

Mixture of Experts (MoE) hat sich schnell zu einer der wichtigsten Designentscheidungen bei der Skalierung heutiger großer Sprachmodelle entwickelt. Anstatt jeden Parameter für jedes Token zu aktivieren, leitet MoE Eingaben selektiv durch eine kleine Gruppe von Experten, wodurch Effizienz und enorme Modellkapazität in Einklang gebracht werden. Dieser architektonische Wandel ermöglicht es Entwicklern, Modelle mit Hunderten von Milliarden Parametern zu erstellen, während die Inferenzkosten überschaubar bleiben.
In diesem Artikel stellen wir die Grundlagen von MoE vor, heben die architektonischen Unterschiede zwischen den führenden MoE-Modellen hervor und zeigen Ihnen, wie Sie diese in der Praxis nutzen können.
Kurze Einführung in Mixture-of-Experts (MoE)
Mixture of Experts (MoE) ist eine Methode des maschinellen Lernens, die ein KI-Modell in mehrere Teilnetzwerke, sogenannte „Experten“, aufteilt. Jeder Experte ist darauf trainiert, einen bestimmten Teil der Eingabedaten zu verarbeiten, und arbeitet dann gemeinsam mit den anderen, um die Aufgabe zu lösen. MoE verwendet eine Reihe spezialisierter Modelle sowie einen Gating-Mechanismus, um dynamisch die am besten geeigneten „Expertennetzwerke“ zur Verarbeitung jeder Eingabe auszuwählen.
Funktionsweise von MoE
1. Gating-Netzwerk (Router)
Im Zentrum von MoE steht das Gating-Netzwerk, das entscheidet, welche Experten jedes Eingabe-Token verarbeiten sollen. Anstatt jedes Token an alle Experten zu senden, aktiviert der Router selektiv die relevantesten, wodurch sowohl Effizienz als auch Spezialisierung gewährleistet werden.
2. MoE vs. Dense
MoE (Mixture of Experts) funktioniert, indem jedes Token nur durch eine kleine Teilmenge von Experten geleitet wird, die vom Gating ausgewählt werden. Dieser Ansatz ermöglicht es dem Modell, seine Gesamtkapazität deutlich zu erweitern, während die tatsächliche Berechnung kostengünstig bleibt. Unterschiedliche Experten spezialisieren sich auf verschiedene Eingabemuster, was eine stärkere Leistung bei komplexen Aufgaben ermöglicht, ohne den Rechenaufwand linear zu skalieren.
Im Gegensatz dazu senden Dense-Modelle jedes Token durch alle Experten oder Schichten, was das Design einfach, aber rechenintensiv macht. Der zentrale Unterschied besteht darin, dass MoE selektive Aktivierung für Effizienz nutzt, während Dense-Modelle auf vollständige Aktivierung für jede Eingabe angewiesen sind.
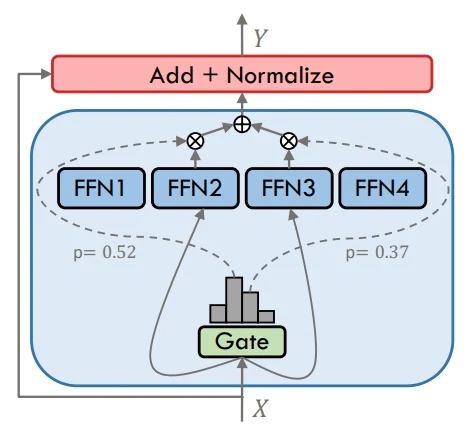
MoE
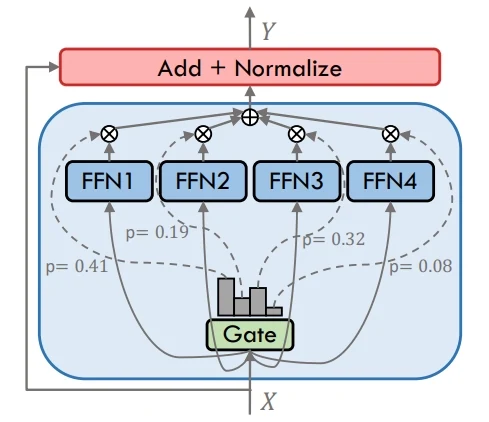
Dense
Referenz: A Survey on Mixure of Experts in Large Language Model. (Verfügbar unter: https://arxiv.org/abs/2407.06204)
Zentrale Vorteile von MoE
MoE hat sich aufgrund seiner einzigartigen Vorteile zur vorherrschenden Designentscheidung in modernsten KI-Systemen entwickelt:
- Massive Kapazität bei kontrolliertem Rechenaufwand: Sparse MoE ermöglicht es Modellen, die Anzahl der Parameter drastisch zu erhöhen, ohne dass der Rechenaufwand im gleichen Maße steigt. Dieses Design folgt dem Prinzip der bedingten Berechnung, bei der Ressourcen nur bei Bedarf zugewiesen werden. Dadurch ist es möglich, Modelle mit weit größerer Kapazität als Dense-Pendants bei gleichen Rechenkosten zu trainieren.
- Expertenspezialisierung: Unterschiedliche Experten spezialisieren sich natürlich auf unterschiedliche Muster oder Aufgaben, was die Leistung über ein breites Spektrum an Eingaben hinweg steigert und umfangreichere Fähigkeiten in großskaligen LLMs ermöglicht.
- Effizienz bei Training und Inferenz: Sparse MoE aktiviert nur eine kleine Teilmenge von Experten pro Token, was den hohen Overhead von Dense-Modellen reduziert und die Ressourcennutzung in großen Trainingsclustern verbessert.
- Praktische Einsatzszenarien: Sparse MoEs sind besonders effektiv in Umgebungen mit hohem Durchsatz und Zugriff auf viele Maschinen, wo sie unter einem festen Rechenbudget optimalere Ergebnisse liefern. Dense-Modelle eignen sich hingegen weiterhin für Umgebungen mit geringem Durchsatz oder sehr begrenztem VRAM, da ihre Einfachheit sie für kleine Bereitstellungen praktischer macht.
- Flexibilität beim Routing: Mit Routing-Strategien wie Top-1- oder Top-2-Gating erreicht Sparse MoE ein Gleichgewicht zwischen rechnerischer Effizienz und Ausdrucksstärke und passt sich unterschiedlichen Arbeitslasten und Skalierungsanforderungen an.
Angesichts dieser Vorteile überrascht es nicht, dass MoE weit verbreitet in modernsten großen Sprachmodellen eingesetzt wird. Im nächsten Abschnitt werfen wir einen Blick auf einige der einflussreichsten MoE-basierten Modelle des Jahres 2025 und untersuchen, wie sie diese Architektur implementieren und davon profitieren.
Führende MoE-Modelle im Jahr 2025
Überblick über Open-Source-MoE-Modelle: Architektonische Analyse
| Modell | Gesamtparameter | Aktivierte Parameter | Größe des Expertenpools | Aktive Experten pro Token |
| GPT OSS 120B | 116,8 Mrd. mit 36 Schichten | 5,1 Mrd. | 128 | 4 |
| GPT OSS 20B | 20,9 Mrd. mit 24 Schichten | 3,6 Mrd. | 32 | 4 |
| DeepSeek V3.1 | 671 Mrd. | 37 Mrd. | 256 Routed + 1 Shared | 8 |
| GLM 4.5 | 335 Mrd. | 32 Mrd. | 160 | 8 |
| Kimi K2 0905 | 1 Billion mit 61 Schichten | 32 Mrd. | 384 Routed + 1 Shared | 8 |
| Qwen3 Coder | 480 Milliarden mit 62 Schichten | 35 Mrd. | 160 | 8 |
| Llama 4 Scout | 109 Milliarden | 17 Milliarden | 16 | Nicht angegeben |
Jedes Modell hebt durch sein architektonisches Design unterschiedliche Prioritäten hervor:
- DeepSeek V3.1 und Kimi K2 0905 setzen auf außergewöhnlich große Expertenpools mit mehreren aktiven Experten pro Token. Diese Konfiguration maximiert die Spezialisierung und liefert starke Leistung bei komplexen Schlussfolgerungs- und Multi-Step-Aufgaben.
- GPT-OSS 120B verfolgt hingegen einen ausgewogeneren Ansatz, der einen mittelgroßen Expertenpool mit moderater Aktivierung kombiniert. Dies macht es für Unternehmensanwendungen geeignet, bei denen Stabilität und Skalierung nebeneinander bestehen müssen.
- GPT-OSS 20B verwendet eine leichtere Konfiguration mit weniger Experten, die für Szenarien optimiert ist, bei denen Latenz und Kosteneffizienz oberste Priorität haben – beispielsweise Echtzeit-Chatbots oder Bereitstellungen mit begrenzten Ressourcen.
- Qwen3 Coder ist auf codeorientierte Aufgaben ausgelegt und verfügt über eine ausgewogene MoE-Konfiguration, die starke Schlussfolgerungsfähigkeiten und effiziente Aktivierung kombiniert, um zuverlässige Leistung für Entwickleranwendungen zu liefern.
- Llama 4 Scout verfügt über ein kompaktes MoE-Design mit einem kleinen Expertenpool und reduzierter Aktivierungslast, was es zu einer praktischen Option für Anwendungen mit geringer Latenz oder Edge-Anwendungen macht.
Diese Variationen zeigen, wie MoE-Konfigurationen angepasst werden können, um unterschiedlichen Bereitstellungszielen zu entsprechen – von forschungsskalierter Erkundung und fortschrittlichen Agentensystemen bis hin zu leichtgewichtiger, produktionsreifer Inferenz.
Konstant bleibt jedoch die Nachfrage nach zuverlässiger Recheninfrastruktur. Die Ausführung von Modellen mit Milliarden oder sogar Billionen von Parametern erfordert nicht nur leistungsstarke GPUs, sondern auch Hochgeschwindigkeitsverbindungen und optimierte Pipelines. Für die meisten Teams bietet dies einen starken Anreiz, Cloud-GPU-Instanzen und verwaltete API-Dienste zu nutzen, die die Last der Wartung lokaler Cluster beseitigen und gleichzeitig Zugang zu modernsten MoE-Funktionen bieten.
Wie greifen Sie auf führende MoE-Modelle zu?
Lokale Bereitstellung
| Modell | VRAM (ca.) | Quantisierung | Empfohlene Hardware |
| GPT OSS 120B | 80 GB | MXFP4 | H100 x1 |
| GPT OSS 20B | 16 GB | MXFP4 | RTX 4090 x1 |
| DeepSeek V3.1 | 1,34 TB | 16-bit | H200 8-Karten-Cluster |
| GLM 4.5 | 717 GB | 16-bit | H100 x 16 / H200 x 8 |
| Kimi K2 0905 | 2,05 TB | 16-bit | H100/A100 80GB (x32) |
| Qwen3 Coder | 290 GB | Q4_K_M | A6000 x2 |
| Llama 4 Scout 17B | 216 GB | Int4 | H100 x1 |
Obwohl führende MoE-Modelle lokal mit massiven GPU-Anforderungen bereitgestellt werden können, bietet Novita AI optimierte Cloud-GPUs, die die Komplexität der Verwaltung teurer Infrastruktur beseitigen. Um flexible Optionen zu erkunden und den passenden Tarif für Ihre Arbeitslast zu finden, besuchen Sie unsere Seite Preise.
API-Integration
Möchten Sie einen noch einfacheren Weg? Wählen Sie einfach die APIs von Novita AI!
Novita AI bietet APIs für alle führenden MoE-Modelle mit langen Kontextfenstern zu äußerst wettbewerbsfähigen Preisen!
Schritt 1: Melden Sie sich an und greifen Sie auf die Modellbibliothek zu
Melden Sie sich bei Ihrem Konto an oder registrieren Sie sich neu und klicken Sie auf die Schaltfläche Modellbibliothek.

Testen Sie führende Modelle kostenlos!
Schritt 2: Wählen Sie Ihr Modell
Durchstöbern Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testphase
Starten Sie Ihre kostenlose Testphase, um die Funktionen des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung über die API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.
Schritt 5: Installieren Sie die API
Installieren Sie die API über den für Ihre Programmiersprache spezifischen Paketmanager.
Klicken Sie hier, um das detaillierte Tutorial aufzurufen.
Häufig gestellte Fragen
Was ist ein Mixture-of-Experts (MoE)-Modell?
MoE ist eine neuronale Netzwerkarchitektur, bei der viele „Experten“-Module existieren, aber nur eine kleine Teilmenge für jede Eingabe aktiviert wird. Dies erhöht die Gesamtkapazität ohne proportionalen Rechenaufwand.
Wie unterscheiden sich MoE-Modelle von Dense-Modellen?
Dense-Modelle aktivieren alle Parameter für jede Eingabe. MoE-Modelle aktivieren selektiv nur wenige Experten pro Token, was sie bei großem Maßstab rechnereffizienter macht.
Was sind geroutete Experten und gemeinsame Experten?
Geroutete Experten werden dynamisch von einem Router für jedes Token ausgewählt, während ein gemeinsamer Experte immer als Fallback verfügbar ist, um Stabilität und Fairness beim Routing zu gewährleisten.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern einen einfachen Weg zur Bereitstellung von KI-Modellen über unsere einfache API bietet und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.



