

L’OCR n’est plus seulement une « extraction de texte ». Les équipes modernes ont besoin d’intelligence documentaire : ordre de lecture, mise en page, tableaux et sorties structurées à grande échelle, sans les tarifs prohibitifs des solutions OCR entreprise. Le DeepSeek OCR2 pousse cette tendance encore plus loin grâce à un nouveau paradigme d’encodage visuel, et Novita AI permet de le déployer en production de manière pratique via une API et une tarification transparente des tokens.
Essayer DeepSeek OCR 2 maintenant
Qu’est-ce que le DeepSeek OCR2
Introduction générale
Le DeepSeek-OCR 2 est un modèle de reconnaissance de documents multimodal développé par DeepSeek AI, présenté comme une mise à niveau du DeepSeek-OCR (Gen 1). Sa principale évolution est le DeepEncoder V2, qui passe d’un traitement visuel rigide de type « balayage raster » (haut-gauche → bas-droite) à une lecture sémantique informée par la causalité, plus proche de la façon dont les humains suivent les structures logiques des documents complexes.
Les pipelines OCR traditionnels échouent souvent sur les PDF multicolonnes, les états financiers denses, les tableaux mélangés à des notes de bas de page et les formulaires avec un ordre de lecture complexe. L’OCR2 est conçu pour comprendre la page, et pas seulement pour « reconnaître des caractères ».
| Fonctionnalité | DeepSeek OCR2 |
| Organisation | DeepSeek AI |
| Type de modèle | Reconnaissance de documents multimodal (OCR + compréhension de la mise en page) |
| Innovation clé | Le DeepEncoder V2 réordonne les tokens visuels en fonction de la sémantique de l’image (« balayage fixe » → « raisonnement sémantique ») |
| Fenêtre de contexte / Sortie maximale | 8 192 / 8 192 |
| Entrée / Sortie | Entrée : texte, image / Sortie : texte |
| Quantification | bf16 |
| Licence | Apache-2.0 |
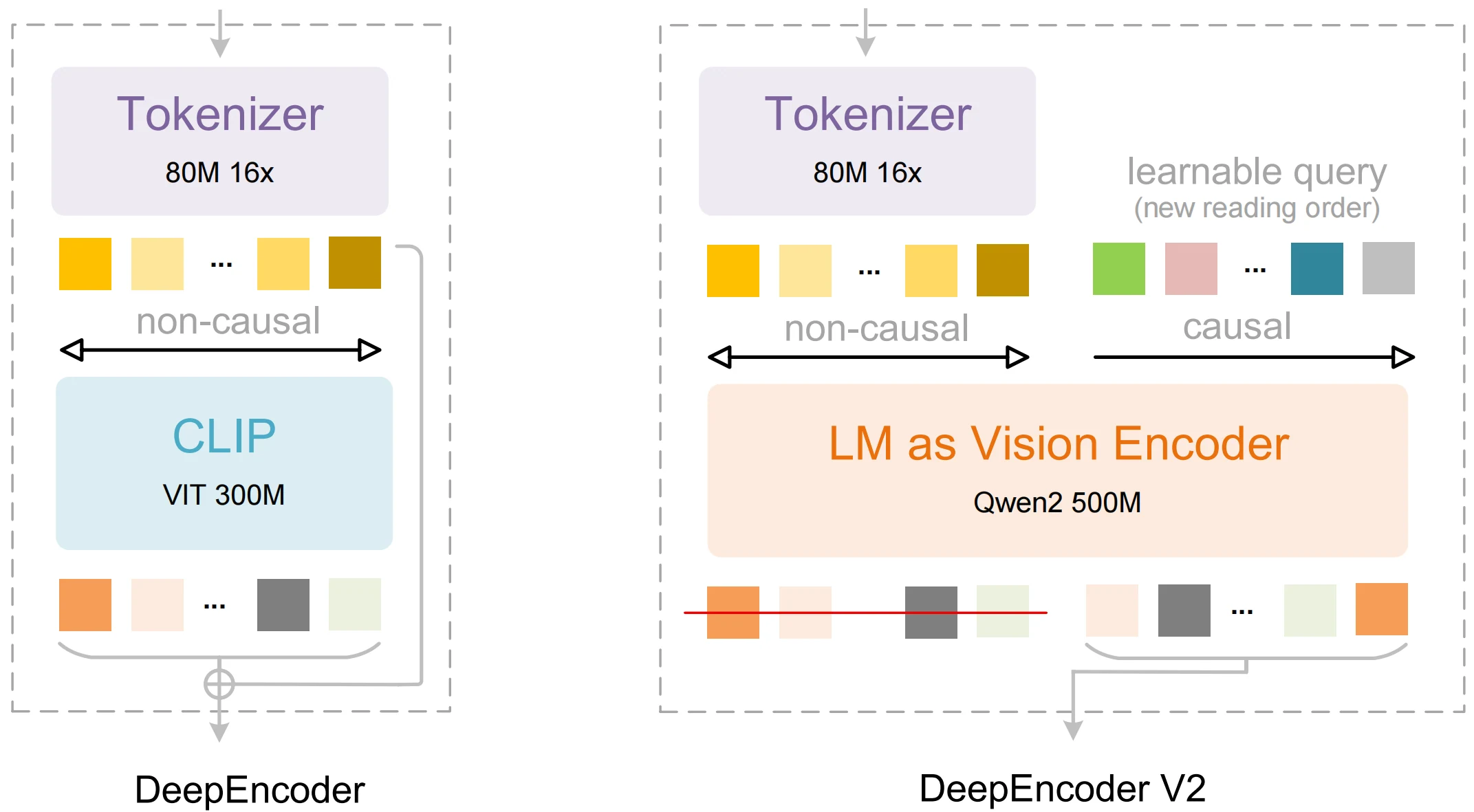
DeepSeek-OCR 2 : Flux causal visuel
🔍Au niveau global :
- Côté encodeur : Le DeepEncoder V2 peut réordonner les tokens visuels en fonction de la sémantique de l’image avant l’étape de décodage de type LLM.
- Conception système : L’OCR2 conserve le décodeur DeepSeek-3B-MoE, tout en remplaçant l’encodeur original basé sur CLIP par un composant LLM léger (Qwen2-0.5B).
- Efficacité des tokens : L’OCR2 cible la couverture des documents en utilisant un budget de tokens visuels contraint (estimé entre 256 et 1120 selon la complexité).
Performances aux benchmarks
Les améliorations de l’OCR2 sont particulièrement visibles sur les benchmarks centrés sur les documents :
- Sur OmniDocBench v1.5, le DeepSeek-OCR 2 atteint un score global de 91,09 %, soit un gain de +3,73 % par rapport à son prédécesseur, et réduit la distance d’édition de l’ordre de lecture de 0,085 à 0,057.
- L’OmniDocBench est conçu pour évaluer l’analyse de PDF dans des cas réels sur des types de documents, des mises en page et des langues variés.
Si vous développez des flux de travail documentaires (ingestion de factures, traitement des sinistres, PDF de conformité, RAG sur des manuels), ces métriques sont plus importantes que la « précision OCR » générique, car elles mesurent la compréhension de la structure et de la mise en page, et pas seulement la reconnaissance au niveau des caractères.
Comment évaluer les fournisseurs d’API IA : les 5 indicateurs clés
Choisir un modèle n’est que la moitié de la décision : le fournisseur détermine si vous pouvez mettre à l’échelle de manière fiable.
| Indicateur | Focus clé | Impact business | Contexte Novita AI / DeepSeek-OCR2 |
| Longueur de contexte | Limite de tokens | Moins de segments → moins d’appels → pipelines plus simples | Un contexte de 8 192 tokens permet de conserver l’analyse de plusieurs pages en une seule passe |
| Coût des tokens | Tarification de l’API | Impact direct sur le ROI pour les extractions à grande échelle | Tarification optimisée pour les charges de travail OCR à haut volume (détails ci-dessous) |
| Latence (TTFT/TPOT) | Vitesse de réponse | Améliore les expériences OCR côté utilisateur | Faible latence pour des aperçus plus rapides et des applications réactives |
| Débit | RPS / concurrence | Permet le traitement par lots et la gestion des pics de trafic | Capacité de concurrence élevée pour les tâches par lots et simultanées |
| Intégration | Compatibilité | Déploiement plus rapide en réutilisant les outils existants | Compatible avec les outils OpenAI ; prend également en charge l’intégration de style Anthropic |
Pourquoi choisir Novita AI ?
Remarque : En plus des API compatibles OpenAI, Novita AI propose également des interfaces compatibles Anthropic, permettant aux équipes de réutiliser leurs outils et prompts de style Claude existants avec des modifications minimales.
Efficacité de développement
Une intégration plus rapide = une valeur ajoutée plus rapide. Novita propose une interface compatible OpenAI, donc la plupart des équipes peuvent intégrer l’OCR2 en ne modifiant que :
base_url:https://api.novita.ai/openaiapi_key:<Votre clé API>- nom du modèle :
deepseek/deepseek-ocr-2
Avantage de coût
Novita propose une tarification extrêmement simple pour l’OCR2 : le même tarif bas pour les tokens d’entrée et de sortie, ce qui simplifie les prévisions pour les charges de travail fortement orientées OCR.
Et comme Novita utilise des points de terminaison serverless, vous évitez généralement la charge opérationnelle liée à :
- l’approvisionnement en GPUs,
- la mise à l’échelle automatique des serveurs d’inférence,
- la maintenance des piles CUDA + inférence.
Tarif de l’API DeepSeek OCR2
Sur la page de tarification de Novita, le modèle deepseek/deepseek-ocr-2 est listé comme suit :
- Entrée : 0,03 $ / 1 million de tokens
- Sortie : 0,03 $ / 1 million de tokens
En savoir plus sur la tarification
Accès à l’API DeepSeek OCR2
Démarrage rapide : essayez DeepSeek OCR2 instantanément dans le playground Novita
La façon la plus rapide de valider l’OCR2 pour vos documents est d’exécuter quelques échantillons réels dans le playground Novita – aucune configuration requise
⚠ Remarque : Pour des sorties déterministes et stables, veuillez définir
temperatureettop_kà0. Cela désactive l’aléatoire et garantit que le modèle produit des résultats cohérents d’une exécution à l’autre.
Obtenir une clé API
-
Étape 1 : Créer un compte ou se connecter à votre compte existant Rendez-vous sur
[**https://novita.ai**](https://novita.ai)et inscrivez-vous ou connectez-vous à votre compte existant -
Étape 2 : Accéder à la gestion des clés Après vous être connecté, recherchez « Clés API »

-
Étape 3 : Créer une nouvelle clé Cliquez sur le bouton « Ajouter une nouvelle clé ».

-
Étape 4 : Enregistrez votre clé immédiatement Copiez et stockez la clé dès qu’elle est générée ; elle n’est généralement affichée qu’une seule fois et ne peut pas être récupérée ultérieurement. Conservez la clé dans un emplacement sécurisé comme un gestionnaire de mots de passe ou des notes chiffrées.
Utilisation de l’API (Python)
Utilisez les exemples de code suivants pour intégrer notre API :
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-ocr-2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
Bien que l’exemple ci-dessus utilise Python, l’API de Novita fonctionne de la même manière dans d’autres langages comme TypeScript, Java, Go et Shell – seule la bibliothèque cliente change.
Conclusion
Le DeepSeek OCR2 améliore l’intelligence documentaire en passant d’un encodage visuel par balayage fixe à une lecture sémantique informée par la causalité – particulièrement précieux pour les mises en page complexes comme les tableaux, les PDF multicolonnes et les formulaires denses. Avec Novita AI comme fournisseur d’API OCR2, vous bénéficiez d’une intégration compatible OpenAI, d’un onboarding rapide et d’une tarification transparente à 0,03 $ par million de tokens d’entrée et 0,03 $ par million de tokens de sortie. Si vous développez des flux de travail OCR en production (PDF → Markdown/JSON, extraction de factures, doc-to-RAG), Novita est une voie propre et scalable du prototype au traitement à haut débit.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle des projets.
Foire aux questions
DeepSeek prend-il en charge l’OCR ? Oui. DeepSeek propose des fonctionnalités OCR via le DeepSeek OCR2, son modèle OCR de deuxième génération conçu pour la reconnaissance de texte dans des documents et des images, avec une forte compréhension de la mise en page.
L’OCR DeepSeek est-il gratuit ?
Le DeepSeek OCR2 est open source au niveau du modèle, mais l’utilisation de l’API n’est pas gratuite.
En utilisant Novita AI, vous bénéficiez d’une tarification transparente, économique et à l’usage, sans frais d’infrastructure – ce qui est bien plus pratique et économique que l’auto-hébergement pour une utilisation en production.
Comment accéder à l’OCR DeepSeek ? Vous pouvez accéder au DeepSeek OCR2 soit en auto-hébergeant le modèle open source, soit en utilisant un fournisseur d’API cloud comme Novita AI, qui propose un accès API instantané, un playground et une intégration compatible SDK.



