

Wichtige Erkenntnisse
Die Vorteile der Nutzung einer API:
Netzwerkfehler vermeiden: Überwinden Sie Ausfallzeiten, die durch hohen Datenverkehr verursacht werden (wie bei DeepSeeks aktuellen App-Problemen), indem Sie auf eine skalierbare API-Infrastruktur setzen.
Lästige lokale Bereitstellung umgehen: Verzichten Sie auf High-End-GPUs, komplexe Installationen und Speicherbeschränkungen.
So wählen Sie einen API-Anbieter aus:
Max Output: Bevorzugen Sie Anbieter, die ≥8k Tokens für langformatige Aufgaben unterstützen.
Kosteneffizienz: Vergleichen Sie die Kosten für Input und Output.
Latenz: Entscheidend für Echtzeitanwendungen.
Durchsatz: Stellen Sie eine hohe Parallelverarbeitung sicher.
Top 3 API-Anbieter von DeepSeek R1:
Novita AI, Minimax, Nebius AI
Novita AI bringt leistungsstarke Deepseek R1/V3 Turbo auf den Markt! 3-fach verbesserte Durchsatzleistung, zeitlich begrenzter Rabatt von 20%.
In der heutigen, sich schnell entwickelnden KI-Landschaft ist die Wahl des richtigen API-Anbieters entscheidend, um fortschrittliche Sprachmodelle effektiv zu nutzen. Mit dem Aufkommen massiver Modelle wie DeepSeek wird die lokale Bereitstellung schwierig und kostspielig. Der Zugriff auf diese Modelle über APIs vermeidet nicht nur Hardwareinvestitionen und technische Konfigurationsprobleme, sondern gewährleistet auch einen stabilen und zuverlässigen Service. Dieser Artikel untersucht die Hauptvorteile der API-Nutzung, analysiert, wie man verschiedene Anbieter bewertet, und stellt die führenden DeepSeek R1 API-Dienste auf dem Markt vor.
Die Vorteile der Nutzung einer API
Netzwerkfehler aufgrund enormen Datenverkehrs vermeiden
In letzter Zeit kam es bei der DeepSeek-App aufgrund der überwältigenden Benutzernachfrage zu erheblichen Störungen, die zu längeren Ausfallzeiten und inkonsistenter Leistung führten. Diese Situation unterstreicht die entscheidende Bedeutung der Wahl eines robusten API-Anbieters, der auch in Spitzenlastzeiten einen zuverlässigen, unterbrechungsfreien Zugriff auf die leistungsstarken Fähigkeiten von DeepSeek R1 garantieren kann.
von Reddit
Probleme des lokalen Zugriffs vermeiden
Die gewaltige Größe von DeepSeek R1 stellt erhebliche Hürden für die lokale Implementierung dar. Der effektive Betrieb dieses Modells erfordert außergewöhnliche Rechenressourcen – konkret eine Mindestkonfiguration von 8x H100 GPUs, was eine erhebliche Hardwareinvestition darstellt. Durch die Nutzung von API-Diensten können Sie das volle Potenzial des Modells nutzen, ohne sich Gedanken über Hardwarespezifikationen, komplexe Installationsverfahren, technische Konfigurationen oder Speicherbeschränkungen machen zu müssen.
von Reddit
So wählen Sie einen API-Anbieter aus (4 Metriken)
| Metrik | Definition | Auswirkung (Hoch/Niedrig) |
|---|---|---|
| Max Output | Maximale Anzahl von Tokens, die das Modell in einer einzigen Antwort generieren kann. | Höher = Besser |
| Input Cost | Kosten pro Million verarbeiteter Input-Tokens (z. B. Benutzer-Prompts, Kontext). | Niedriger = Besser |
| Output Cost | Kosten pro Million generierter Output-Tokens (z. B. Modellantworten). | Niedriger = Besser |
| Latenz | Zeitverzögerung zwischen dem Senden einer Anfrage und dem Erhalt des ersten Antwortbytes. | Niedriger = Besser |
| Durchsatz | Anzahl der Anfragen, die pro Sekunde verarbeitet werden (Systemkapazität). | Höher = Besser |
Außerdem können Sie je nach Anwendungsfall unterschiedliche Metriken priorisieren.
| Anwendungstyp | Beispielanwendungsfälle | Prioritätsdimensionen (Rangfolge) |
|---|---|---|
| Echtzeitanwendungen | Kundensupport, Chatbots, Live-Übersetzung | 1. Latenz (<500ms) 2. Durchsatz (100+ req/sec) 3. Kosten (sekundär, außer im großen Maßstab) |
| Langformatige Inhaltserstellung | Berichte, Artikelverfassung, Codegenerierung | 1. Max Output (≥8k Tokens) 2. Output Cost ($1,10/Millionen Tokens) 3. Latenz (2-3s akzeptabel) |
| Kostensensitive Stapelverarbeitung | Massen-Zusammenfassung, Datenkennzeichnung | 1. Input Cost ($0,07/Millionen Tokens) 2. Durchsatz (1k+ req/hour) 3. Max Output (niedrigere Priorität) |
| Multimodales/komplexes Denken | Finanzprognosen, medizinische Diagnosen | 1. Modellfähigkeit (Genauigkeit) 2. Max Output (detaillierte Begründung) 3. Latenz (10s+ akzeptabel) |
| Edge/On-Device-Bereitstellung | IoT-Geräte, mobile Apps | 1. Latenz (<200ms) 2. Durchsatz (leichte Modelle) 3. Kosten (weniger wichtig) |
Top 3 API-Anbieter von DeepSeek R1
| Anbieter für DeepSeek R1 | Kontext | Max Output | Input Cost | Output Cost | Durchsatz |
|---|---|---|---|---|---|
| Minimax | 64K | 64K | $0,55 | $2,19 | 19,83 t/s |
| Novita AI Turbo | 64K | 16K | $0,7 | $2,5 | 30 tokens/s |
| Nebius AI Studio | 128K | 128K | $0,8 | $2,4 | 13,20 t/s |
1.Novita AI
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig die erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.

Warum sollte man sich dafür entscheiden?
- Entwicklungseffizienz: Greifen Sie auf eine umfangreiche Bibliothek vorintegrierter multimodaler Modelle zu, darunter Branchenführer wie DeepSeek V3, DeepSeek R1, Llama 3.3 70B, Qwen 2.5, QWQ und Dutzende weitere hochmoderne Optionen.
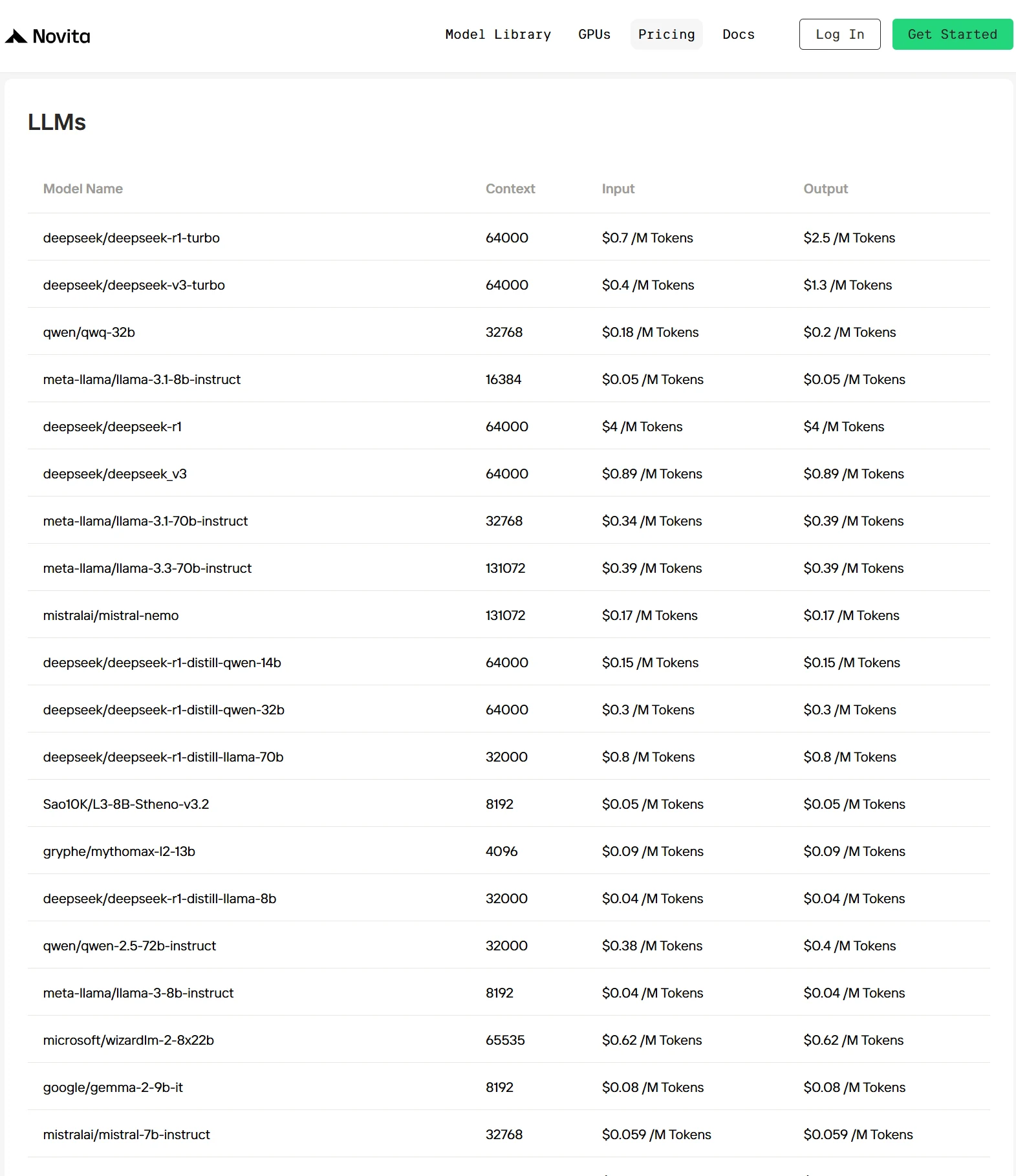
- Kostenvorteil: Überlegene Wirtschaftlichkeit ohne Leistungseinbußen
Ähnlich wie Deepseek R1 und Deepseek V3 bringt Novita AI eine Turbo-Version mit 3-fachem Durchsatz und einem zeitlich begrenzten Rabatt von 20% auf den Markt!

Wie greife ich darüber auf Deepseek R1 zu?
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Loggen Sie sich in Ihr Konto ein und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.

DeepSeek R1 Turbo Demo jetzt ausprobieren!
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
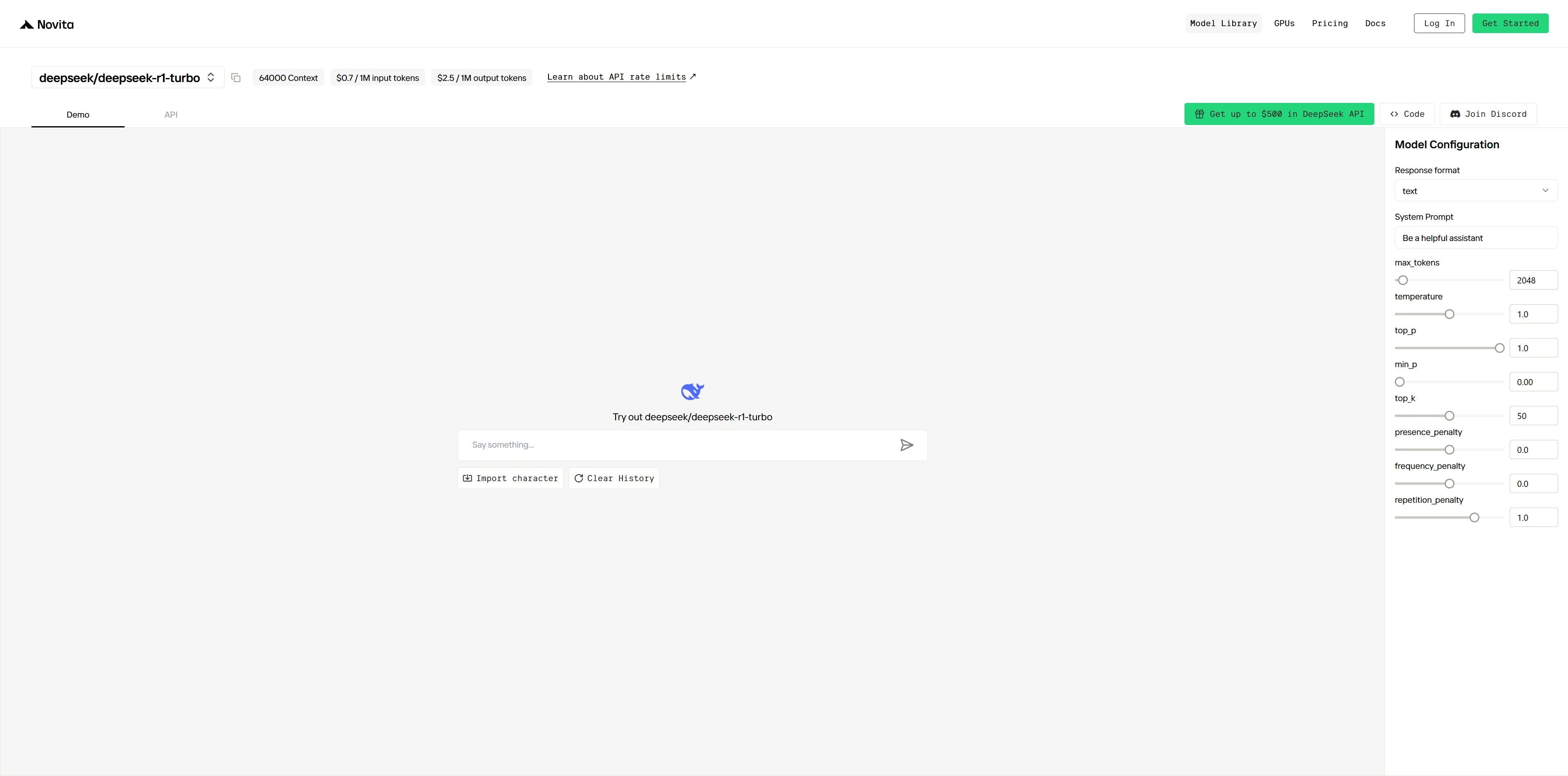
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API erhalten Sie einen neuen API-Schlüssel. Rufen Sie die Seite „Einstellungen“ auf und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-r1-turbo"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Bei der Registrierung gewährt Novita AI ein Guthaben von 0,50 $ für den Start!
Wenn das kostenlose Guthaben aufgebraucht ist, können Sie bezahlen, um es weiter zu nutzen.
2.Minimax
MiniMax, ein wegweisender asiatischer Technologieführer, liefert außergewöhnliche multimodale KI-Fähigkeiten durch proprietäre Modelle, die Text, Sprache, Musik, Bilder und Videos abdecken, und betreibt globale Anwendungen für Millionen von Benutzern und über 40.000 Unternehmen weltweit.

Warum sollte man sich dafür entscheiden?
- Unübertroffene Multimodalität: MiniMax liefert außergewöhnliche KI in den Bereichen Text, Sprache, Musik, Bild und Video durch proprietäre Modelle wie Linear Attention LLMs und das gefeierte Hailuo-Videosystem.
- Branchenrevolutionierende Wirtschaftlichkeit: Bietet erstklassige KI zu einem Bruchteil der Kosten der Konkurrenz – MiniMax liefert R1-Leistung (671B Parameter) für nur 0,55 $/2,19 $ pro Million Tokens mit großzügigen 64K-Kontextfenstern und hohem Durchsatz.
Wie greife ich darüber auf Deepseek R1 zu?
Generieren Sie eine Modellantwort mit dem Chat-Endpunkt von Deepseek-R1.
curl --location "https://api.minimaxi.chat/v1/text/chatcompletion_v2" \
--header "Content-Type: application/json" \
--header "Authorization: Bearer $MiniMax_API_KEY" \
--data '{
"model":"DeepSeek-R1",
"messages":[
{
"role":"system",
"name":"MM Intelligent Assistant",
"content":"MM Intelligent Assistant is a large language model that is self-developed by MiniMax and does not call the interface of other products. "
},
{
"role":"user",
"name":"user",
"content":"Hello"
}
]
}'
3.Nebius AI
Nebius ist eine umfassende KI-Entwicklungsplattform, die nahtloses Modell-Building, Fine-Tuning und Deployment auf erstklassigen NVIDIA® GPUs mit branchenführender Effizienz und Leistung bietet.

Warum sollte man sich dafür entscheiden?
Leistungsstarke Infrastruktur: Die KI-native Cloud-Plattform von Nebius nutzt hochmoderne NVIDIA H100/H200 GPUs, die über InfiniBand-Netzwerke verbunden sind, und bietet außergewöhnliche Möglichkeiten zum Fine-Tuning und zur Erweiterung von Modellen sowie flexible APIs für Hochleistungs-Datenverarbeitung und Anwendungsbereitstellung mit geringer Latenz.

Wie greife ich darüber auf Deepseek R1 zu?
Generieren Sie eine Modellantwort mit dem Chat-Endpunkt von Deepseek R1.
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1",
max_tokens=8192,
temperature=0.6,
top_p=0.95,
messages=[]
)
print(response.to_json())
Zusammenfassend lässt sich sagen, dass die Wahl des richtigen API-Anbieters für DeepSeek R1 entscheidend für eine effiziente und kostengünstige KI-Entwicklung ist. Indem Sie die Vorteile der Nutzung einer API verstehen und Faktoren wie Ausgabelänge, Kosten, Latenz und Durchsatz sorgfältig abwägen, können Sie einen Anbieter auswählen, der Ihren Anforderungen am besten entspricht.
Häufig gestellte Fragen
Welche Hardware ist erforderlich, um DeepSeek R1 lokal auszuführen?
Mindestens 8x NVIDIA H100 GPUs sind für die lokale Bereitstellung erforderlich.
Wie schneidet DeepSeek R1 im Vergleich zu anderen Modellen ab?
Es übertrifft viele Open-Source-Modelle und kann mit proprietären Modellen wie GPT-4 bei Reasoning- und Codierungsaufgaben mithalten.
Was sind die Hauptfähigkeiten von DeepSeek R1?
Fortschrittliches Reasoning, Mathematik, Codierung und mehrstufige Problemlösung.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen unterstützt. Integrierte APIs, Serverless, GPU-Instanz – die kostengünstigen Tools, die Sie benötigen. Infrastruktur überflüssig machen, kostenlos starten und Ihre KI-Vision verwirklichen.



