

Key Highlights
Model Overview
Llama 3.3 70b has faster text processing speed, which is ideal for large-scale text generation
QwQ is an experimental model focused on advanced AI reasoning in mathematics and coding.
Model Differences
Llama 3.3 70B has 70 billion parameters and a context window of 128k tokens.
QwQ has 32 billion parameters and a context window of 32k tokens.
Language Support
Llama 3.3 70B supports 8 languages.
QwQ supports 29 languages.
Performance
Llama 3.3 70B excels in text generation and general benchmarks.
QwQ is designed for advanced reasoning and performs well in mathematical tasks.
Hardware Requirements
Llama 3.3 70B needs 24-48GB VRAM and runs on A100, H100, or RTX A6000 GPUs, ideally with dual A100s.
QwQ 32B uses 80GB VRAM at 16-bit, 40GB at 8-bit, or 20GB at 4-bit precision, compatible with RTX 3090/4090 when quantized.
If you’re looking to evaluate the Llama 3.3 70b on your own use-cases — Upon registration, Novita AI provides a $0.5 credit to get you started!
The landscape of large language models is constantly evolving, with new models offering unique strengths and capabilities. Two models that have recently garnered attention are Meta’s Llama 3.3 70B and Alibaba’s QwQ. This article provides a detailed comparison of these two models, focusing on their technical specifications, performance benchmarks, and practical applications. The analysis aims to be informational and technical rather than promotional.
Basic Introduction of Model
To begin our comparison, we first understand the fundamental characteristics of each model.
Llama 3.3 70b
- Release Date: December 6, 2024
- Model Scale:
- Key Features:
- Instruction-tuned text-only model
- Utilizes Grouped-Query Attention (GQA) for improved efficiency
- Optimized for multilingual dialogue and various text-based tasks
- Supports English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai
QWQ
- Release Date: November 28, 2024.
- Other Models:
- Key Features:
- Incorporates a unique self-questioning mechanism that allows it to introspect and improve its problem-solving skills over time.
- Excels in complex mathematical reasoning and coding tasks, achieving high scores on various benchmarks such as GPQA and MATH-500.
- Supports 29 languages
Model Comparison

Speed and Cost Comparison
If you want to test it yourself, you can start a free trial on the Novita AI website.
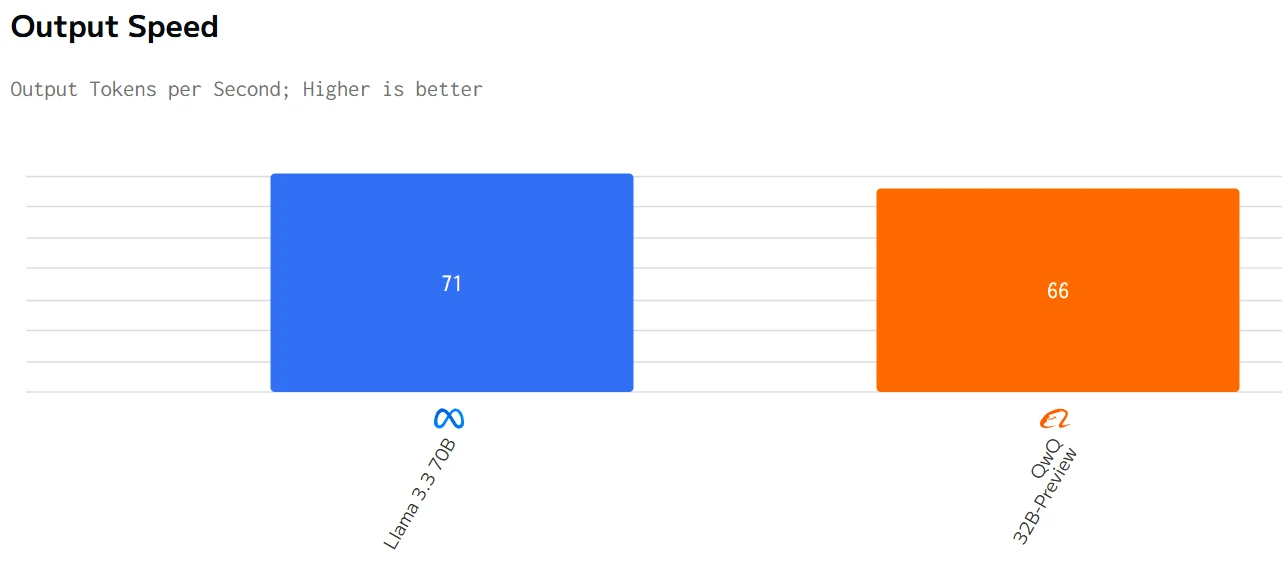
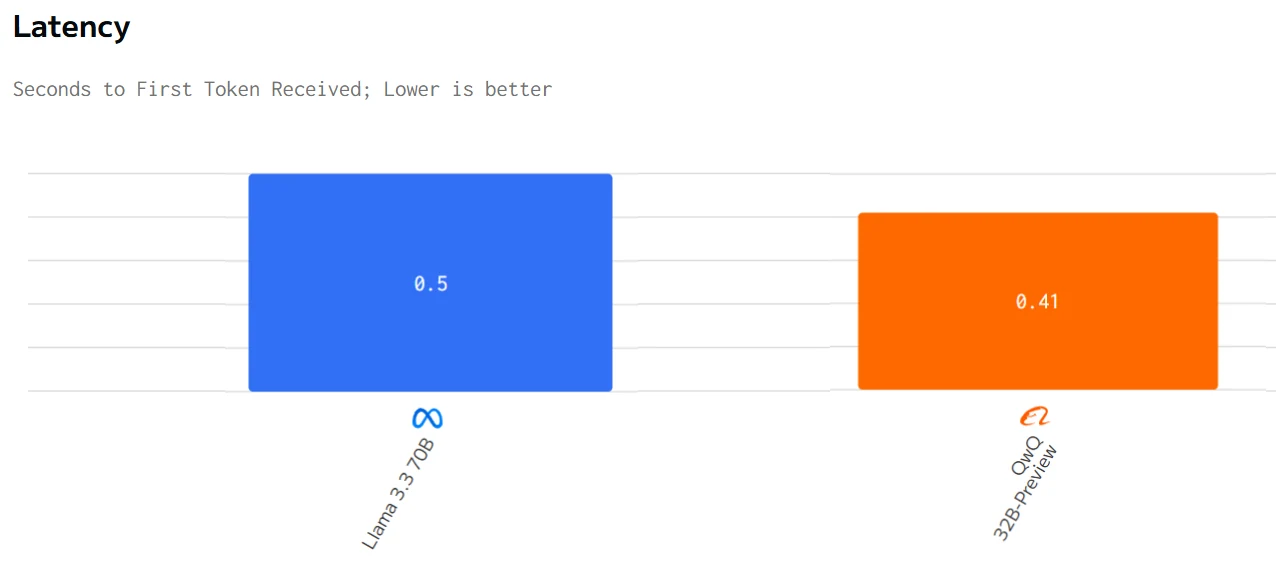
Speed Comparison
source from artificialanalysis
Cost Comparison
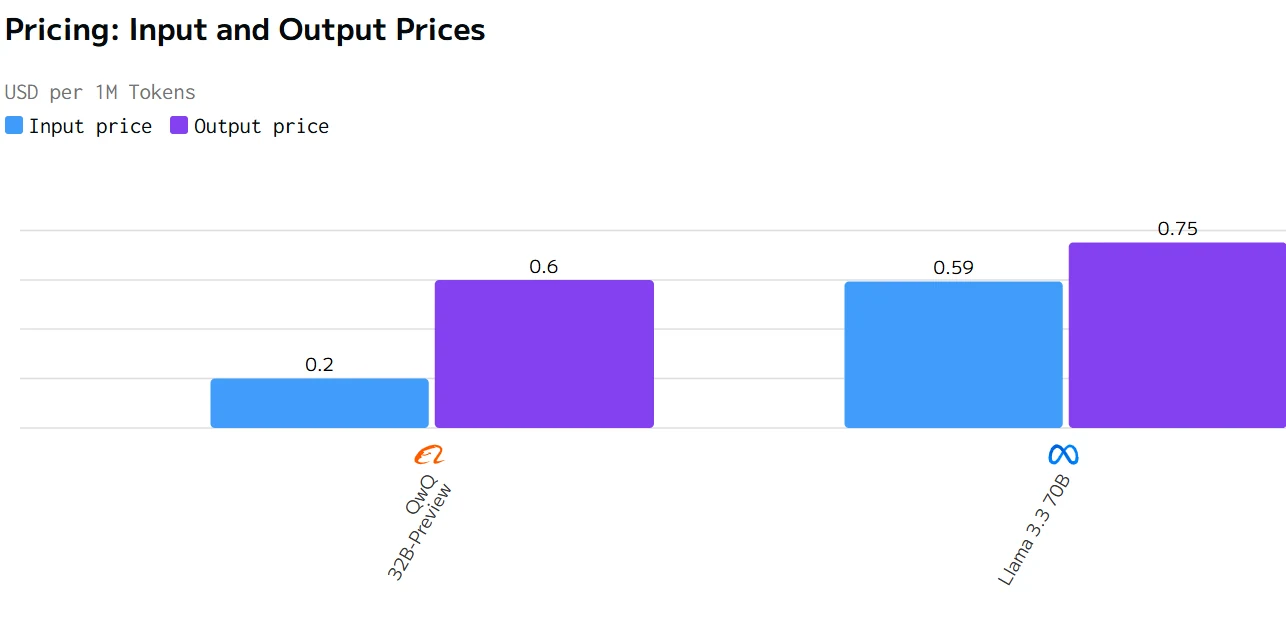
In summary, QwQ 32B has advantages in terms of pricing and latency, while Llama 3.3 70B performs better in output speed. The choice of model depends on the specific application requirements and budget.
Benchmark Comparison
Now that we’ve established the basic characteristics of each model, let’s delve into their performance across various benchmarks. This comparison will help illustrate their strengths in different areas.
| Benchmark Metrics | Llama 3.3 70B | qwq |
|---|---|---|
| MMLU | 86 | 71 |
| HumanEval | 86 | 85 |
| MATH | 76 | 91 |
In summary, Llama 3.3 70B excels in general language understanding and has a slight advantage in code generation, while QwQ demonstrates superior performance in mathematical reasoning tasks. The choice between these models should be based on the specific requirements of the task at hand. However, there is information explaining qwq excels in solving complex problems in mathematics and programming, surpassing state-of-the-art (SOTA) models in benchmarks like MATH-500 — a comprehensive set of 500 mathematics test cases — and the American Invitational Mathematics Examination (AIME), demonstrating impressive mathematical skills and problem-solving prowess.
If you would like to know more about the llama3.3 benchmark knowledge. You can view this article as follows:
If you want to see more comparisons between llama 3.3 and other models, you can check out these articles:
- Qwen 2.5 72b vs Llama 3.3 70b: Which Model Suits Your Needs?
- Llama 3.1 70b vs. Llama 3.3 70b: Better Performance, Higher Price
- Is Llama 3.3 70B Really Comparable to Llama 3.1 405B?
Hardware Requirements

In conclusion, both models require substantial VRAM and suitable GPUs to operate efficiently. The NVIDIA A100 and H100 are particularly well-suited for the Llama model, while the QwQ model can run on high-end consumer GPUs like the RTX series, especially when utilizing quantization techniques to reduce memory usage.
Applications and Use Cases
Llama 3.3 70B
- Instruction Following: Excels at interpreting and executing user instructions, suitable for task completion.
- Multilingual Dialogue: Supports conversations in multiple languages, making it ideal for global applications.
- Coding Assistance: Provides accurate code generation, debugging, and programming support across various languages.
- Natural Language Generation (NLG): Capable of content creation, summarization, and creative writing tasks.
- Synthetic Data Generation: Generates high-quality synthetic data for scenarios with privacy concerns or limited real-world data.
- Research and Development: Aids in literature review, hypothesis generation, and experimental design.
- Chatbots and Virtual Assistants: Powers intelligent conversational agents that can engage users in meaningful dialogues.
- Text Summarization and Analysis: Analyzes and condenses large volumes of text into concise summaries.
QWQ
- Education: Acts as a tutor for students, providing step-by-step guidance in mathematics and programming, helping them understand complex concepts.
- Software Development: Assists developers by generating code snippets, debugging existing code, and offering suggestions for optimizing algorithms.
- Research Assistance: Aids researchers in exploring scientific questions, performing data analysis, and summarizing relevant literature.
- Data Analysis: Analyzes large datasets to identify trends and correlations, providing insights that can inform decision-making.
- Problem-Solving: Breaks down complex problems into manageable parts, facilitating structured approaches to finding solutions.
- Scientific Reasoning: Engages in multi-step reasoning for scientific inquiries, making it useful for graduate-level problem-solving.
- Content Generation: Generates SEO-optimized titles and other content through innovative techniques like prompt chaining.
- Multilingual Support: While primarily focused on English, it can process and generate content in several languages, enhancing its usability across diverse linguistic contexts.
Accessibility and Deployment through Novita AI
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.

Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for pthon users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring to: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)Upon registration, Novita AI provides a $0.5 credit to get you started!
If the free credits is used up, you can pay to continue using it.
Both Llama 3.3 70B and QwQ offer unique strengths tailored to different applications. The Llama 3.3 70B excels in multilingual capabilities, broad use cases, and general dialogue performance, while the QwQ stands out with its advanced reasoning abilities in math and coding. The choice between these models will depend on the specific requirements of the task at hand.
Frequently Asked Questions
What are the key metrics for evaluating AI models?
Key metrics for evaluating AI models include accuracy, precision, recall, F1 score, latency, throughput, model size, memory usage, inference speed, and training cost.
How does Llama 3.3 70B compare to others?
Llama 3.3 70B demonstrates superior performance compared to previous models with enhanced context understanding, better reasoning capabilities, while requiring similar or less computational resources than competitors like GPT-4 or Claude 2.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.



