

Mixture of Experts (MoE) has rapidly emerged as one of the most important design choices in scaling today’s large language models. Instead of activating every parameter for each token, MoE selectively routes inputs through a small set of experts, balancing efficiency with massive model capacity. This architectural shift allows developers to build models with hundreds of billions of parameters while keeping inference costs manageable.
In this article, we introduce the basics of MoE, highlight the architectural differences among top MoE models, and show you how to access them in practice.
Brief Introduction of Mixture-of-Experts (MoE)
Mixture of Experts (MoE) is a machine learning method that breaks down an AI model into multiple sub-networks, namely “experts,” each trained to handle a particular part of the input data, which then work together to accomplish the task. MoE uses a set of specialized models along with a gating mechanism to dynamically choose the most suitable “expert networks” to process each input.
How MoE Works
1. Gating Network (Router)
At the heart of MoE lies the gating network, which decides which experts should process each input token. Instead of sending every token to all experts, the router selectively activates the most relevant ones, ensuring both efficiency and specialization.
2. MoE vs Dense
MoE (Mixture of Experts) works by routing each token through only a small subset of experts chosen by the gate. This approach allows the model to expand its overall capacity significantly while keeping the actual computation affordable. Different experts specialize in different input patterns, enabling stronger performance on complex tasks without scaling compute linearly.
In contrast, Dense models send every token through all experts or layers, which makes the design straightforward but computationally expensive. The key difference is that MoE leverages selective activation for efficiency, whereas Dense models rely on full activation for every input.
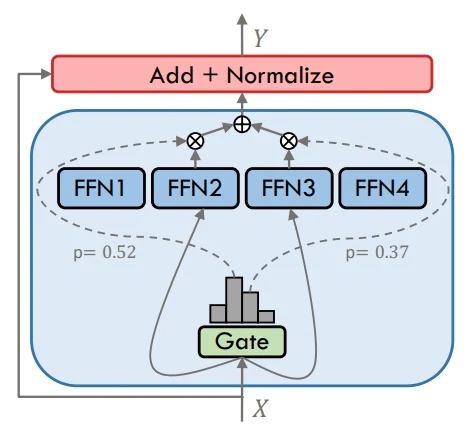
MoE
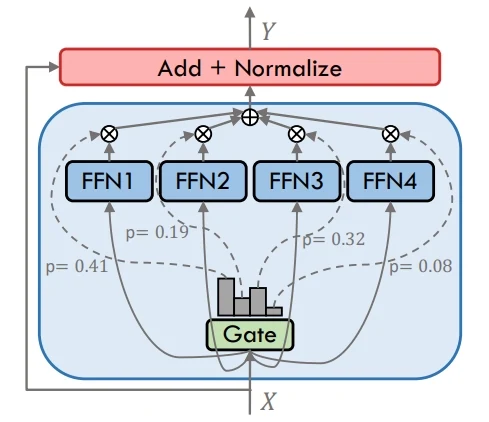
Dense
Reference: A Survey on Mixure of Experts in Large Language Model. (Available: https://arxiv.org/abs/2407.06204)
Key Advantages of MoE
MoE has become the dominant design choice in state-of-the-art AI systems due to its unique advantages:
- Massive Capacity with Controlled Compute: Sparse MoE allows models to dramatically scale up parameters without a matching rise in computational demand. This design follows the principle of conditional computation, where resources are allocated only when needed, making it possible to train models with far greater capacity than dense counterparts at the same compute cost.
- Expert Specialization: Different experts naturally specialize in distinct patterns or tasks, boosting performance across a wide range of inputs and enabling richer capabilities in large-scale LLMs.
- Efficiency in Training and Inference: Sparse MoE activates only a small subset of experts per token, reducing the heavy overhead of dense models and improving resource utilization in large training clusters.
- Practical Deployment Scenarios: Sparse MoEs are particularly effective in high-throughput environments with access to many machines, where they deliver more optimal results under a fixed compute budget. Dense models may still suit low-throughput settings or very limited VRAM, since their simplicity makes them more practical for small-scale deployments.
- Flexibility in Routing: With routing strategies like top-1 or top-2 gating, Sparse MoE achieves a balance between computational efficiency and expressive power, adapting to different workloads and scaling requirements.
With these advantages, it is no surprise that MoE has been widely adopted in cutting-edge large language models. In the next section, we will look at some of the most influential MoE-based models in 2025, exploring how they implement and benefit from this architecture.
Cutting-edge MoE Models in 2025
Overview of Open-Source MoE Models: Architecture Deep Dive
| Model | Total Params | Activated Params | Expert Pool Size | Active Experts per Token |
| GPT OSS 120B | 116.8B with 36 Layers | 5.1B | 128 | 4 |
| GPT OSS 20B | 20.9B with 24 Layers | 3.6B | 32 | 4 |
| DeepSeek V3.1 | 671B | 37B | 256 Routed + 1 Shared | 8 |
| GLM 4.5 | 335B | 32B | 160 | 8 |
| Kimi K2 0905 | 1T with 61 Layers | 32B | 384 Routed + 1 Shared | 8 |
| Qwen3 Coder | 480B with 62 Layers | 35B | 160 | 8 |
| Llama 4 Scout | 109B | 17B | 16 | Not Specified |
Each model highlights different priorities through its architectural design.
- DeepSeek V3.1 and Kimi K2 0905 rely on exceptionally large expert pools with multiple active experts per token, a setup that maximizes specialization and delivers strong performance on complex reasoning and multi-step tasks.
- GPT-OSS 120B, on the other hand, takes a more balanced approach, combining a mid-sized expert pool with moderate activation, making it suitable for enterprise applications where stability and scale must coexist.
- GPT-OSS 20B adopts a lighter configuration with fewer experts, optimized for scenarios where latency and cost efficiency are paramount, such as real-time chatbots or resource-constrained deployments.
- Qwen3 Coder emphasizes code-oriented tasks with a balanced MoE setup, combining strong reasoning ability and efficient activation to deliver reliable performance for developer applications.
- Llama 4 Scout demonstrates a compact MoE design with a small expert pool and reduced activation load, positioning it as a practical option for low-latency or edge-level applications.
These variations illustrate how MoE configurations can be tuned to align with different deployment goals—from research-scale exploration and advanced agentic systems to lightweight, production-ready inference.
What remains constant, however, is the demand for reliable compute infrastructure. Running models with billions or even trillions of parameters requires not only powerful GPUs but also high-bandwidth interconnects and optimized pipelines. For most teams, this creates a strong incentive to leverage cloud GPU instances and managed API services, which remove the burden of maintaining local clusters while still providing access to frontier MoE capabilities.
How to Access Top MoE Models ?
Local Deployment
| Model | VRAM (Approx.) | Quantization | Recommended Hardware |
| GPT OSS 120B | 80 GB | MXFP4 | H100 x1 |
| GPT OSS 20B | 16 GB | MXFP4 | RTX 4090 x1 |
| DeepSeek V3.1 | 1.34 TB | 16-bit | H200 8-card cluster |
| GLM 4.5 | 717 GB | 16-bit | H100 x 16 / H200 x 8 |
| Kimi K2 0905 | 2.05 TB | 16-bit | H100/A100 80GB (x32) |
| Qwen3 Coder | 290 GB | Q4_K_M | A6000 x2 |
| Llama 4 Scout 17B | 216 GB | Int4 | H100 x1 |
While top MoE models can be deployed locally with massive GPU requirements, Novita AI provides optimized cloud GPUs, removing the complexity of managing high-cost infrastructure. To explore flexible options and find the plan that fits your workload, visit our Pricing page.
API Integration
Want an even simpler way? Just choose Novita AI’s APIs !
Novita AI offers APIs for all top MoE models , featuring long context windows at highly competitive prices!
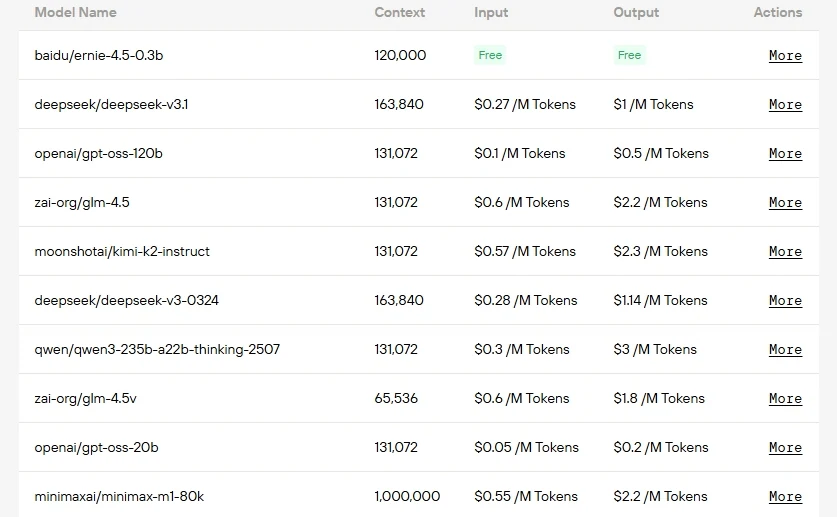
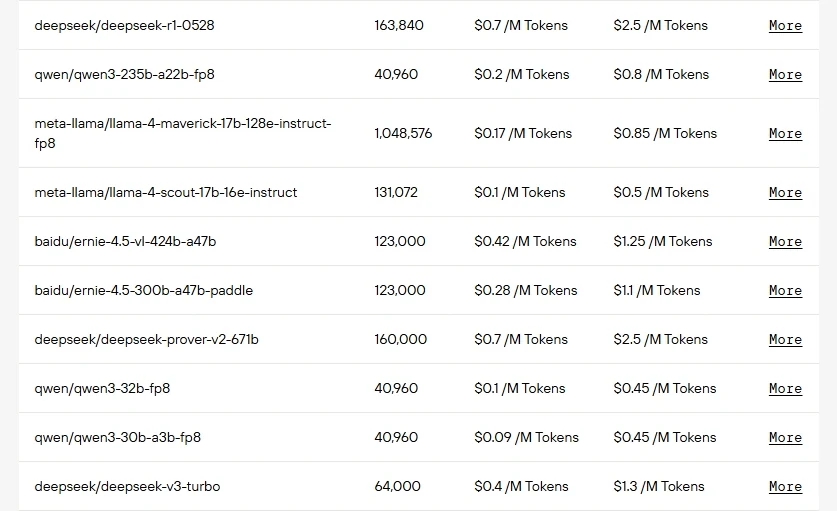
Step 1: Log In and Access the Model Library
Log in or sign up to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.
Step 5: Install the API
Install API using the package manager specific to your programming language.
Click here to check detailed tutorial.
Frequently Asked Question
What is a Mixture-of-Experts (MoE) model?
MoE is a neural network architecture where many “expert” modules exist, but only a small subset is activated for each input. This increases total capacity without proportional compute cost.
How do MoE models differ from dense models?
Dense models activate all parameters for every input. MoE models selectively activate only a few experts per token, making them more compute-efficient at large scales.
What are routed experts and shared experts?
Routed experts are chosen dynamically by a router for each token, while a shared expert is always available as a fallback to ensure stability and fairness in routing.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing an affordable and reliable GPU cloud for building and scaling.



