du déploiement local : Contournez le besoin de GPU haut de gamme, d’installations complexes et de contraintes mémoire.
Comment choisir un fournisseur d’API :
Sortie maximale : Privilégiez les fournisseurs supportant ≥8k tokens pour les tâches longues.
Rentabilité : Comparez les coûts d’entrée et de sortie.
Latence : Critique pour les applications en temps réel.
Débit : Assurez une haute concurrence.
Top 3 des fournisseurs d’API DeepSeek R1 :
Novita AI, Minimax, Nebius AI
Novita AI lance le Deepseek R1/V3 Turbo à hautes performances ! Débit 3x amélioré, réduction de 20 % pour une durée limitée.
Dans le paysage actuel de l’IA en pleine évolution, choisir le bon fournisseur d’API est essentiel pour utiliser efficacement les modèles de langage avancés. Avec l’émergence de modèles massifs comme DeepSeek, le déploiement local est devenu difficile et coûteux. Accéder à ces modèles via des API permet non seulement d’éviter les investissements matériels et les configurations techniques, mais aussi de garantir un service stable et fiable. Cet article explore les principaux avantages du choix d’API, analyse comment évaluer les différents fournisseurs et présente les principaux services API DeepSeek R1 disponibles sur le marché.
Les avantages de l’utilisation d’une API
Évitez les erreurs réseau dues à un trafic énorme
Récemment, l’application DeepSeek a connu des perturbations importantes en raison d’une demande utilisateur écrasante, entraînant des temps d’arrêt prolongés et des performances irrégulières. Cette situation souligne l’importance cruciale de sélectionner un fournisseur d’API robuste capable de garantir un accès fiable et ininterrompu aux puissantes capacités de DeepSeek R1, même pendant les périodes de pointe.
de Reddit
Évitez les tracas de l’accès local
La taille imposante de DeepSeek R1 crée des obstacles importants au déploiement local. Exécuter ce modèle efficacement nécessite des ressources de calcul exceptionnelles – spécifiquement, une configuration minimale de 8 GPU H100, représentant un investissement matériel conséquent. En utilisant plutôt des services API, vous pouvez exploiter pleinement le potentiel du modèle sans vous soucier des spécifications matérielles, des procédures d’installation complexes, des configurations techniques ou des contraintes mémoire.
de Reddit
Comment choisir un fournisseur d’API (4 indicateurs)
| Indicateur | Définition | Impact élevé/faible |
|---|---|---|
| Sortie max. | Nombre maximum de tokens que le modèle peut générer en une seule réponse. | Plus élevé = Mieux |
| Coût d’entrée | Coût par million de tokens d’entrée traités (ex. : invites utilisateur, contexte). | Plus faible = Mieux |
| Coût de sortie | Coût par million de tokens de sortie générés (ex. : réponses du modèle). | Plus faible = Mieux |
| Latence | Délai entre l’envoi d’une requête et la réception du premier octet de réponse. | Plus faible = Mieux |
| Débit | Nombre de requêtes traitées par seconde (capacité du système). | Plus élevé = Mieux |
De plus, vous pouvez vous concentrer sur différents indicateurs selon vos cas d’usage.
| Type d’application | Exemples de cas d’usage | Dimensions prioritaires (classées) |
|---|---|---|
| Applications en temps réel | Support client, chatbots, traduction en direct | 1. Latence (<500ms) 2. Débit (100+ req/s) 3. Coût (secondaire sauf à grande échelle) |
| Génération de contenu long | Rapports, rédaction d’articles, génération de code | 1. Sortie max. (≥8k tokens) 2. Coût de sortie (1,10 $/million de tokens) 3. Latence (2-3s acceptable) |
| Traitement par lots sensible aux coûts | Résumé en masse, étiquetage de données | 1. Coût d’entrée (0,07 $/million de tokens) 2. Débit (1k+ req/heure) 3. Sortie max. (priorité moindre) |
| Raisonnement multimodal/complexe | Prévisions financières, diagnostic médical | 1. Capacité du modèle (précision) 2. Sortie max. (raisonnement détaillé) 3. Latence (10s+ acceptable) |
| Déploiement en périphérie/sur appareil | Appareils IoT, applications mobiles | 1. Latence (<200ms) 2. Débit (modèles légers) 3. Coût (moins important) |
Top 3 des fournisseurs d’API DeepSeek R1
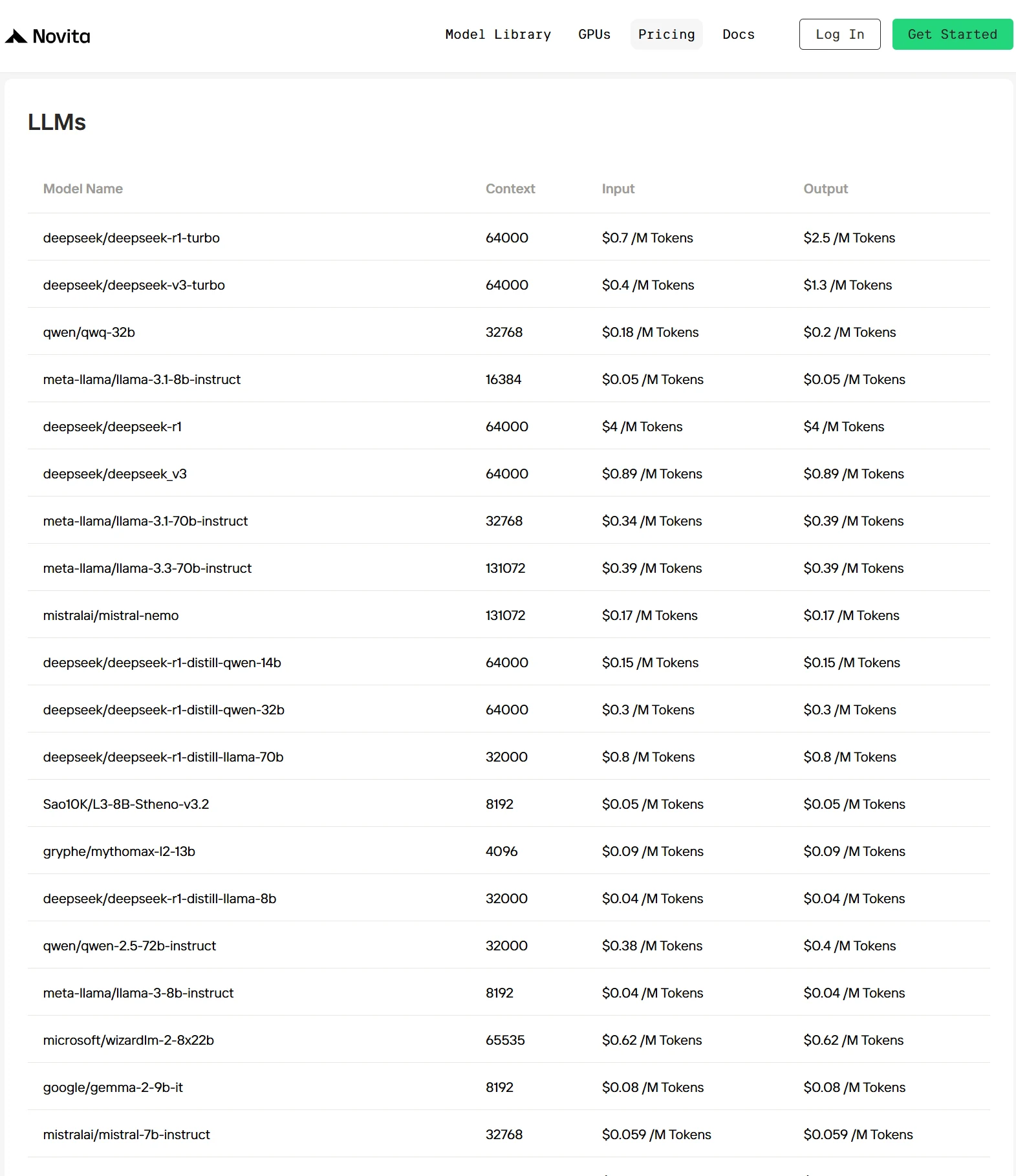
| Fournisseur pour DeepSeek R1 | Contexte | Sortie max. | Coût d’entrée | Coût de sortie | Débit |
|---|---|---|---|---|---|
| Minimax | 64K | 64K | 0,55 $ | 2,19 $ | 19,83 t/s |
| Novita AI Turbo | 64K | 16K | 0,7 $ | 2,5 $ | 30 tokens/s |
| Nebius AI Studio | 128K | 128K | 0,8 $ | 2,4 $ | 13,20 t/s |
1.Novita AI
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.

Pourquoi le choisir ?
- Efficacité de développement : Accédez à une vaste bibliothèque de modèles multimodaux pré-intégrés, avec des leaders de l’industrie comme DeepSeek V3, DeepSeek R1, Llama 3.3 70B, Qwen 2.5, QWQ, et des dizaines d’options de pointe supplémentaires.
- Avantage de coût : Une économie supérieure sans compromis sur les performances.
Similaire à Deepseek R1 et Deepseek V3, Novita AI lance une version Turbo avec un débit 3x supérieur et une réduction de 20 % pour une durée limitée !

Comment accéder à Deepseek R1 via Novita AI ?
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Essayez la démo DeepSeek R1 Turbo dès maintenant !
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Rendez-vous dans la page « Paramètres » et copiez la clé API comme indiqué dans l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-r1-turbo"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Lors de l’inscription, Novita AI offre un crédit de 0,50 $ pour vous lancer !
Si le crédit gratuit est épuisé, vous pouvez payer pour continuer à l’utiliser.
2.Minimax
MiniMax, un leader technologique asiatique pionnier, offre des capacités d’IA multimodales exceptionnelles via des modèles propriétaires couvrant le texte, la parole, la musique, l’image et la vidéo, alimentant des applications mondiales pour des millions d’utilisateurs et plus de 40 000 entreprises dans le monde.

Pourquoi le choisir ?
- Multimodalité inégalée : MiniMax offre une IA exceptionnelle dans les domaines du texte, de la parole, de la musique, de l’image et de la vidéo grâce à des modèles propriétaires comme les LLM à attention linéaire et le système vidéo Hailuo acclamé.
- Économie révolutionnaire : Proposant une IA premium à une fraction des coûts des concurrents – MiniMax offre des performances de calibre R1 (671B paramètres) à seulement 0,55 $ / 2,19 $ par million de tokens avec des fenêtres de contexte généreuses de 64K et un débit élevé.
Comment accéder à Deepseek R1 via Minimax ?
Générez une réponse du modèle en utilisant le point de terminaison chat de Deepseek-R1.
curl --location "https://api.minimaxi.chat/v1/text/chatcompletion_v2" \
--header "Content-Type: application/json" \
--header "Authorization: Bearer $MiniMax_API_KEY" \
--data '{
"model":"DeepSeek-R1",
"messages":[
{
"role":"system",
"name":"MM Intelligent Assistant",
"content":"MM Intelligent Assistant is a large language model that is self-developed by MiniMax and does not call the interface of other products. "
},
{
"role":"user",
"name":"user",
"content":"Hello"
}
]
}'
3.Nebius AI
Nebius est une plateforme complète de développement IA offrant la construction, le réglage fin et le déploiement de modèles sur des GPU NVIDIA® premium avec une efficacité et des performances de pointe.

Pourquoi le choisir ?
Infrastructure puissante : La plateforme cloud native IA de Nebius exploite les GPU NVIDIA H100/H200 de pointe connectés via des réseaux InfiniBand, offrant des capacités exceptionnelles de réglage fin et d’expansion de modèles, ainsi que des API flexibles pour le traitement de données haute performance et à faible latence et le déploiement d’applications.

Comment accéder à Deepseek R1 via Nebius AI ?
Générez une réponse du modèle en utilisant le point de terminaison chat de Deepseek R1.
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1",
max_tokens=8192,
temperature=0.6,
top_p=0.95,
messages=[]
)
print(response.to_json())
En conclusion, choisir le bon fournisseur d’API pour DeepSeek R1 est crucial pour un développement IA efficace et rentable. En comprenant les avantages de l’utilisation d’une API et en considérant attentivement des facteurs tels que la longueur de sortie, le coût, la latence et le débit, vous pouvez sélectionner le fournisseur qui répond le mieux à vos besoins.
Questions fréquentes
Quel matériel est nécessaire pour exécuter DeepSeek R1 localement ?
Au minimum, 8 GPU NVIDIA H100 sont nécessaires pour le déploiement local.
Comment DeepSeek R1 se compare-t-il aux autres modèles ?
Il surpasse de nombreux modèles open-source et rivalise avec des modèles propriétaires comme GPT-4 dans les tâches de raisonnement et de codage.
Quelles sont les principales capacités de DeepSeek R1 ?
Raisonnement avancé, mathématiques, codage et résolution de problèmes multi-étapes.
Novita AI est la plateforme cloud tout-en-un qui dynamise vos ambitions en IA. API intégrées, serverless, instance GPU — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et concrétisez votre vision de l’IA.



