

OCR is no longer just “text extraction.” Modern teams need document intelligence: reading order, layout, tables, and structured outputs at scale—without enterprise OCR price tags. DeepSeek OCR2 pushes this trend further with a new visual encoding paradigm, and Novita AI makes it practical to ship into production with API and transparent token pricing.
What is DeepSeek OCR2
Basic Introduction
DeepSeek-OCR 2 is a multimodal document recognition model from DeepSeek AI, positioned as an upgrade to DeepSeek-OCR (Gen 1). Its key change is DeepEncoder V2, which moves visual processing from a rigid “raster scan” (top-left → bottom-right) toward semantic, causally-informed reading—closer to how humans follow logical structures in complex documents.
Traditional OCR pipelines often break on multi-column PDFs, dense financial statements, mixed tables + footnotes, and forms with tricky reading order. OCR2 is designed to understand the page, not only “recognize characters.”
| Feature | DeepSeek OCR2 |
| Organization | DeepSeek AI |
| Model Type | Multimodal document recognition (OCR + layout-aware understanding) |
| Key Innovation | DeepEncoder V2 reorders visual tokens based on image semantics (“fixed scanning” → “semantic reasoning”) |
| Context Window / Max Output | 8,192 / 8,192 |
| Input / Output | Input: text, image / Output: text |
| Quantization | bf16 |
| License | Apache-2.0 |
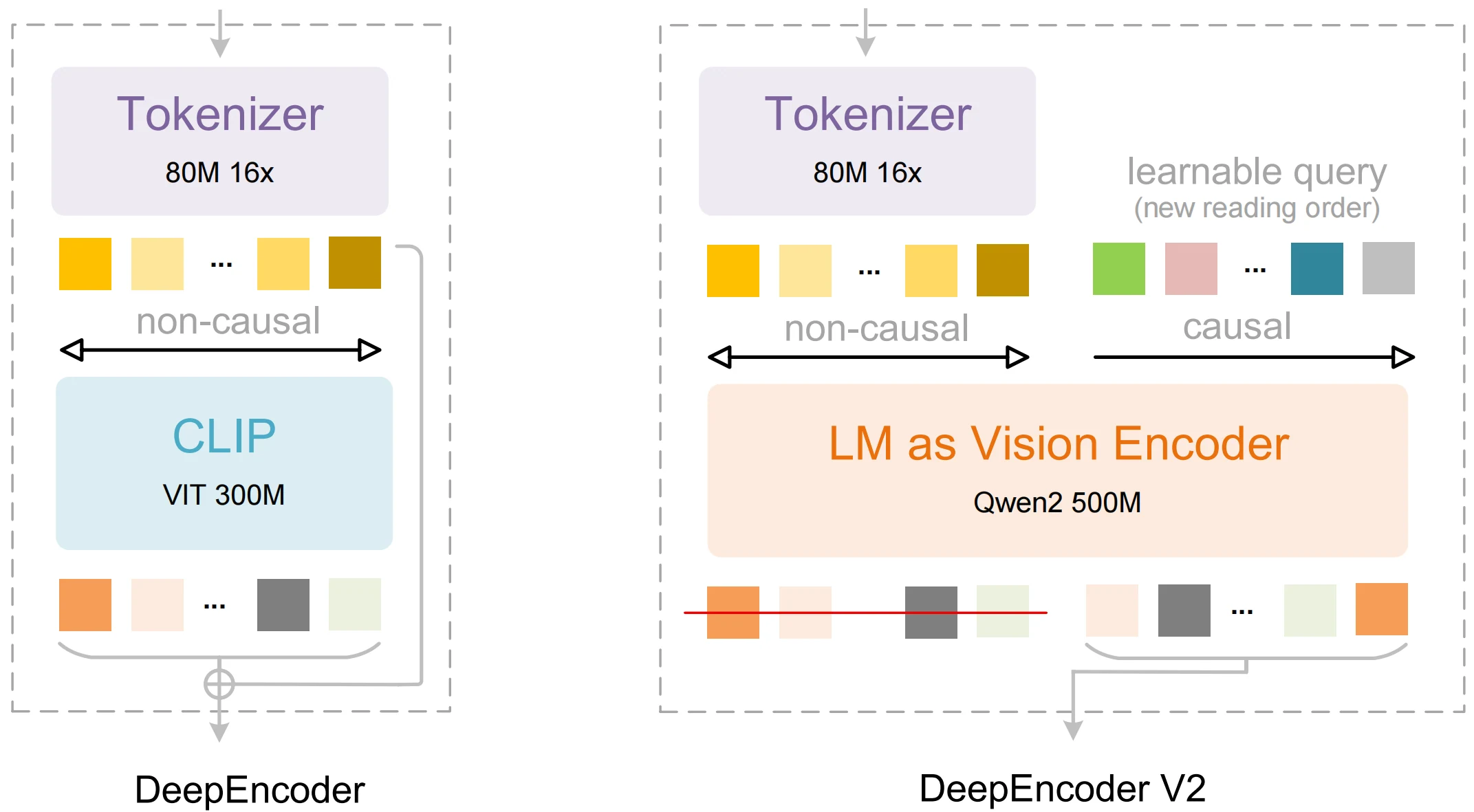
DeepSeek-OCR 2: Visual Causal Flow
🔍At a high level:
- Encoder side: DeepEncoder V2 can reorder visual tokens based on image semantics before the LLM-style decoding step.
- System design: OCR2 is described as retaining the DeepSeek-3B-MoE decoder, while replacing the original CLIP-based encoder with a lightweight LLM component (Qwen2-0.5B).
- Token efficiency: OCR2 targets document coverage using a constrained visual-token budget (reported in the 256–1120 range depending on complexity).
Benchmark Performance
OCR2’s improvements are most visible on document-centric benchmarks:
- On OmniDocBench v1.5, DeepSeek-OCR 2 achieves 91.09% overall, a +3.73% gain over its predecessor, and reduces reading-order edit distance from 0.085 → 0.057.
- OmniDocBench is designed to evaluate real-world PDF parsing across diverse document types, layouts, and languages.
If you’re building document workflows (invoice ingestion, claims processing, compliance PDFs, RAG over manuals), these metrics matter more than generic “OCR accuracy,” because they measure structure + layout understanding, not just character-level recognition.
How to Evaluate AI API Providers: The 5 Key Metrics
Choosing a model is only half the decision—the provider determines whether you can reliably scale.
| Metric | Key Focus | Business Impact | Novita AI / DeepSeek-OCR2 Context |
| Context Length | Token limit | Fewer chunks → fewer calls → simpler pipelines | 8,192-token context helps keep multi-page parsing in one pass |
| Token Cost | API pricing | Directly impacts ROI for large-scale extraction | Optimized pricing for high-volume OCR workloads (details below) |
| Latency (TTFT/TPOT) | Response speed | Improves user-facing OCR experiences | Low latency for faster previews and responsive apps |
| Throughput | RPS / concurrency | Enables batch processing and peak traffic handling | High concurrency capacity for batch + concurrent jobs |
| Integration | Compatibility | Ship faster by reusing existing tooling | Works with OpenAI-compatible tooling; also supports Anthropic-style integration |
Why Should You Choose Novita AI?
Note: In addition to OpenAI-compatible APIs, Novita AI also provides Anthropic-compatible interfaces, allowing teams to reuse existing Claude-style tooling and prompts with minimal changes.
Development Efficiency
Faster integration = faster time-to-value. Novita offers an OpenAI-compatible interface, so most teams can integrate OCR2 by only changing:
- base_url:
https://api.novita.ai/openai - api_key:
<Your API Key> - model name:
deepseek/deepseek-ocr-2
Cost Advantage
Novita lists OCR2 with extremely straightforward pricing: the same low rate for input and output tokens, which simplifies forecasting for OCR-heavy workloads.
And because Novita runs serverless endpoints, you typically avoid the operational burden of:
- provisioning GPUs,
- autoscaling inference servers,
- maintaining CUDA + inference stacks.
DeepSeek OCR2’s API Price
On Novita’s pricing page, deepseek/deepseek-ocr-2 is listed as:
- Input: $0.03 / 1M tokens
- Output: $0.03 / 1M tokens
DeepSeek OCR2 API Access
Quickstart: Try DeepSeek OCR2 Instantly in Novita Playground
The fastest way to validate OCR2 for your documents is to run a few real samples in the Novita Playground—no setup required
⚠ Note: For deterministic and stable outputs, please set both
temperatureandtop_kto0. This disables randomness and ensures the model produces consistent results across runs.
Get an API Key
- Step 1: Create or Login to Your Account
Visit [**https://novita.ai**](https://novita.ai) and sign up or log in to your existing account
- Step 2: Navigate to Key Management
After logging in, find “API Keys”

- Step 3: Create a New Key
Click the “Add New Key” button.

- Step 4: Save Your Key Immediately
Copy and store the key as soon as it is generated; it is usually shown only once and cannot be retrieved later. Keep the key in a secure location such as a password manager or encrypted notes
API Usage (Python)
Use the following code examples to integrate with our API:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-ocr-2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)Although the example above uses Python, Novita’s API works the same way in other languages such as TypeScript, Java, Go, and Shell—only the client library changes.
Conclusion
DeepSeek OCR2 upgrades document intelligence by shifting visual encoding from fixed scanning to semantic, causally-informed reading—especially valuable for complex layouts like tables, multi-column PDFs, and dense forms. With Novita AI as your OCR2 API provider, you get OpenAI-compatible integration, fast onboarding, and transparent pricing at $0.03 per 1M input tokens and $0.03 per 1M output tokens. If you’re building production OCR workflows (PDF → Markdown/JSON, invoice extraction, doc-to-RAG), Novita is a clean, scalable path from prototype to throughput.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Frequently Asked Questions
Does DeepSeek support OCR?
Yes. DeepSeek provides OCR capabilities through DeepSeek OCR2, its second-generation OCR model designed for document and image text recognition with strong layout understanding.
Is DeepSeek OCR free?
DeepSeek OCR2 is open-source at the model level, but API usage is not free.
By using Novita AI, you get cost-efficient, transparent, pay-as-you-go pricing with no infrastructure overhead—making it far more practical and economical than self-hosting for production use.
How to access DeepSeek OCR?
You can access DeepSeek OCR2 either by self-hosting the open-source model or by using a cloud API provider like Novita AI, which offers instant API access, a playground, and SDK-compatible integration.



