

Wichtige Highlights
Llama 3.3 70B: Ein von Meta entwickeltes Sprachmodell mit 70 Milliarden Parametern.
Technische Merkmale: Verwendet einen optimierten Transformer mit GQA, unterstützt 8 Sprachen, ermöglicht Funktionsaufrufe (Function Calling) und erzielt hohe Benchmark-Werte (MMLU Chat: 86,0).
Hardware-Anforderungen: Erfordert mindestens 24 GB VRAM und 32 GB RAM.
Anwendungsfälle: Geeignet für Programmierung, Content-Erstellung, Bildung und Kundenservice.
Vergleich mit anderen Modellen: Bietet ein besseres Kosten-Nutzen-Verhältnis und mehrsprachige Fähigkeiten im Vergleich zu Mitbewerbern.
Zugang: Verfügbar über Online-Plattformen, lokale Bereitstellung, APIs oder Cloud-GPUs.
Meta’s Llama 3.3 70B Modell, veröffentlicht am 6. Dezember 2024, stellt einen bedeutenden Fortschritt im Bereich der großen Sprachmodelle (LLMs) dar und bietet eine ausgewogene Kombination aus Leistung und Effizienz. Dieser Artikel bietet einen technischen Überblick über Llama 3.3 70B und beschreibt dessen Architektur, Fähigkeiten und praktische Anwendungen. Er behandelt außerdem den Vergleich mit anderen Modellen, die Hardware-Anforderungen und die Zugangsmöglichkeiten.
Was ist Llama 3.3 70B?
Llama 3.3 70B ist ein instruktions-getuntes, rein textbasiertes großes Sprachmodell mit 70 Milliarden Parametern, das von Meta entwickelt wurde. Es ist für fortgeschrittene Aufgaben der natürlichen Sprachverarbeitung (NLP) konzipiert und legt Wert auf ein Gleichgewicht zwischen Leistung und Ressourceneffizienz. Das Modell ist nicht dafür ausgelegt, Bilder oder Audio zu verarbeiten. Llama 3.3 wird nur als instruktions-getuntes Modell angeboten; eine vortrainierte Version ist nicht verfügbar.
Architektur
- Optimierte Transformer-Architektur: Llama 3.3 70B nutzt eine optimierte Transformer-Architektur für verbesserte Leistung.
- Grouped-Query Attention (GQA): Das Modell verwendet Grouped-Query Attention (GQA), um die Verarbeitungseffizienz und die Skalierbarkeit der Inferenz zu verbessern.
- Trainingsdaten: Das Modell wurde auf einem riesigen Datensatz von 15 Billionen Tokens trainiert, unter Verwendung einer neuen Mischung öffentlich zugänglicher Online-Daten. Es verwendet Supervised Fine-Tuning (SFT) und Reinforcement Learning with Human Feedback (RLHF). Die Trainingsdaten umfassen eine breite Sammlung von Sprachen, wobei jedoch nur acht offiziell unterstützt werden.
- Tokenizer: Das Modell verwendet einen textbasierten Tokenizer. Sie können die Token-Anzahl in Python ermitteln oder eine kosteneffiziente API wählen, um die Kosten pro Million Tokens für Prompt und Completion zu senken.
- Quantisierung: Die Modellgröße variiert je nach Quantisierungsstufe. Beispielsweise benötigt die 4-Bit-quantisierte Version etwa 35 GB VRAM.
Unterstützte Sprachen
Llama 3.3 70B ist ein mehrsprachiges Modell, das offiziell acht Sprachen unterstützt: Englisch, Deutsch, Französisch, Italienisch, Portugiesisch, Hindi, Spanisch und Thailändisch. Obwohl das Modell auf einer breiteren Palette von Sprachen trainiert wurde, erreicht seine Leistung in nicht unterstützten Sprachen möglicherweise nicht die Sicherheits- und Hilfreichkeitsschwellen.
Funktionsaufruf (Function Calling)
Llama 3.3 70B unterstützt Funktionsaufrufe. Funktionsaufrufe ermöglichen es dem Modell, mit externen Systemen, APIs und Tools zu interagieren. Sie erlauben dem LLM zu erkennen, wann eine bestimmte Aufgabe eine externe Funktion oder ein Tool erfordert, und dann strukturierte Daten, normalerweise im JSON-Format, auszugeben, um diese Funktion auszuführen. Diese strukturierten Daten enthalten den Namen der Funktion und die erforderlichen Argumente. Um Funktionsaufrufe mit Llama 3.3 zu implementieren, folgen Sie dieser Anleitung: Llama 3.3 70B Function Calling: Seamless Integration for Better Performance.
Llama 3.3 70B Benchmark
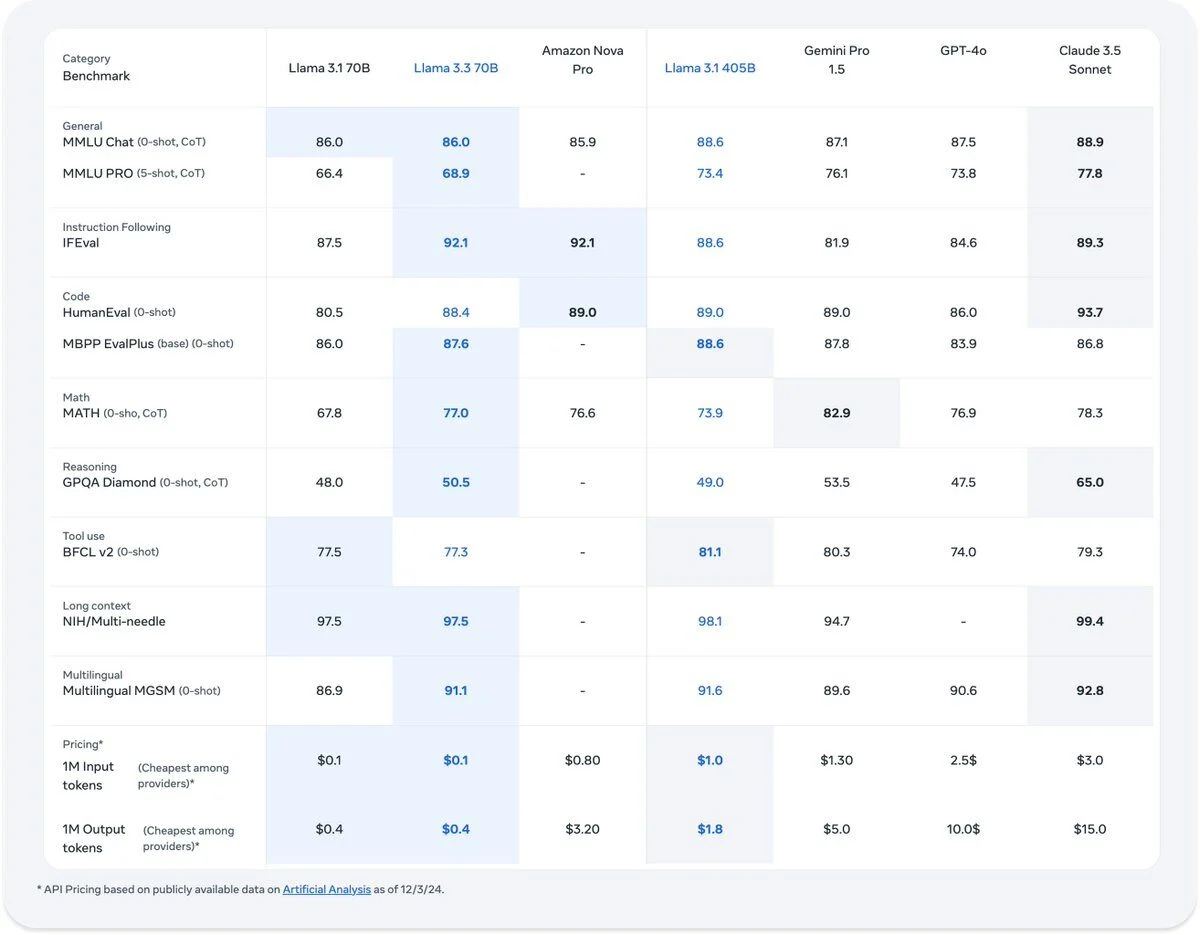
Allgemeines Wissen und logisches Denken
- MMLU Chat (0-shot, CoT): 86,0
- MMLU PRO (5-shot, CoT): 68,9
Llama 3.3 70B schneidet bei Aufgaben des allgemeinen Wissens und des logischen Denkens sehr gut ab. Die hohen Werte bei MMLU Chat und IFEval zeigen starke Fähigkeiten in diesen Bereichen. Der MMLU PRO-Wert ist ebenfalls respektabel, wenn auch etwas niedriger als bei einigen anderen Modellen.
Befolgung von Anweisungen
- IFEval: 92,1
Der IFEval-Wert ist außergewöhnlich hoch und zeigt, dass Llama 3.3 70B bei Aufgaben zur Befolgung von Anweisungen hervorragend abschneidet. Dies deutet darauf hin, dass das Modell sehr effektiv darin ist, Anweisungen genau zu verstehen und auszuführen.
Programmierfähigkeiten
- HumanEval (0-shot): 88,4
- MBPP EvalPlus (base): 87,6
Llama 3.3 70B zeigt starke Programmierfähigkeiten, mit hohen Werten sowohl bei HumanEval als auch bei MBPP EvalPlus. Dies deutet auf ein robustes Verständnis und eine hohe Generierungsfähigkeit bei Programmieraufgaben hin.
Mathematik und symbolisches Denken
- MATH (0-shot, CoT): 77,0
- GQA Diamond (0-shot, CoT): 50,5
In Mathematik und symbolischem Denken schneidet Llama 3.3 70B beim MATH-Benchmark gut ab, was auf starke Fähigkeiten beim Lösen mathematischer Probleme hinweist. Der GQA Diamond-Wert ist moderat und deutet auf Verbesserungspotenzial bei bestimmten Denkaufgaben hin.
Mehrsprachige Fähigkeiten
- Multilingual MGSM (0-shot): 91,1
Llama 3.3 70B schneidet bei mehrsprachigen Aufgaben außergewöhnlich gut ab, wie der hohe Wert im Multilingual MGSM-Benchmark zeigt. Dies deutet auf starke Fähigkeiten im Umgang mit mehreren Sprachen hin.
Tool-Nutzung und Langkontext-Leistung
- BFLC v2 (0-shot): 77,3
- NIH/Multi-needle: 97,5
Bei Tool-Nutzung und Langkontext-Leistung schneidet Llama 3.3 70B gut ab, mit einem hohen Wert im NIH/Multi-needle-Benchmark, was auf starke Fähigkeiten im Umgang mit langen Texten hinweist. Der BFLC v2-Wert ist ebenfalls respektabel und deutet auf effektive Tool-Nutzungsfähigkeiten hin.
Weitere Informationen finden Sie in diesem Artikel: Llama 3.3 Benchmark: Key Advantages and Application Insights
Llama 3.3 70B Hardware-Anforderungen

Obwohl das Modell auf Zugänglichkeit ausgelegt ist, erfordert Llama 3.3 70B dennoch eine beträchtliche Menge VRAM. Es ist zwar effizienter als frühere Modelle, benötigt aber mindestens 24 GB VRAM für einen effektiven Betrieb. Zusätzlich zum VRAM benötigt das Modell mindestens 32 GB RAM, wobei 64 GB oder mehr empfohlen werden. Außerdem werden etwa 200 GB Speicherplatz benötigt. Dies macht den Betrieb des Modells auf Heimservern zu einer Herausforderung oder das Laden langsam aufgrund der begrenzten VRAM-Kapazität typischer Consumer-GPUs. API-Zugriff und Optimierungstechniken wie Quantisierung bieten praktische Alternativen für diejenigen mit begrenzten Ressourcen.
Fine-Tuning ermöglicht die Anpassung von LLaMA 3.3 70B für spezifische Aufgaben und verbessert Genauigkeit und Relevanz.
Obwohl die RTX 4090 eine leistungsstarke GPU ist, können ihre Speicherbeschränkungen das Fine-Tuning von LLaMA 3.3 70B erschweren.
Parameter-effiziente Fine-Tuning-Methoden (PEFT) wie LoRA und QLoRA können helfen, diese Herausforderungen zu mildern.
Darüber hinaus bedeutet dies, dass das Fine-Tuning dieses Modells erhebliche GPU-Ressourcen, insbesondere VRAM, erfordert. Techniken wie Quantisierung und PEFT können einige dieser Herausforderungen mildern, aber für vollständiges Parameter-Fine-Tuning sind häufig Cloud-basierte Lösungen oder High-End-GPUs erforderlich.
Anwendungsfälle für Llama 3.3 70B
Die Vielseitigkeit von Llama 3.3 70B macht es für eine breite Palette von Anwendungen geeignet:
Mehrsprachige Verarbeitung
- Mehrsprachige Chatbots und virtuelle Assistenten
- Echtzeit-Übersetzungsdienste
- Globale Kommunikationsassistenten für die mehrsprachige Kommunikation und Übersetzung
Content-Erstellung und -Verarbeitung
- Hochwertige Textgenerierung (Nachrichtenartikel, Blogs)
- Tools zur Unterstützung der Content-Erstellung
- Textzusammenfassung und -analyse
- Generierung von Marketinginhalten
Programmierung und Entwicklung
- Code-Generierung und Problemlösung
- Programmierunterstützung und Entwicklungshilfe
- Automatisiertes Testen und Projektanalyse
Bildung und Forschung
- Bildungswerkzeuge zur Erstellung von Lehrmaterialien
- Gestaltung personalisierter Lernpfade
- Forschungsanalyse und Unterstützung bei der Wissenserkundung
- Lernunterstützung und Wissenserwerb
Datenverarbeitung und -analyse
- Textklassifikation (Spam-Filterung, Stimmungsanalyse)
- Erkennung benannter Entitäten
- Synthetische Datengenerierung
Kundenservice und Kundenerfahrung
- Intelligente Kundendienstsysteme
- Fortschrittliche Frage-Antwort-Systeme mit intelligenten Antworten
Spezialisierte Fachanwendungen
- Mathematische Problemlösung und logisches Denken
- KI-gestützte Kreativtools
- Persönliches Informationsmanagement
Unternehmensanwendungen
- Groß angelegte Sprachmodellierung und Dialogsysteme für Unternehmen
- Tool-Integration mit externen Systemen und APIs
- Automatisierung komplexer Workflows
Diese Anwendungsszenarien zeigen das umfangreiche Potenzial von Llama 3.3 70B als vielseitiges, leistungsstarkes Sprachmodell in mehreren Bereichen.
Llama 3.3 70B im Vergleich zu anderen Modellen
Wie schneiden andere Modelle im Vergleich zu Llama 3.3 70B ab? Lassen Sie mich die wichtigsten Unterschiede aufschlüsseln:
- GPT-4o: Besser für komplexe Aufgaben, weniger anpassbar, teurer
- Qwen 2.5 72B: Stärker in Allgemeinwissen und Mathematik, schwächer in Programmierung und Geschwindigkeit
- Llama 3.1 405B: Breiteres Wissen, höhere Rechenanforderungen
- DeepSeek V3: Überlegene Programmierfähigkeiten, weniger kosteneffizient
- Llama 3.1 70B: Kosteneffizienter, geringere Leistung bei verschiedenen Aufgaben
- Mistral Nemo: Hervorragend in Textgenerierung, weniger geeignet für Spitzen-Benchmark-Werte
- Claude 3.5 Sonnet: Überlegen bei komplexem Denken und Programmierung, weniger kosteneffizient
- Mistral Large 2411: Besser für komplexe Workflows, schwächer in Allgemeinwissen
- QwQ: Spezialisiert auf fortgeschrittenes Denken und mathematische Aufgaben
- Llama 3.2 90B: Unterstützt multimodale Eingaben, langsamere Textverarbeitung
- Llama 3 (original): Kleineres Kontextfenster, weniger mehrsprachige Unterstützung
- Gemma 2 9B: Besser für spezifische Textgenerierungsaufgaben, schwächer in Programmierung und Mathematik
Llama 3.3 70B zeichnet sich durch seine Vielseitigkeit, Kosteneffizienz und starke Leistung bei Programmierung, Befolgung von Anweisungen und mehrsprachigen Anwendungen aus.
Wie man auf Llama 3.3 70B zugreift
1. Nutzung von Online-Plattformen für den Zugriff auf Llama 3.3 70B (z.B. Novita AI)
Sie können die LLM Playground-Seite von Novita AI für eine kostenlose Testversion finden! Dies ist die Testseite, die wir speziell für Entwickler bereitstellen! Wählen Sie das gewünschte Modell aus der Liste aus. Hier können Sie das Modell Llama 3.3 70B auswählen.
Llama 3.3 70B Demo jetzt testen!
2. Lokales Ausführen von Llama 3.3 70B
1. Python installieren und eine virtuelle Umgebung erstellen
2. Erforderliche Bibliotheken installieren:
Use pip install bitsandbytes for GPU optimization.
3. Die Hugging Face CLI installieren und anmelden:
pip install huggingface-cli
huggingface-cli login
4. Zugriff auf Llama-3.3 70b auf der Hugging Face Website anfordern.
5. Die Modelldateien mit der Hugging Face CLI herunterladen:
huggingface-cli download meta-llama/Llama-3.3-70B-Instruct --include "original/*" --local-dir Llama-3.3-70B-Instruct
6. Das Modell lokal mit der Hugging Face Transformers-Bibliothek laden:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "meta-llama/Llama-3.3-70B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id, device_map="auto", torch_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
7. Inferenz mit dem geladenen Modell und Tokenizer durchführen.
3.Zugriff auf kostenlose Llama 3.3 70B APIs (z.B. Novita AI)
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Model Library.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.

Schritt 4: Holen Sie sich Ihren API-Schlüssel
Um sich bei der API zu authentifizieren, stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Gehen Sie auf die Seite „Settings“, um den API-Schlüssel wie im Bild gezeigt zu kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.

Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring to: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
Bei der Registrierung stellt Novita AI ein Guthaben von $0,5 zur Verfügung, um Ihnen den Einstieg zu erleichtern!
Wenn das kostenlose Guthaben aufgebraucht ist, können Sie kostenpflichtig weiternutzen.
4.Zugriff auf Llama 3.3 70b auf Cloud-GPUs (z.B. Novita AI)
Schritt 1: Klicken Sie auf die GPU-Instanz
Wenn Sie ein neuer Abonnent sind, registrieren Sie bitte zuerst Ihr Konto. Klicken Sie dann auf die Schaltfläche GPU-Instanz auf unserer Webseite.
SCHRITT 2: Vorlage und GPU-Server
Sie können Ihre eigene Vorlage auswählen, einschließlich PyTorch, TensorFlow, CUDA, Ollama, je nach Ihren spezifischen Anforderungen. Darüber hinaus können Sie auch Ihre eigenen Vorlagendaten erstellen, indem Sie auf den unteren Button klicken.
Unser Dienst bietet Zugriff auf leistungsstarke GPUs wie die NVIDIA RTX 4090, jede mit beträchtlichem VRAM und RAM, um sicherzustellen, dass selbst die anspruchsvollsten KI-Modelle effizient trainiert werden können. Sie können basierend auf Ihren Anforderungen auswählen.
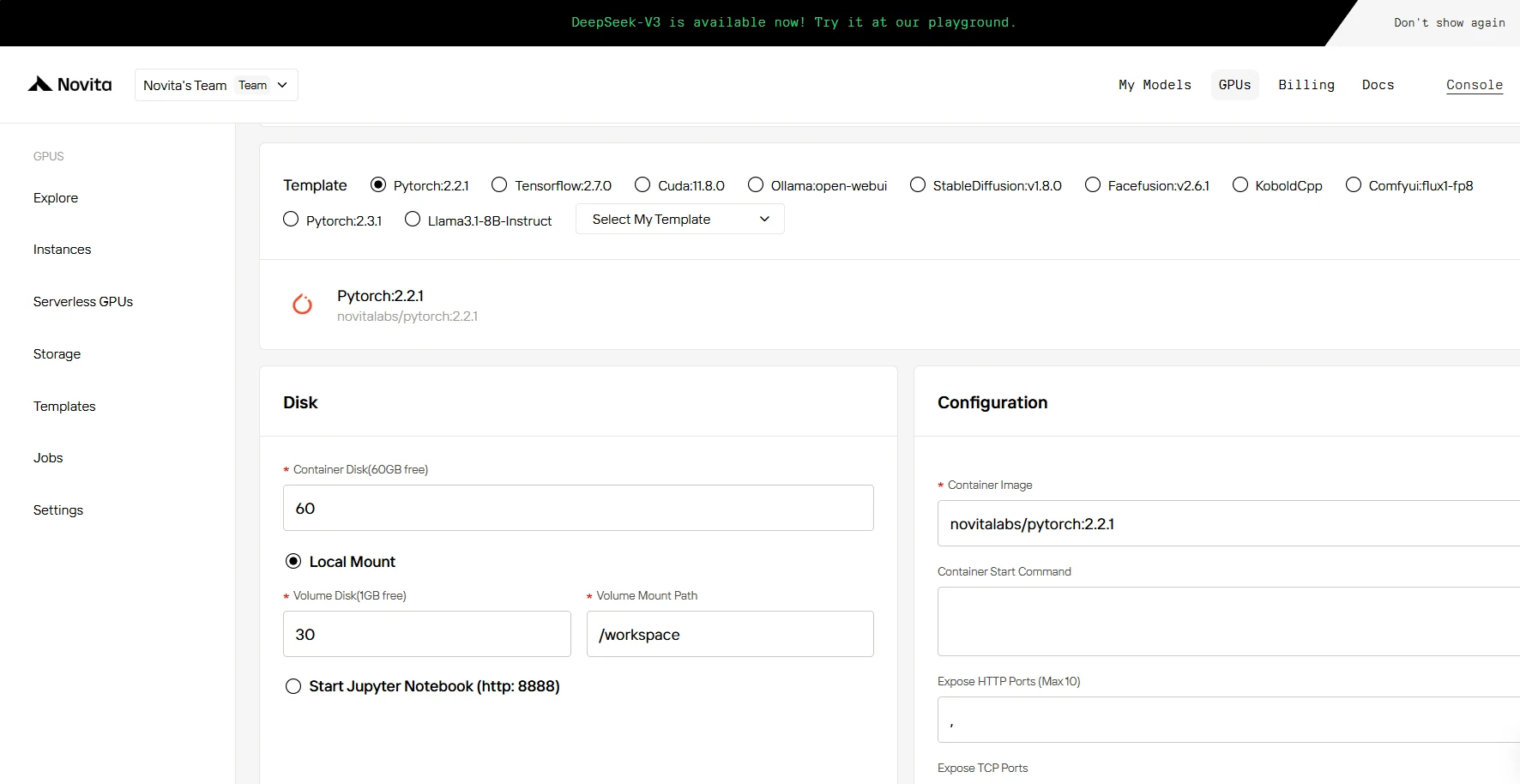
SCHRITT 3: Bereitstellung anpassen
In diesem Abschnitt können Sie diese Daten nach Ihren eigenen Bedürfnissen anpassen. Es gibt 60 GB kostenlosen Speicher im Container-Disk und 1 GB kostenlosen Speicher im Volume-Disk. Wenn das kostenlose Limit überschritten wird, fallen zusätzliche Gebühren an.
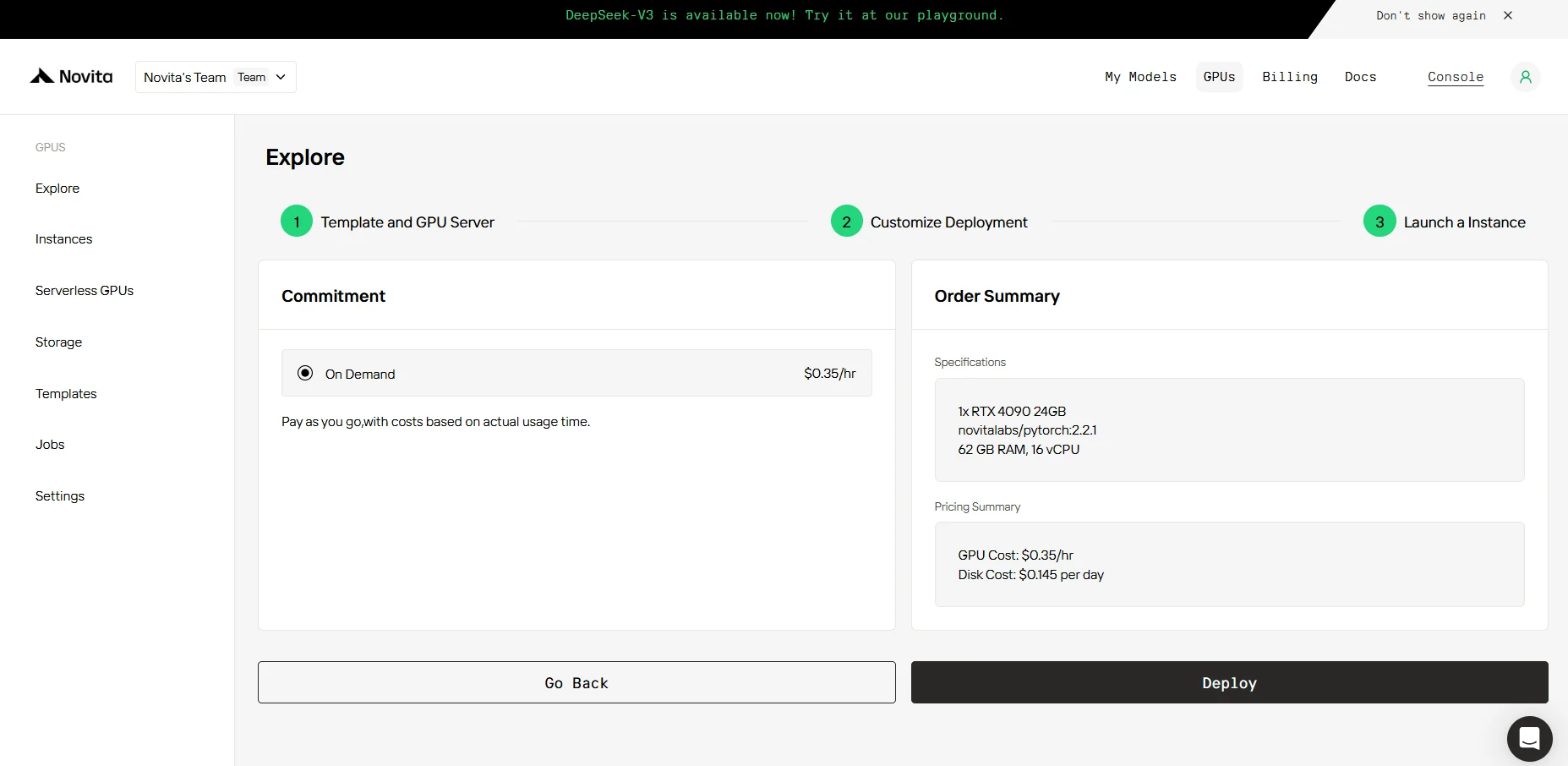
SCHRITT 4: Starten Sie eine Instanz
Ob für Forschung, Entwicklung oder Bereitstellung von KI-Anwendungen – die Novita AI GPU-Instanz bietet ein leistungsstarkes und effizientes GPU-Computing-Erlebnis in der Cloud.
Fazit
Llama 3.3 70B stellt einen bedeutenden Fortschritt in der Zugänglichkeit und Effizienz großer Sprachmodelle dar. Seine beeindruckende Leistung, gepaart mit den relativ moderaten Ressourcenanforderungen, macht es zu einer praktischen Wahl für eine Vielzahl von Anwendungen, von mehrsprachigen Chatbots bis hin zur Programmierunterstützung. Ob über die API oder lokal ausgeführt – Llama 3.3 70B bietet ein leistungsstarkes Werkzeug sowohl für Entwickler als auch für Forscher.
Ist Llama 3.3 70B kostenlos nutzbar?
Llama 3.3 ist ein Open-Source-Modell, das kostenlos heruntergeladen und genutzt werden kann; der Zugriff über Drittanbieter-Dienste kann jedoch Kosten verursachen.
Kann Llama 3.3 auf Standard-Entwicklerhardware ausgeführt werden?
Ja, es ist für den Betrieb auf gängigen GPUs und entwicklertauglichen Workstations ausgelegt.
Wie groß ist Llama 3.3 70B?
Das Modell ist etwa 40–43 GB groß.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen unterstützt. Integrierte APIs, serverlose Anwendungen, GPU-Instanzen – die kosteneffizienten Tools, die Sie brauchen. Verzichten Sie auf Infrastruktur, starten Sie kostenlos und verwirklichen Sie Ihre KI-Vision.



