

Puntos clave
Ventajas de usar una API:
Evitar errores de red: Supera las interrupciones causadas por el alto tráfico (como se ha visto en los recientes problemas de la app de DeepSeek) confiando en una infraestructura de API escalable.
Eliminar las molestias del despliegue local: Olvídate de la necesidad de GPUs de alta gama, instalaciones complejas y limitaciones de memoria.
Cómo elegir un proveedor de API:
Salida máxima: Prioriza proveedores que soporten ≥8k tokens para tareas de texto largo.
Eficiencia de costes: Compara costes de entrada y salida.
Latencia: Crítica para aplicaciones en tiempo real.
Rendimiento: Asegura una alta concurrencia.
Los 3 mejores proveedores de API de DeepSeek R1:
Novita AI, Minimax, Nebius AI
Novita AI lanza el potente Deepseek R1/V3 Turbo. ¡Rendimiento de rendimiento 3 veces mejor, descuento del 20% por tiempo limitado!
En el panorama actual de la IA en rápida evolución, elegir el proveedor de API adecuado es esencial para utilizar eficazmente modelos de lenguaje avanzados. Con la aparición de modelos masivos como DeepSeek, el despliegue local se ha vuelto difícil y costoso. Acceder a estos modelos a través de APIs no solo evita la inversión en hardware y los problemas de configuración técnica, sino que también garantiza un servicio estable y fiable. Este artículo explora las principales ventajas de elegir APIs, analiza cómo evaluar diferentes proveedores y presenta los principales servicios de API de DeepSeek R1 disponibles en el mercado.
Ventajas de usar una API
Evitar errores de red debido al enorme tráfico
Recientemente, la app de DeepSeek ha sufrido interrupciones importantes debido a la abrumadora demanda de los usuarios, lo que ha provocado tiempos de inactividad prolongados y un rendimiento inconsistente. Esta situación subraya la importancia crítica de seleccionar un proveedor de API robusto que pueda garantizar un acceso fiable e ininterrumpido a las potentes capacidades de DeepSeek R1, incluso durante los períodos de uso máximo.
de Reddit
Evitar problemas de acceso local
El imponente tamaño de DeepSeek R1 crea barreras sustanciales para la implementación local. Ejecutar este modelo de forma efectiva requiere recursos informáticos excepcionales: específicamente, una configuración mínima de 8 GPUs H100, lo que supone una inversión de hardware significativa. Al utilizar servicios de API, puedes aprovechar sin problemas todo el potencial del modelo sin preocuparte por las especificaciones de hardware, los procedimientos de instalación complejos, las configuraciones técnicas o las limitaciones de memoria.
de Reddit
Cómo elegir un proveedor de API (4 métricas)
| Métrica | Definición | Impacto alto/bajo |
|---|---|---|
| Salida máxima | Máximo de tokens que el modelo puede generar en una sola respuesta. | Más alto = Mejor |
| Costo de entrada | Costo por millón de tokens de entrada procesados (ej. mensajes de usuario, contexto). | Más bajo = Mejor |
| Costo de salida | Costo por millón de tokens de salida generados (ej. respuestas del modelo). | Más bajo = Mejor |
| Latencia | Retraso entre el envío de una solicitud y la recepción del primer byte de respuesta. | Más bajo = Mejor |
| Rendimiento | Número de solicitudes procesadas por segundo (capacidad del sistema). | Más alto = Mejor |
Además, puedes centrarte en diferentes métricas según tu caso de uso.
| Tipo de aplicación | Ejemplos de uso | Dimensiones prioritarias (ordenadas) |
|---|---|---|
| Aplicaciones en tiempo real | Atención al cliente, chatbots, traducción en vivo | 1. Latencia (<500ms) 2. Rendimiento (100+ req/s) 3. Costo (secundario excepto a gran escala) |
| Generación de contenido extenso | Informes, redacción de artículos, generación de código | 1. Salida máxima (≥8k tokens) 2. Costo de salida ($1.10/millón de tokens) 3. Latencia (2-3s aceptable) |
| Procesamiento por lotes sensible al costo | Resúmenes masivos, etiquetado de datos | 1. Costo de entrada ($0.07/millón de tokens) 2. Rendimiento (1k+ req/hora) 3. Salida máxima (menor prioridad) |
| Razonamiento multimodal/complejo | Pronósticos financieros, diagnóstico médico | 1. Capacidad del modelo (precisión) 2. Salida máxima (razonamiento detallado) 3. Latencia (10s+ aceptable) |
| Implementación en el borde/dispositivo | Dispositivos IoT, apps móviles | 1. Latencia (<200ms) 2. Rendimiento (modelos ligeros) 3. Costo (menos importante) |
Los 3 mejores proveedores de API de DeepSeek R1
| Proveedor de DeepSeek R1 | Contexto | Salida máxima | Costo de entrada | Costo de salida | Rendimiento |
|---|---|---|---|---|---|
| Minimax | 64K | 64K | $0.55 | $2.19 | 19.83 t/s |
| Novita AI Turbo | 64K | 16K | $0.7 | $2.5 | 30 tokens/s |
| Nebius AI Studio | 128K | 128K | $0.8 | $2.4 | 13.20 t/s |
1. Novita AI
Novita AI es una plataforma cloud de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, al tiempo que proporciona una GPU cloud asequible y fiable para construir y escalar.

¿Por qué elegirlo?
- Eficiencia de desarrollo: Accede a una amplia biblioteca de modelos multimodales preintegrados, con líderes de la industria como DeepSeek V3, DeepSeek R1, Llama 3.3 70B, Qwen 2.5, QWQ y decenas de opciones más de vanguardia.
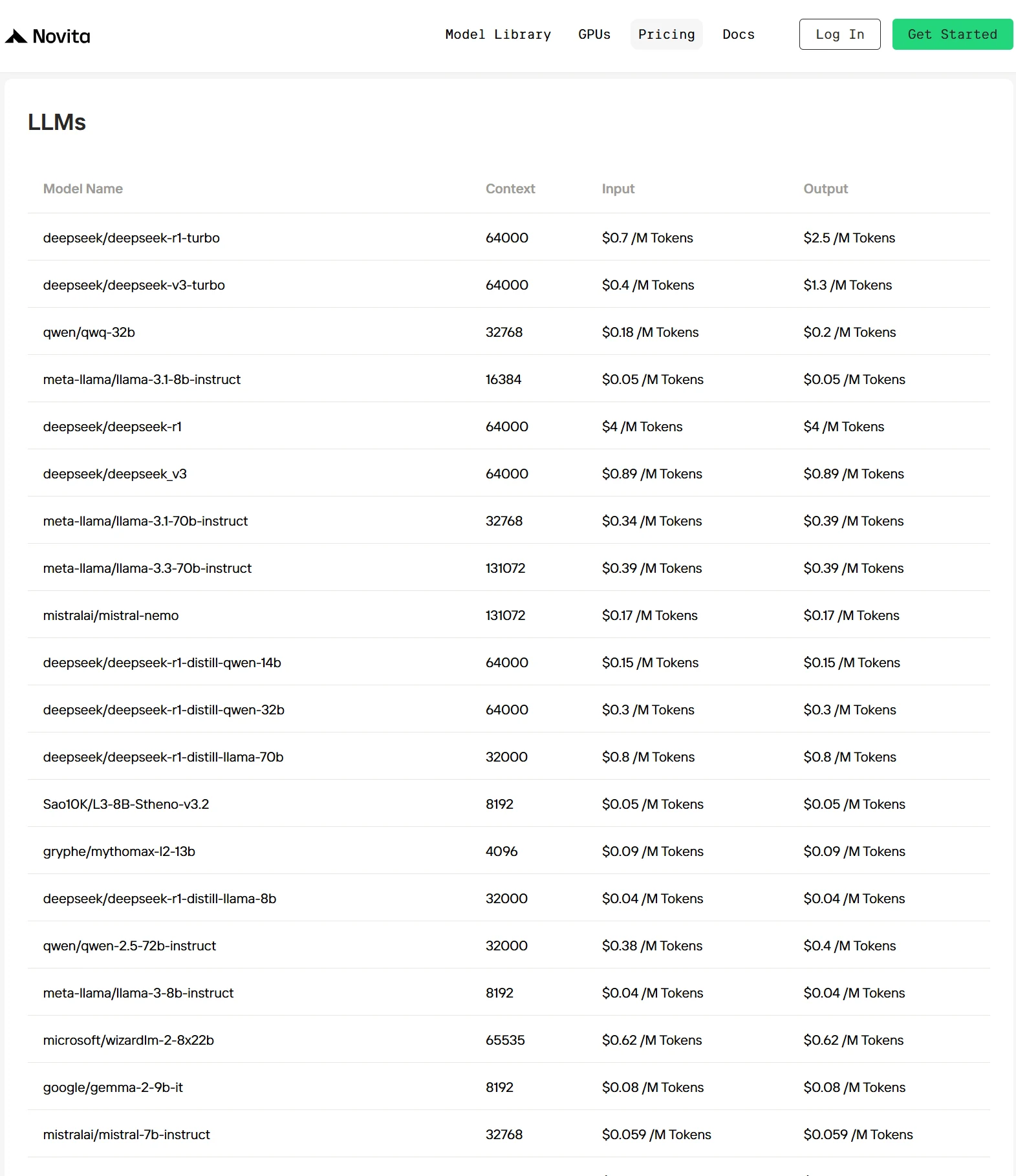
- Ventaja de costo: Economía superior sin compromiso de rendimiento
Similar a Deepseek R1 y Deepseek V3, Novita AI lanza una versión Turbo con 3x de rendimiento y un descuento del 20% por tiempo limitado.

¿Cómo acceder a Deepseek R1 a través de Novita AI?
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

¡Prueba la demo de DeepSeek R1 Turbo ahora!
Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
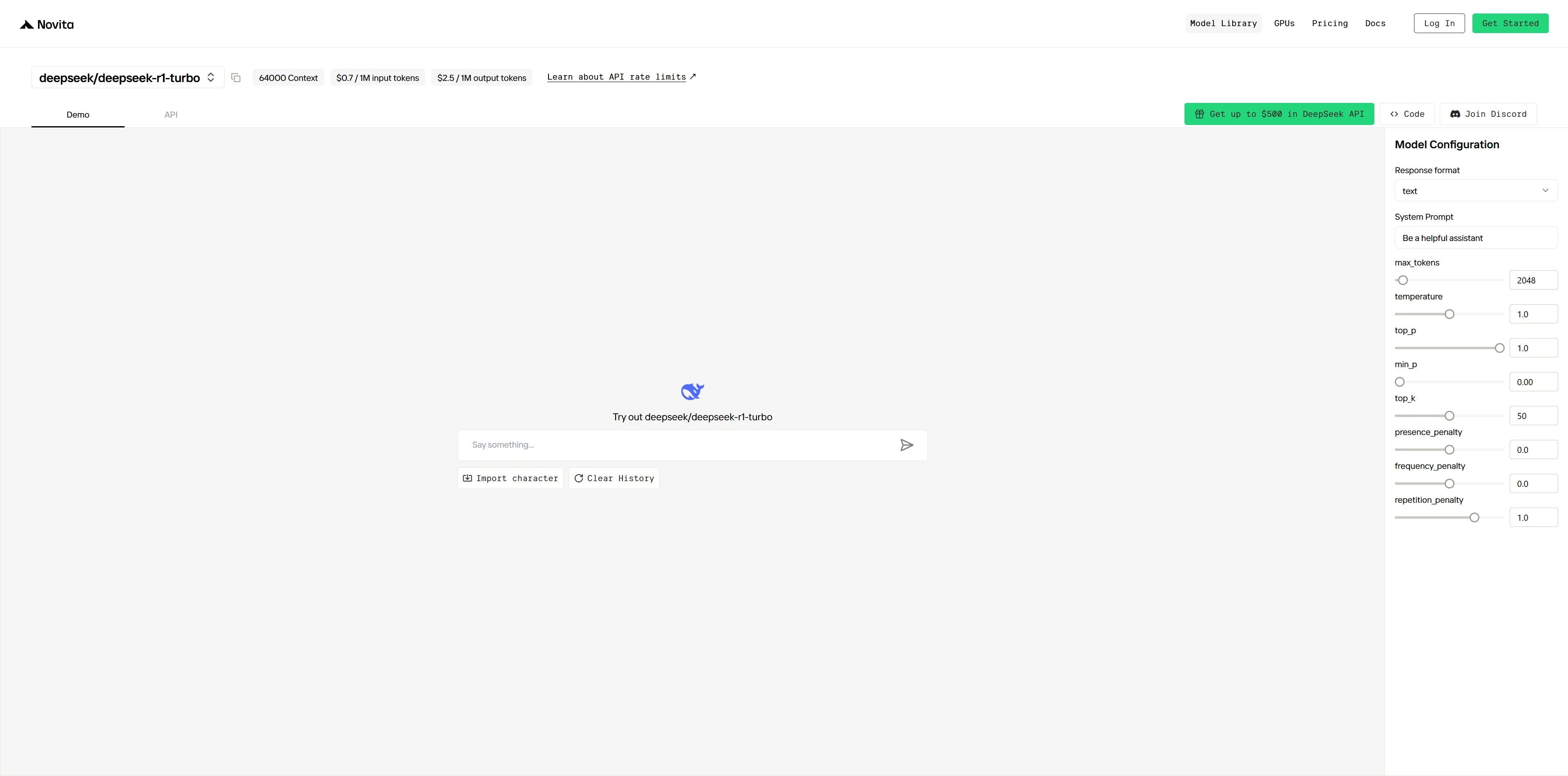
Paso 4: Obtén tu clave de API
Para autenticarte en la API, te proporcionaremos una nueva clave de API. Entra en la página de “Settings” y copia la clave de API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.

Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-r1-turbo"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Al registrarte, Novita AI proporciona un crédito de $0.5 para que puedas empezar.
Si los créditos gratuitos se agotan, puedes pagar para seguir usándolo.
2. Minimax
MiniMax, un líder tecnológico pionero asiático, ofrece capacidades multimodales de IA excepcionales a través de modelos propietarios que abarcan texto, voz, música, imagen y vídeo, impulsando aplicaciones globales para millones de usuarios y más de 40.000 empresas en todo el mundo.

¿Por qué elegirlo?
- Multimodalidad inigualable: MiniMax ofrece una IA excepcional en texto, voz, música, imagen y vídeo mediante modelos propietarios como Linear Attention LLMs y el aclamado sistema Hailuo de vídeo.
- Economía disruptiva: Ofrece IA premium a una fracción del coste de la competencia: MiniMax ofrece rendimiento de nivel R1 (671B parámetros) a solo $0.55/$2.19 por millón de tokens, con generosas ventanas de contexto de 64K y alto rendimiento.
¿Cómo acceder a Deepseek R1 a través de Minimax?
Genera una respuesta del modelo utilizando el endpoint de chat de Deepseek-R1.
curl --location "https://api.minimaxi.chat/v1/text/chatcompletion_v2" \
--header "Content-Type: application/json" \
--header "Authorization: Bearer $MiniMax_API_KEY" \
--data '{
"model":"DeepSeek-R1",
"messages":[
{
"role":"system",
"name":"MM Intelligent Assistant",
"content":"MM Intelligent Assistant is a large language model that is self-developed by MiniMax and does not call the interface of other products. "
},
{
"role":"user",
"name":"user",
"content":"Hello"
}
]
}'
3. Nebius AI
Nebius es una plataforma integral de desarrollo de IA que ofrece construcción, ajuste fino y despliegue de modelos sin interrupciones en GPUs NVIDIA® premium, con una eficiencia y rendimiento líderes en la industria.

¿Por qué elegirlo?
Infraestructura potente: La plataforma cloud nativa de IA de Nebius aprovecha las GPUs NVIDIA H100/H200 de última generación conectadas mediante redes InfiniBand, ofreciendo capacidades excepcionales de ajuste fino y expansión de modelos, junto con APIs flexibles para el procesamiento de datos y el despliegue de aplicaciones de alto rendimiento y baja latencia.

¿Cómo acceder a Deepseek R1 a través de Nebius?
Genera una respuesta del modelo utilizando el endpoint de chat de Deepseek R1.
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1",
max_tokens=8192,
temperature=0.6,
top_p=0.95,
messages=[]
)
print(response.to_json())
En conclusión, elegir el proveedor de API adecuado para DeepSeek R1 es crucial para un desarrollo de IA eficiente y rentable. Al comprender las ventajas de usar una API y considerar cuidadosamente factores como la longitud de salida, el costo, la latencia y el rendimiento, puedes seleccionar un proveedor que mejor se adapte a tus necesidades.
Preguntas frecuentes
¿Qué hardware se requiere para ejecutar DeepSeek R1 localmente?
Como mínimo, se requieren 8 GPUs NVIDIA H100 para el despliegue local.
¿Cómo se compara DeepSeek R1 con otros modelos?
Supera a muchos modelos de código abierto y rivaliza con modelos propietarios como GPT-4 en tareas de razonamiento y codificación.
¿Cuáles son las principales capacidades de DeepSeek R1?
Razonamiento avanzado, matemáticas, codificación y resolución de problemas de múltiples pasos.
Novita AI es la plataforma integral en la nube que impulsa tus ambiciones de IA. APIs integradas, sin servidor, instancias de GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



