

ظهر مزيج الخبراء (MoE) بسرعة كأحد أهم الخيارات التصميمية في توسيع نطاق نماذج اللغات الكبيرة اليوم. بدلاً من تفعيل كل معامل لكل رمز، يقوم MoE بتوجيه المدخلات بشكل انتقائي عبر مجموعة صغيرة من الخبراء، موازناً بين الكفاءة والسعة الهائلة للنموذج. يسمح هذا التحول المعماري للمطورين ببناء نماذج تحتوي على مئات المليارات من المعاملات مع الحفاظ على تكاليف الاستدلال قابلة للإدارة.
في هذا المقال، نقدم أساسيات MoE، ونسلط الضوء على الاختلافات المعمارية بين أفضل نماذج MoE، ونوضح لك كيفية الوصول إليها عملياً.
مقدمة موجزة عن مزيج الخبراء (MoE)
مزيج الخبراء (MoE) هو طريقة تعلم آلي تقوم بتقسيم نموذج ذكاء اصطناعي إلى شبكات فرعية متعددة، تسمى “الخبراء”، كل منها مدرب للتعامل مع جزء معين من بيانات الإدخال، ثم يعملون معاً لإنجاز المهمة. يستخدم MoE مجموعة من النماذج المتخصصة إلى جانب آلية البوابة لاختيار “شبكات الخبراء” الأكثر ملاءمة بشكل ديناميكي لمعالجة كل إدخال.
كيف يعمل MoE
1. شبكة البوابة (الموجه)
تقع شبكة البوابة في قلب MoE، وهي التي تقرر أي الخبراء يجب أن يعالجوا كل رمز إدخال. بدلاً من إرسال كل رمز إلى جميع الخبراء، يقوم الموجه بتفعيل الأكثر صلة بشكل انتقائي، مما يضمن الكفاءة والتخصص معاً.
2. MoE مقابل النماذج الكثيفة (Dense)
يعمل MoE (مزيج الخبراء) عن طريق توجيه كل رمز عبر مجموعة صغيرة فقط من الخبراء الذين يختارهم البوابة. يسمح هذا النهج للنموذج بتوسيع سعته الإجمالية بشكل كبير مع الحفاظ على الحساب الفعلي ميسور التكلفة. يتخصص خبراء مختلفون في أنماط إدخال مختلفة، مما يتيح أداءً أقوى على المهام المعقدة دون زيادة الحساب بشكل خطي.
على النقيض، تقوم النماذج الكثيفة (Dense) بإرسال كل رمز عبر جميع الخبراء أو الطبقات، مما يجعل التصميم بسيطاً ولكنه مكلف حسابياً. الفرق الرئيسي هو أن MoE يستخدم التفعيل الانتقائي من أجل الكفاءة، بينما تعتمد النماذج الكثيفة على التفعيل الكامل لكل إدخال.
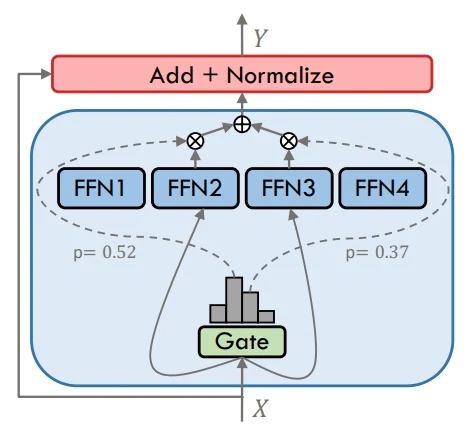
MoE
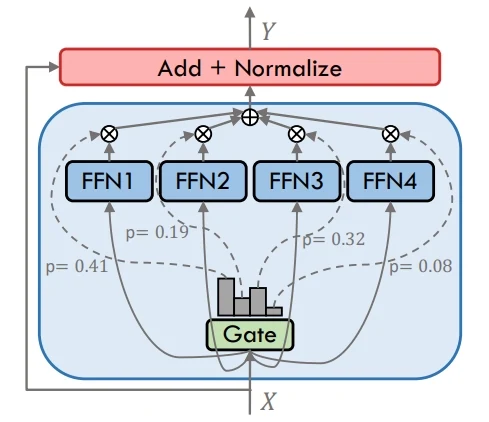
كثيف
المرجع: مسح حول مزيج الخبراء في نموذج اللغة الكبيرة. (متاح على: https://arxiv.org/abs/2407.06204)
المزايا الرئيسية لـ MoE
أصبح MoE الخيار التصميمي السائد في أنظمة الذكاء الاصطناعي المتطورة بفضل مزاياها الفريدة:
- سعة هائلة مع تحكم في الحساب: يسمح MoE المتناثر للنماذج بتوسيع نطاق المعاملات بشكل كبير دون زيادة مطابقة في الطلب الحسابي. يتبع هذا التصميم مبدأ الحساب الشرطي، حيث يتم تخصيص الموارد فقط عند الحاجة، مما يجعل من الممكن تدريب نماذج ذات سعة أكبر بكثير من النماذج الكثيفة المماثلة بنفس تكلفة الحساب.
- تخصص الخبراء: يتخصص الخبراء المختلفون بشكل طبيعي في أنماط أو مهام مميزة، مما يعزز الأداء عبر مجموعة واسعة من المدخلات ويمكن قدرات أكثر ثراءً في نماذج اللغات الكبيرة على نطاق واسع.
- الكفاءة في التدريب والاستدلال: يقوم MoE المتناثر بتفعيل مجموعة صغيرة فقط من الخبراء لكل رمز، مما يقلل من التحميل الثقيل للنماذج الكثيفة ويحسن استخدام الموارد في مجموعات التدريب الكبيرة.
- سيناريوهات النشر العملية: تكون نماذج MoE المتناثرة فعالة بشكل خاص في بيئات الإنتاجية العالية التي لديها إمكانية الوصول إلى العديد من الأجهزة، حيث تقدم نتائج أكثر مثالية تحت ميزانية حسابية ثابتة. قد لا تزال النماذج الكثيفة مناسبة للإعدادات منخفضة الإنتاجية أو ذاكرة الوصول العشوائي للفيديو (VRAM) المحدودة جداً، لأن بساطتها تجعلها أكثر عملية للنشر على نطاق صغير.
- المرونة في التوجيه: مع استراتيجيات التوجيه مثل البوابة من النوع top-1 أو top-2، يحقق MoE المتناثر توازناً بين الكفاءة الحسابية والقوة التعبيرية، متكيفاً مع أحمال العمل المختلفة ومتطلبات التوسع.
مع هذه المزايا، لا عجب في أن MoE قد تم اعتماده على نطاق واسع في نماذج اللغات الكبيرة المتطورة. في القسم التالي، سنلقي نظرة على بعض أكثر نماذج MoE تأثيراً لعام 2025، مستكشفين كيف تقوم بتطبيق هذا التصميم وتستفيد منه.
نماذج MoE المتطورة لعام 2025
نظرة عامة على نماذج MoE مفتوحة المصدر: غوص عميق في التصميم المعماري
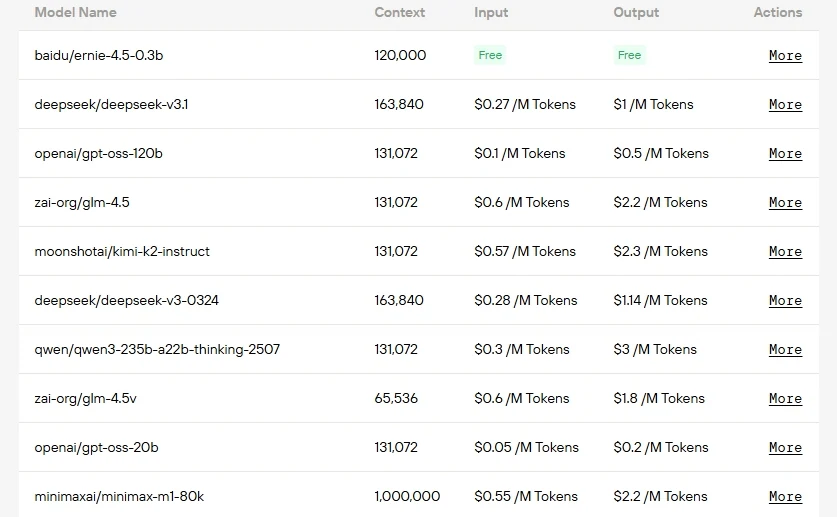
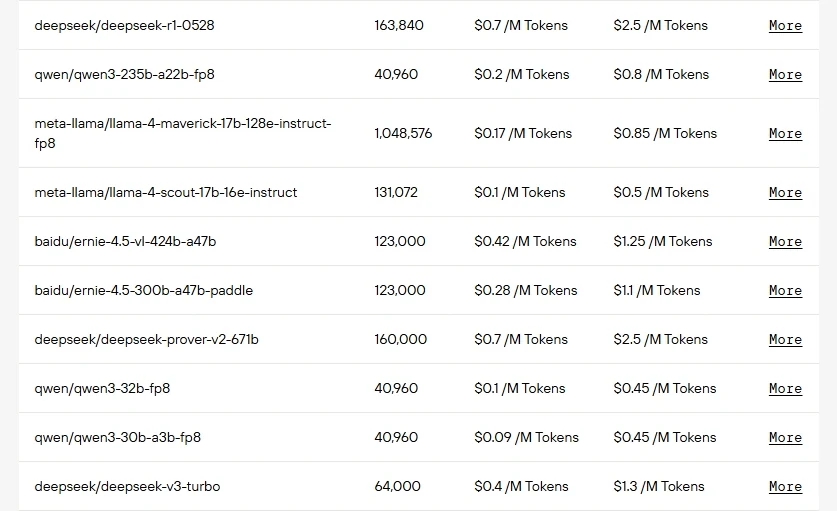
| النموذج | إجمالي المعاملات | المعاملات المفعلة | حجم مجموعة الخبراء | الخبراء النشطين لكل رمز |
| GPT OSS 120B | 116.8 مليار مع 36 طبقة | 5.1 مليار | 128 | 4 |
| GPT OSS 20B | 20.9 مليار مع 24 طبقة | 3.6 مليار | 32 | 4 |
| DeepSeek V3.1 | 671 مليار | 37 مليار | 256 موجه + 1 مشترك | 8 |
| GLM 4.5 | 335 مليار | 32 مليار | 160 | 8 |
| Kimi K2 0905 | 1 تريليون مع 61 طبقة | 32 مليار | 384 موجه + 1 مشترك | 8 |
| Qwen3 Coder | 480 مليار مع 62 طبقة | 35 مليار | 160 | 8 |
| Llama 4 Scout | 109 مليار | 17 مليار | 16 | غير محدد |
يبرز كل نموذج أولويات مختلفة من خلال تصميمه المعماري.
- يعتمد كل من DeepSeek V3.1 و Kimi K2 0905 على مجموعات خبراء استثنائية الحجم مع العديد من الخبراء النشطين لكل رمز، وهو إعداد يعظم التخصص ويقدم أداءً قوياً على مهام الاستدلال المعقدة والمتعددة الخطوات.
- يأخذ GPT-OSS 120B، من ناحية أخرى، نهجاً أكثر توازناً، حيث يجمع بين مجموعة خبراء متوسطة الحجم وتفعيل معتدل، مما يجعله مناسباً لتطبيقات المؤسسات حيث يجب أن تتعايش الاستقرار والتحجيم.
- يتبنى GPT-OSS 20B تكويناً أخف مع عدد أقل من الخبراء، محسناً للسيناريوهات التي تكون فيها زمن الوصول (الكمون) والكفاءة من حيث التكلفة هي الأهم، مثل روبوتات الدردشة في الوقت الفعلي أو عمليات النشر ذات الموارد المحدودة.
- يركز Qwen3 Coder على المهام المتعلقة بالبرمجة مع تكوين MoE متوازن، حيث يجمع بين قدرة استدلال قوية وتفعيل فعال لتقديم أداء موثوق لتطبيقات المطورين.
- يظهر Llama 4 Scout تصميم MoE مدمج مع مجموعة خبراء صغيرة وحمل تفعيل مخفض، مما يجعله خياراً عملياً للتطبيقات منخفضة الكمون أو على مستوى الحافة.
تظهر هذه الاختلافات كيف يمكن ضبط تكوينات MoE لتتوافق مع أهداف نشر مختلفة—من الاستكشاف على نطاق البحث وأنظمة الوكلاء المتقدمة إلى الاستدلال الخفيف الجاهز للإنتاج.
ما يبقى ثابتاً، مع ذلك، هو الطلب على بنية تحتية حسابية موثوقة. يتطلب تشغيل النماذج التي تحتوي على مليارات أو حتى تريليونات من المعاملات ليس فقط وحدات معالجة رسومية (GPUs) قوية ولكن أيضاً روابط عالية النطاق ومسارات محسنة. لمعظم الفرق، يخلق هذا حافزاً قوياً للاستفادة من مثيلات GPU السحابية وخدمات API المُدارة، التي تزيل عبء صيانة المجموعات المحلية مع توفير إمكانية الوصول إلى قدرات MoE المتطورة.
كيفية الوصول إلى أفضل نماذج MoE؟
النشر المحلي
| النموذج | ذاكرة الوصول العشوائي للفيديو (VRAM) (تقريبي) | التكميم | الأجهزة الموصى بها |
| GPT OSS 120B | 80 جيجابايت | MXFP4 | H100 x1 |
| GPT OSS 20B | 16 جيجابايت | MXFP4 | RTX 4090 x1 |
| DeepSeek V3.1 | 1.34 تيرابايت | 16 بت | مجموعة من 8 بطاقات H200 |
| GLM 4.5 | 717 جيجابايت | 16 بت | H100 x 16 / H200 x 8 |
| Kimi K2 0905 | 2.05 تيرابايت | 16 بت | H100/A100 80 جيجابايت (x32) |
| Qwen3 Coder | 290 جيجابايت | Q4_K_M | A6000 x2 |
| Llama 4 Scout 17B | 216 جيجابايت | Int4 | H100 x1 |
على الرغم من إمكانية نشر أفضل نماذج MoE محلياً مع متطلبات ضخمة لوحدات معالجة الرسوميات، توفر Novita AI وحدات GPU سحابية محسنة، مما يزيل تعقيد إدارة البنية التحتية عالية التكلفة. لاستكشاف الخيارات المرنة والعثور على الخطة التي تناسب عبء العمل الخاص بك، قم بزيارة صفحة التسعير الخاصة بنا.
تكامل API
تريد طريقة أبسط حتى؟ فقط اختر واجهات برمجة التطبيقات (APIs) الخاصة بـ Novita AI!
توفر Novita AI واجهات برمجة تطبيقات لجميع أفضل نماذج MoE، مع نوافذ سياق طويلة بأسعار تنافسية للغاية!*
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
قم بتسجيل الدخول أو إنشاء حساب جديد ثم انقر على زر مكتبة النماذج.

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنقدم لك مفتاح API جديد. عند الدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.
الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة الخاصة بك.
انقر هنا للاطلاع على البرنامج التعليمي المفصل.
الأسئلة الشائعة
ما هو نموذج مزيج الخبراء (MoE)؟
MoE هو تصميم معماري للشبكات العصبية حيث توجد العديد من وحدات “الخبراء”، ولكن يتم تفعيل مجموعة صغيرة فقط لكل إدخال. هذا يزيد السعة الإجمالية دون تكلفة حسابية متناسبة.
كيف تختلف نماذج MoE عن النماذج الكثيفة (Dense)؟
تقوم النماذج الكثيفة بتفعيل جميع المعاملات لكل إدخال. تقوم نماذج MoE بتفعيل عدد قليل فقط من الخبراء لكل رمز بشكل انتقائي، مما يجعلها أكثر كفاءة حسابياً على نطاقات كبيرة.
ما هي الخبراء الموجهون والخبراء المشتركون؟
يتم اختيار الخبراء الموجهين بشكل ديناميكي بواسطة موجه لكل رمز، بينما يكون الخبير المشترك متاحاً دائماً كخيار بديل لضمان الاستقرار والعدالة في التوجيه.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط الخاص بنا، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.



