

混合專家(MoE)已迅速成為當今擴展大型語言模型時最重要的設計選擇之一。不同於為每個標記(token)激活所有參數,MoE會選擇性地將輸入路由到一組小型專家模組,在效率與超大模型容量之間取得平衡。這項架構轉變讓開發者能夠構建擁有數千億參數的模型,同時將推論成本控制在可承受的範圍內。
本文將介紹MoE的基本原理、剖析頂級MoE模型之間的架構差異,並說明如何在實際場景中調用這些模型。
混合專家(MoE)簡介
混合專家(MoE)是一種機器學習方法,它會將AI模型拆分為多個子網絡,也就是所謂的「專家」,每個專家都經過訓練以處理特定類型的輸入數據,協同完成任務。MoE會搭配一組專業模型與門控機制,動態選擇最適合的「專家網絡」來處理每個輸入。
MoE運作原理
1. 門控網絡(路由器)
MoE的核心是門控網絡,它會決定哪些專家應該處理每個輸入標記。路由器會選擇性激活最相關的專家,而非將每個標記發送給所有專家,同時確保效率與專業性。
2. MoE與稠密模型(Dense)的差異
**混合專家(MoE)**的運作方式是,每個標記僅通過路由器選出的一小部分專家。這種方式能讓模型的整體容量大幅提升,同時將實際計算成本控制在合理範圍。不同專家專注於不同的輸入模式,因此無需線性提升計算量,就能在複雜任務上表現得更出色。
相比之下,稠密模型會將每個標記發送給所有專家或層,設計簡單但計算成本高昂。兩者的核心差異在於:MoE透過選擇性激活提升效率,而稠密模型則依賴對每個輸入進行全量激活。
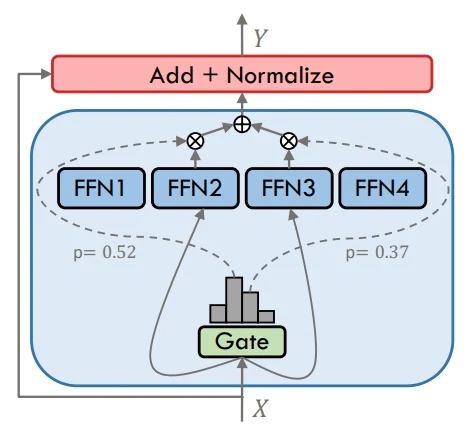
MoE
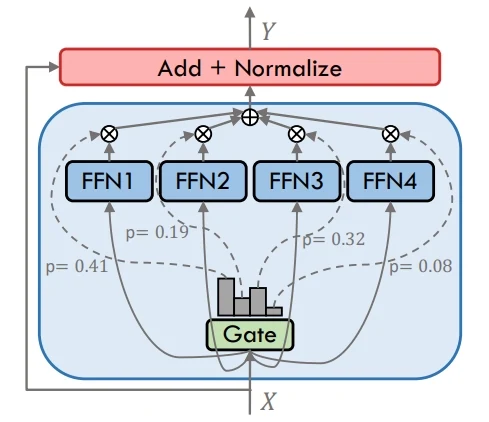
Dense
參考文獻:A Survey on Mixure of Experts in Large Language Model.(連結:https://arxiv.org/abs/2407.06204)
MoE的核心優勢
MoE已成為最先進AI系統的主流設計選擇,這得益於其獨特的優勢:
- 超大容量與可控計算成本:稀疏式MoE能讓模型的參數量大幅擴展,而無需同步提升計算需求。這種設計遵循「條件計算」原則,僅在需要時分配資源,因此能以與稠密模型相同的計算成本,訓練出容量大得多的模型。
- 專家專業化:不同專家會自然專注於不同的模式或任務,提升各類輸入的表現,為大規模LLM賦予更豐富的能力。
- 訓練與推論效率更高:稀疏式MoE每個標記僅激活一小部分專家,降低了稠密模型的沉重開銷,提升了大規模訓練集群的資源利用率。
- 實用的部署場景:稀疏式MoE在擁有大量機器的高吞吐量環境中表現尤為突出,在固定計算預算下能產出更優質的結果。稠密模型則更適合低吞吐量場景或顯存極度受限的環境,因其設計簡單,更利於小規模部署。
- 路由策略靈活:透過top-1、top-2等門控路由策略,稀疏式MoE能平衡計算效率與表達能力,適配不同工作負載與擴展需求。
憑藉這些優勢,MoE被廣泛應用於前沿大型語言模型並不意外。下一節將介紹2025年最具影響力的幾款基於MoE的模型,探討它們如何實現這一架構並從中獲益。
2025年前沿MoE模型
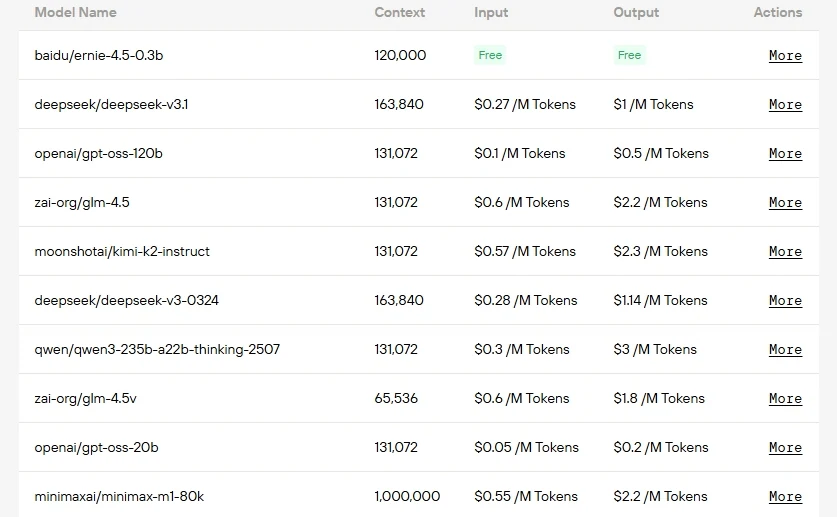
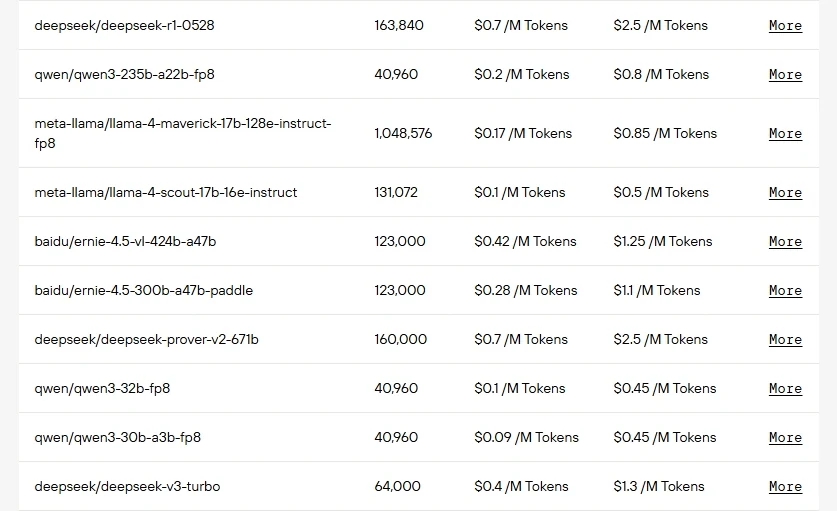
開源MoE模型總覽:架構深度剖析
| 模型 | 總參數量 | 激活參數量 | 專家池大小 | 每標記激活專家數 |
| GPT OSS 120B | 116.8B,共36層 | 5.1B | 128 | 4 |
| GPT OSS 20B | 20.9B,共24層 | 3.6B | 32 | 4 |
| DeepSeek V3.1 | 671B | 37B | 256路由專家 + 1共享專家 | 8 |
| GLM 4.5 | 335B | 32B | 160 | 8 |
| Kimi K2 0905 | 1T,共61層 | 32B | 384路由專家 + 1共享專家 | 8 |
| Qwen3 Coder | 480B,共62層 | 35B | 160 | 8 |
| Llama 4 Scout | 109B | 17B | 16 | 未標註 |
每款模型都透過架構設計體現了不同的優先方向:
- DeepSeek V3.1與Kimi K2 0905採用超大專家池設計,每個標記激活多位專家,最大化專業性,在複雜推理與多步驟任務上表現優異。
- 相比之下,GPT-OSS 120B採取更均衡的策略,結合中等規模的專家池與適中的激活量,適合需要穩定性與規模並存的企業級應用場景。
- GPT-OSS 20B採用更輕量的配置,專家數量更少,針對延遲與成本效率優先的場景優化,例如即時聊天機器人或資源受限的部署環境。
- Qwen3 Coder針對程式碼相關任務優化,採用均衡的MoE配置,結合強大的推理能力與高效的激活機制,為開發者應用提供穩定的表現。
- Llama 4 Scout採用緊湊的MoE設計,專家池較小且激活負載更低,是低延遲或邊緣級應用的實用選擇。
這些差異說明MoE配置可以根據不同的部署目標進行調整,涵蓋從研究級探索、先進智能體系統,到輕量、可投入生產的推論等各類場景。
不過,有一點始終不變:對可靠計算基礎設施的需求。運行擁有數十億甚至數萬億參數的模型,不僅需要強大的GPU,還需要高頻寬互連與優化的流水線。對大多數團隊而言,這讓他們有強烈動機使用雲端GPU實例與托管API服務,這些服務免除了維護本地集群的負擔,同時仍能提供前沿MoE能力的使用權限。
如何調用頂級MoE模型?
本地部署
| 模型 | 顯存(約略值) | 量化方式 | 推薦硬件 |
| GPT OSS 120B | 80 GB | MXFP4 | H100 x1 |
| GPT OSS 20B | 16 GB | MXFP4 | RTX 4090 x1 |
| DeepSeek V3.1 | 1.34 TB | 16-bit | H200 8卡集群 |
| GLM 4.5 | 717 GB | 16-bit | H100 x 16 / H200 x 8 |
| Kimi K2 0905 | 2.05 TB | 16-bit | H100/A100 80GB(32張) |
| Qwen3 Coder | 290 GB | Q4_K_M | A6000 x2 |
| Llama 4 Scout 17B | 216 GB | Int4 | H100 x1 |
雖然頂級MoE模型可以本地部署,但需要大量的GPU資源。Novita AI提供優化過的雲端GPU,免除了管理高成本基礎設施的複雜度。若要探索彈性的選項、找到適合您工作負載的方案,請造訪我們的*定價頁面*。
API整合
想要更簡單的方式嗎?直接選擇Novita AI的API即可!
Novita AI 為所有頂級MoE模型提供API,支援長上下文窗口,價格极具競爭力!
步驟1:登入並進入模型庫
登入或註冊您的帳號,點擊模型庫按鈕即可。

步驟2:選擇您要使用的模型
瀏覽可用的選項,選擇符合您需求的模型。
步驟3:開始免費試用
開始免費試用,探索所選模型的能力。
步驟4:獲取API金鑰
要進行API身份驗證,我們會為您提供新的API金鑰。進入「設定」頁面,即可按照圖中指示複製API金鑰。
步驟5:安裝API SDK
使用對應程式語言的套件管理器安裝API。
點擊此處查看詳細教學指南。
常見問題
什麼是混合專家(MoE)模型?
MoE是一種神經網絡架構,其中存在大量「專家」模組,但每個輸入僅激活其中一小部分。這種設計能在不成比例增加計算成本的前提下,提升總容量。
MoE模型與稠密模型有何差異?
稠密模型會為每個輸入激活所有參數,而MoE模型每個標記僅選擇性激活少量專家,在大規模場景下計算效率更高。
什麼是路由專家與共享專家?
路由專家會由路由器為每個標記動態選擇,而共享專家則作為備用選項始終可用,確保路由的穩定性與公平性。
Novita AI 是一個AI雲端平台,為開發者提供簡單的API來部署AI模型,同時也提供平價且可靠的GPU雲端服務,用於AI模型的構建與擴展。



