

A Mistura de Especialistas (MoE) surgiu rapidamente como uma das escolhas de design mais importantes para escalar os modelos de linguagem grandes atuais. Em vez de ativar cada parâmetro para cada token, a MoE roteia seletivamente as entradas por um pequeno conjunto de especialistas, equilibrando eficiência com capacidade massiva de modelo. Essa mudança arquitetural permite que desenvolvedores construam modelos com centenas de bilhões de parâmetros mantendo os custos de inferência controláveis.
Neste artigo, apresentamos os fundamentos da MoE, destacamos as diferenças arquiteturais entre os principais modelos MoE e mostramos como acessá-los na prática.
Breve Introdução à Mistura de Especialistas (MoE)
A Mistura de Especialistas (MoE) é um método de aprendizado de máquina que divide um modelo de IA em múltiplas sub-redes, chamadas de “especialistas”, cada uma treinada para lidar com uma parte específica dos dados de entrada, que trabalham juntas para realizar a tarefa. A MoE usa um conjunto de modelos especializados juntamente com um mecanismo de portão para escolher dinamicamente as “redes de especialistas” mais adequadas para processar cada entrada.
Como a MoE Funciona
1. Rede de Portão (Roteador)
No coração da MoE está a rede de portão, que decide quais especialistas devem processar cada token de entrada. Em vez de enviar cada token para todos os especialistas, o roteador ativa seletivamente os mais relevantes, garantindo tanto eficiência quanto especialização.
2. MoE vs Denso
A MoE (Mistura de Especialistas) funciona roteando cada token apenas por um pequeno subconjunto de especialistas escolhidos pelo portão. Essa abordagem permite que o modelo expanda sua capacidade geral significativamente mantendo o cálculo real acessível. Diferentes especialistas se especializam em diferentes padrões de entrada, permitindo um desempenho mais forte em tarefas complexas sem escalar o cálculo linearmente.
Em contraste, os modelos Denso enviam cada token por todos os especialistas ou camadas, o que torna o design direto, mas computacionalmente caro. A diferença chave é que a MoE aproveita a ativação seletiva para eficiência, enquanto os modelos Denso dependem de ativação total para cada entrada.
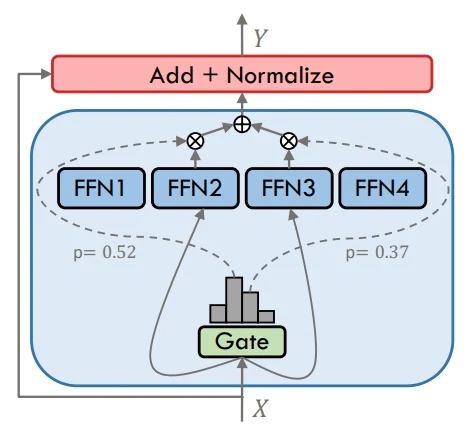
MoE
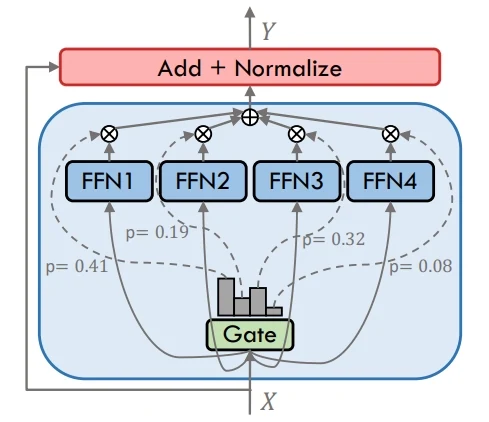
Denso
Referência: Um levantamento sobre Mistura de Especialistas em Modelos de Linguagem de Grande Porte. (Disponível em: https://arxiv.org/abs/2407.06204)
Principais Vantagens da MoE
A MoE se tornou a escolha de design dominante em sistemas de IA de ponta devido às suas vantagens únicas:
- Capacidade Massiva com Computação Controlada: A MoE esparsa permite que os modelos escalem os parâmetros drasticamente sem um aumento correspondente na demanda computacional. Esse design segue o princípio da computação condicional, onde os recursos são alocados apenas quando necessário, tornando possível treinar modelos com capacidade muito maior do que os contrapartes densos com o mesmo custo de computação.
- Especialização de Especialistas: Diferentes especialistas se especializam naturalmente em padrões ou tarefas distintas, aumentando o desempenho em uma ampla gama de entradas e permitindo capacidades mais ricas em LLMs em larga escala.
- Eficiência no Treinamento e na Inferência: A MoE esparsa ativa apenas um pequeno subconjunto de especialistas por token, reduzindo a sobrecarga pesada dos modelos densos e melhorando a utilização de recursos em grandes clusters de treinamento.
- Cenários de Implantação Práticos: As MoEs esparsas são particularmente eficazes em ambientes de alto throughput com acesso a muitas máquinas, onde entregam resultados mais otimizados sob um orçamento de computação fixo. Os modelos densos ainda podem ser adequados para configurações de baixo throughput ou VRAM muito limitada, já que sua simplicidade os torna mais práticos para implantações em pequena escala.
- Flexibilidade no Roteamento: Com estratégias de roteamento como portão top-1 ou top-2, a MoE esparsa alcança um equilíbrio entre eficiência computacional e poder expressivo, adaptando-se a diferentes cargas de trabalho e requisitos de escalabilidade.
Com essas vantagens, não é surpresa que a MoE tenha sido amplamente adotada em modelos de linguagem grandes de ponta. Na próxima seção, veremos alguns dos modelos baseados em MoE mais influentes de 2025, explorando como eles implementam e se beneficiam dessa arquitetura.
Modelos MoE de Ponta em 2025
Visão Geral dos Modelos MoE de Código Aberto: Análise Aprofundada da Arquitetura
| Modelo | Total de Parâmetros | Parâmetros Ativados | Tamanho do Pool de Especialistas | Especialistas Ativos por Token |
| GPT OSS 120B | 116,8B com 36 camadas | 5,1B | 128 | 4 |
| GPT OSS 20B | 20,9B com 24 camadas | 3,6B | 32 | 4 |
| DeepSeek V3.1 | 671B | 37B | 256 Roteados + 1 Compartilhado | 8 |
| GLM 4.5 | 335B | 32B | 160 | 8 |
| Kimi K2 0905 | 1T com 61 camadas | 32B | 384 Roteados + 1 Compartilhado | 8 |
| Qwen3 Coder | 480B com 62 camadas | 35B | 160 | 8 |
| Llama 4 Scout | 109B | 17B | 16 | Não Especificado |
Cada modelo destaca prioridades diferentes por meio de seu design arquitetural.
- O DeepSeek V3.1 e o Kimi K2 0905 contam com pools de especialistas excepcionalmente grandes com múltiplos especialistas ativos por token, uma configuração que maximiza a especialização e entrega um desempenho forte em tarefas de raciocínio complexo e de múltiplas etapas.
- O GPT-OSS 120B, por outro lado, adota uma abordagem mais equilibrada, combinando um pool de especialistas de porte médio com ativação moderada, tornando-o adequado para aplicações empresariais onde estabilidade e escala devem coexistir.
- O GPT-OSS 20B adota uma configuração mais leve com menos especialistas, otimizada para cenários onde latência e eficiência de custo são fundamentais, como chatbots em tempo real ou implantações com recursos limitados.
- O Qwen3 Coder enfatiza tarefas orientadas a código com uma configuração MoE equilibrada, combinando forte capacidade de raciocínio e ativação eficiente para entregar um desempenho confiável para aplicações de desenvolvedores.
- O Llama 4 Scout demonstra um design MoE compacto com um pequeno pool de especialistas e carga de ativação reduzida, posicionando-se como uma opção prática para aplicações de baixa latência ou de borda.
Essas variações ilustram como as configurações de MoE podem ser ajustadas para alinhar-se com diferentes objetivos de implantação — desde exploração em escala de pesquisa e sistemas agentes avançados até inferência leve e pronta para produção.
O que permanece constante, no entanto, é a demanda por infraestrutura de computação confiável. Executar modelos com bilhões ou mesmo trilhões de parâmetros requer não apenas GPUs poderosas, mas também interconexões de alta largura de banda e pipelines otimizados. Para a maioria das equipes, isso cria um forte incentivo para usar instâncias de GPU em nuvem e serviços de API gerenciados, que removem o ônus de manter clusters locais enquanto ainda fornecem acesso a capacidades de MoE de ponta.
Como Acessar os Principais Modelos MoE?
Implantação Local
| Modelo | VRAM (Aprox.) | Quantização | Hardware Recomendado |
| GPT OSS 120B | 80 GB | MXFP4 | H100 x1 |
| GPT OSS 20B | 16 GB | MXFP4 | RTX 4090 x1 |
| DeepSeek V3.1 | 1,34 TB | 16-bit | H200 8-card cluster |
| GLM 4.5 | 717 GB | 16-bit | H100 x 16 / H200 x 8 |
| Kimi K2 0905 | 2,05 TB | 16-bit | H100/A100 80GB (x32) |
| Qwen3 Coder | 290 GB | Q4_K_M | A6000 x2 |
| Llama 4 Scout 17B | 216 GB | Int4 | H100 x1 |
Embora os principais modelos MoE possam ser implantados localmente com requisitos massivos de GPU, a Novita AI fornece GPUs em nuvem otimizadas, removendo a complexidade de gerenciar infraestrutura de alto custo. Para explorar opções flexíveis e encontrar o plano que se adapta à sua carga de trabalho, visite nossa página de Preços.
Integração com API
Quer uma forma ainda mais simples? Basta escolher as APIs da Novita AI!
A Novita AI oferece APIs para todos os principais modelos MoE, com janelas de contexto longas a preços altamente competitivos!
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login ou cadastre-se na sua conta e clique no botão Biblioteca de Modelos.

Experimente os Principais Modelos Gratuitamente!
Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Inicie Seu Teste Gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API para você. Acessando a página de “Configurações“, você pode copiar a chave de API conforme indicado na imagem.
Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Clique aqui para consultar o tutorial detalhado.
Perguntas Frequentes
O que é um modelo de Mistura de Especialistas (MoE)?
A MoE é uma arquitetura de rede neural onde existem muitos módulos “especialistas”, mas apenas um pequeno subconjunto é ativado para cada entrada. Isso aumenta a capacidade total sem um custo de computação proporcional.
Como os modelos MoE diferem dos modelos densos?
Os modelos densos ativam todos os parâmetros para cada entrada. Os modelos MoE ativam seletivamente apenas alguns especialistas por token, tornando-os mais eficientes em termos de computação em larga escala.
O que são especialistas roteados e especialistas compartilhados?
Os especialistas roteados são escolhidos dinamicamente por um roteador para cada token, enquanto um especialista compartilhado está sempre disponível como fallback para garantir estabilidade e justiça no roteamento.
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma forma fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.



