

Mixture of Experts (MoE) быстро стал одним из наиболее важных архитектурных решений для масштабирования современных больших языковых моделей. Вместо активации всех параметров для каждого токена MoE выборочно направляет входные данные через небольшой набор экспертов, балансируя эффективность и огромную емкость модели. Этот архитектурный сдвиг позволяет разработчикам создавать модели с сотнями миллиардов параметров, сохраняя при этом управляемые затраты на вывод.
В этой статье мы рассмотрим основы работы MoE, выделим архитектурные различия между ведущими моделями MoE и покажем, как получить к ним доступ на практике.
Краткое введение в Mixture-of-Experts (MoE)
Mixture of Experts (MoE) — это метод машинного обучения, который разбивает ИИ-модель на множество подсетей, называемых «экспертами», каждая из которых обучена обрабатывать определенную часть входных данных, после чего они совместно решают поставленную задачу. MoE использует набор специализированных моделей вместе с механизмом гейтинга для динамического выбора наиболее подходящих «экспертных сетей» для обработки каждого входного сигнала.
Принцип работы MoE
1. Сеть гейтинга (роутер)
В основе MoE лежит сеть гейтинга, которая определяет, какие эксперты должны обрабатывать каждый входной токен. Вместо отправки каждого токена всем экспертам роутер выборочно активирует наиболее релевантные из них, обеспечивая как эффективность, так и специализацию.
2. MoE против плотных (Dense) моделей
MoE (смесь экспертов) работает путем направления каждого токена только через небольшое подмножество экспертов, выбранных гейтинг-механизмом. Этот подход позволяет модели значительно расширить общую емкость, сохраняя при этом приемлемую стоимость вычислений. Разные эксперты специализируются на разных шаблонах входных данных, что обеспечивает более высокую производительность на сложных задачах без линейного масштабирования вычислительных ресурсов.
В отличие от этого, плотные (Dense) модели отправляют каждый токен через всех экспертов или слои, что делает их конструкцию простой, но вычислительно затратной. Ключевое отличие заключается в том, что MoE использует выборочную активацию для повышения эффективности, тогда как плотные модели полагаются на полную активацию для каждого входного сигнала.
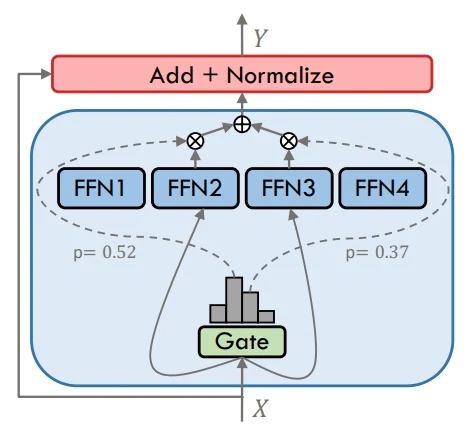
MoE
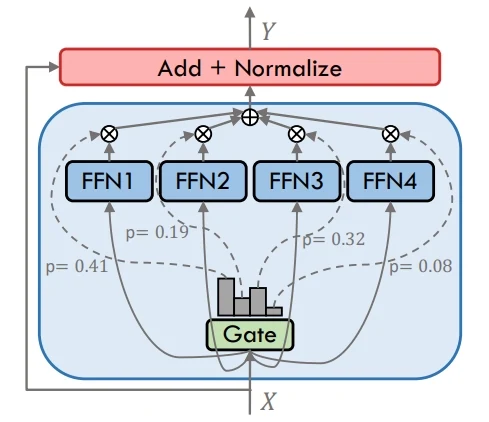
Плотная MoE
Источник: A Survey on Mixure of Experts in Large Language Model. (Доступно: https://arxiv.org/abs/2407.06204)
Ключевые преимущества MoE
MoE стал доминирующим архитектурным решением в передовых ИИ-системах благодаря своим уникальным преимуществам:
- Огромная емкость при контролируемых вычислительных затратах: Разреженная MoE позволяет моделям значительно увеличивать количество параметров без соответствующего роста вычислительных требований. Эта архитектура следует принципу условных вычислений, при котором ресурсы выделяются только при необходимости, что позволяет обучать модели с гораздо большей емкостью, чем плотные аналоги, при одинаковых вычислительных затратах.
- Специализация экспертов: Разные эксперты естественным образом специализируются на отдельных шаблонах или задачах, что повышает производительность на широком спектре входных данных и обеспечивает более широкие возможности крупномасштабных LLM.
- Эффективность при обучении и выводе: Разреженная MoE активирует только небольшое подмножество экспертов на каждый токен, снижая высокие накладные расходы плотных моделей и улучшая утилизацию ресурсов в крупных обучающих кластерах.
- Практические сценарии развертывания: Разреженные MoE особенно эффективны в средах с высокой пропускной способностью и доступом к множеству машин, где они дают более оптимальные результаты при фиксированном вычислительном бюджете. Плотные модели все еще могут подходить для сред с низкой пропускной способностью или очень ограниченным объемом VRAM, поскольку их простота делает их более практичными для развертывания в малом масштабе.
- Гибкость маршрутизации: Благодаря стратегиям маршрутизации, таким как гейтинг top-1 или top-2, разреженная MoE достигает баланса между вычислительной эффективностью и выразительной мощью, адаптируясь к различным рабочим нагрузкам и требованиям к масштабированию.
Учитывая эти преимущества, не удивительно, что MoE широко используется в передовых больших языковых моделях. В следующем разделе мы рассмотрим некоторые из наиболее влиятельных моделей на основе MoE 2025 года, изучим, как они реализуют эту архитектуру и какие преимущества получают от нее.
Передовые модели MoE 2025 года
Обзор открытых моделей MoE: детальный разбор архитектуры
| Модель | Общее количество параметров | Активируемые параметры | Размер пула экспертов | Активных экспертов на токен |
| GPT OSS 120B | 116,8 млрд, 36 слоев | 5,1 млрд | 128 | 4 |
| GPT OSS 20B | 20,9 млрд, 24 слоя | 3,6 млрд | 32 | 4 |
| DeepSeek V3.1 | 671 млрд | 37 млрд | 256 маршрутизируемых + 1 общий | 8 |
| GLM 4.5 | 335 млрд | 32 млрд | 160 | 8 |
| Kimi K2 0905 | 1 трлн, 61 слой | 32 млрд | 384 маршрутизируемых + 1 общий | 8 |
| Qwen3 Coder | 480 млрд, 62 слоя | 35 млрд | 160 | 8 |
| Llama 4 Scout | 109 млрд | 17 млрд | 16 | Не указано |
Каждая модель подчеркивает разные приоритеты в своей архитектурной конструкции.
- DeepSeek V3.1 и Kimi K2 0905 используют исключительно большие пулы экспертов с несколькими активными экспертами на токен — такая конфигурация максимизирует специализацию и обеспечивает высокую производительность на сложных задачах на рассуждение и многошаговых задачах.
- GPT-OSS 120B, в свою очередь, использует более сбалансированный подход, сочетая пул экспертов среднего размера с умеренной активацией, что делает его подходящим для корпоративных приложений, где необходимо сочетать стабильность и масштаб.
- GPT-OSS 20B использует более легкую конфигурацию с меньшим количеством экспертов, оптимизированную для сценариев, где приоритетны задержка и экономическая эффективность, например, для чат-ботов в реальном времени или развертываний с ограниченными ресурсами.
- Qwen3 Coder ориентирован на задачи, связанные с кодом, используя сбалансированную конфигурацию MoE, которая сочетает мощные возможности рассуждения и эффективную активацию для обеспечения стабильной производительности в приложениях для разработчиков.
- Llama 4 Scout демонстрирует компактную архитектуру MoE с небольшим пулом экспертов и сниженной нагрузкой на активацию, что делает его практичным вариантом для приложений с низкой задержкой или для edge-устройств.
Эти вариации показывают, как конфигурации MoE можно настраивать в соответствии с разными целями развертывания — от исследовательских экспериментов и продвинутых агентных систем до легковесного вывода, готового к промышленному использованию.
Однако неизменным остается спрос на надежную вычислительную инфраструктуру. Для запуска моделей с миллиардами или даже триллионами параметров требуются не только мощные GPU, но и высокоскоростные межсоединения и оптимизированные конвейеры. Для большинства команд это создает сильный стимул использовать облачные GPU-инстансы и управляемые API-сервисы, которые снимают нагрузку по поддержке локальных кластеров, но при этом предоставляют доступ к передовым возможностям MoE.
Как получить доступ к ведущим моделям MoE?
Локальное развертывание
| Модель | Объем VRAM (приблизительно) | Квантизация | Рекомендуемое оборудование |
| GPT OSS 120B | 80 ГБ | MXFP4 | 1x H100 |
| GPT OSS 20B | 16 ГБ | MXFP4 | 1x RTX 4090 |
| DeepSeek V3.1 | 1,34 ТБ | 16-бит | Кластер из 8 карт H200 |
| GLM 4.5 | 717 ГБ | 16-бит | 16x H100 / 8x H200 |
| Kimi K2 0905 | 2,05 ТБ | 16-бит | 32x H100/A100 80GB |
| Qwen3 Coder | 290 ГБ | Q4_K_M | 2x A6000 |
| Llama 4 Scout 17B | 216 ГБ | Int4 | 1x H100 |
Хотя ведущие модели MoE можно развернуть локально, для этого требуются мощные GPU, Novita AI предоставляет оптимизированные облачные GPU, устраняя сложность управления дорогостоящей инфраструктурой. Чтобы изучить гибкие варианты и найти тариф, подходящий для вашей рабочей нагрузки, посетите нашу страницу Тарифы.
Интеграция через API
Хотите еще более простой способ? Просто используйте API от Novita AI!
Novita AI предоставляет API для всех ведущих моделей MoE с большим контекстным окном по очень конкурентоспособным ценам!
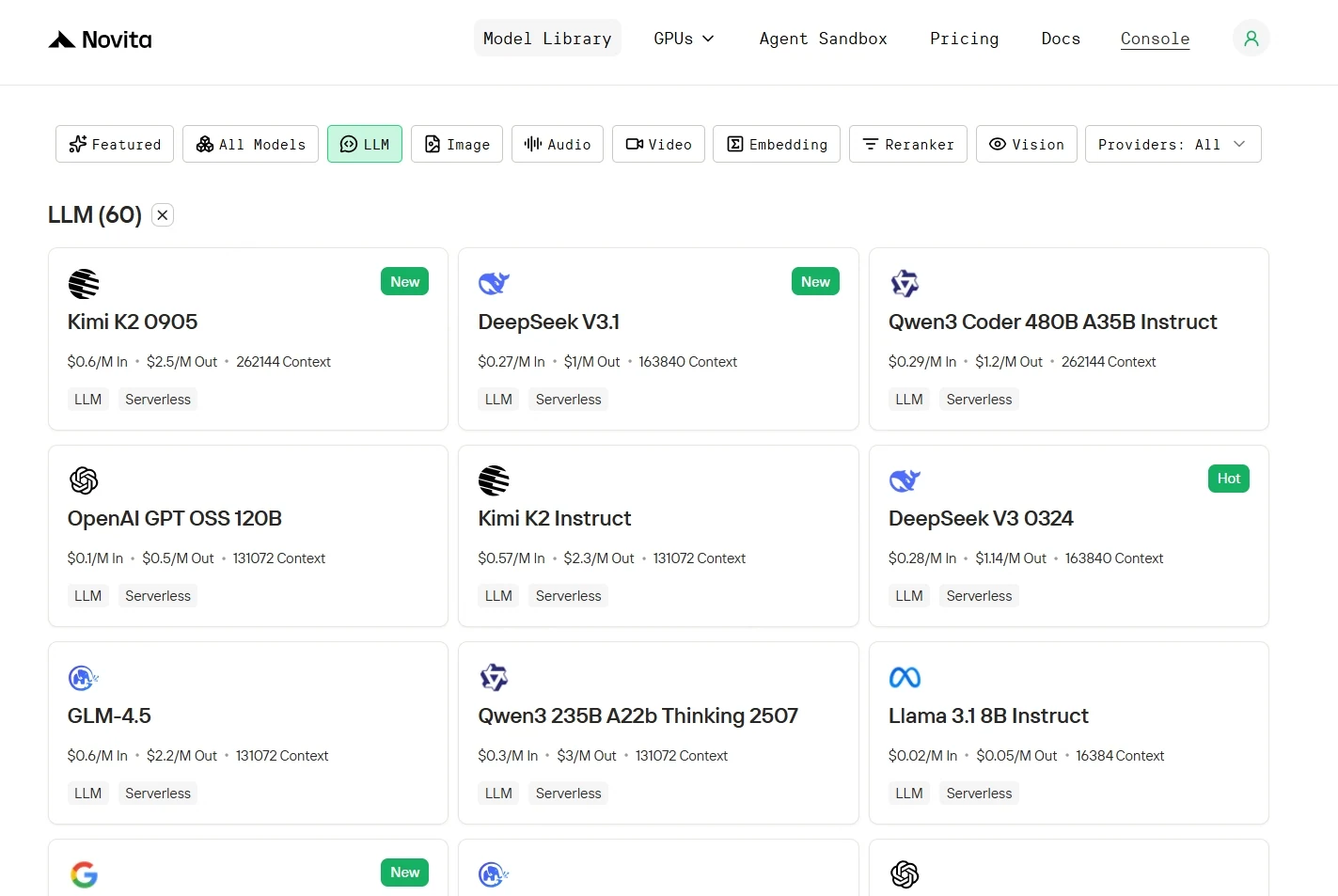
Шаг 1: Войдите в аккаунт и откройте библиотеку моделей
Войдите в существующий аккаунт или зарегистрируйте новый, затем нажмите кнопку Библиотека моделей.

Попробуйте ведущие модели бесплатно!
Шаг 2: Выберите нужную модель
Просмотрите доступные варианты и выберите модель, которая подходит для ваших задач.
Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
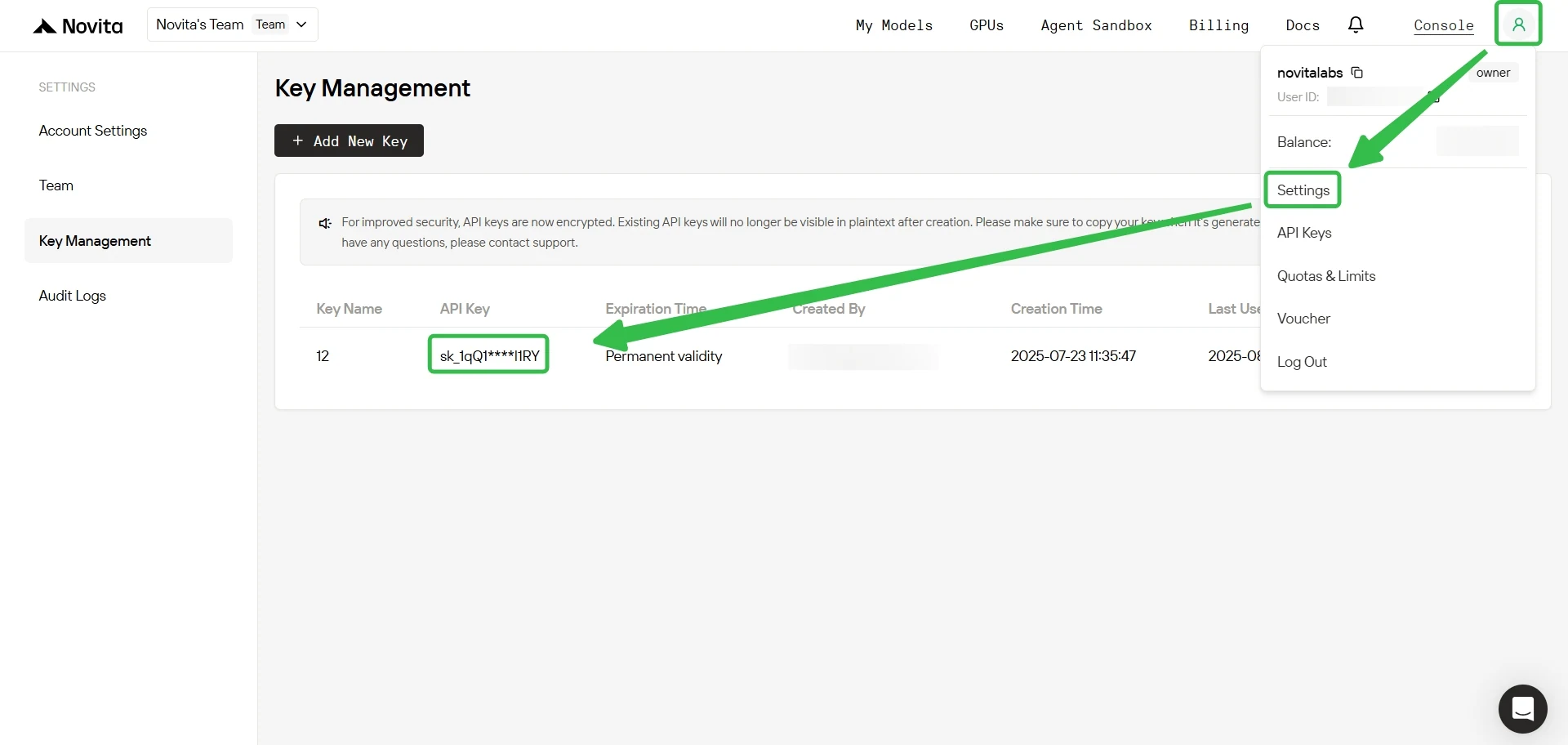
Шаг 4: Получите API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдите на страницу «Настройки», чтобы скопировать API-ключ, как показано на изображении.
Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
Нажмите здесь, чтобы ознакомиться с подробным руководством.
Часто задаваемые вопросы
Что такое модель Mixture-of-Experts (MoE, смесь экспертов)?
MoE — это архитектура нейронной сети, в которой существует множество модулей-«экспертов», но для каждого входного сигнала активируется только их небольшое подмножество. Это увеличивает общую емкость без пропорционального роста вычислительных затрат.
Чем модели MoE отличаются от плотных (Dense) моделей?
Плотные модели активируют все параметры для каждого входного сигнала. Модели MoE выборочно активируют только несколько экспертов на токен, что делает их более вычислительно эффективными при большом масштабе.
Что такое маршрутизируемые и общие эксперты?
Маршрутизируемые эксперты динамически выбираются роутером для каждого токена, тогда как общий эксперт всегда доступен в качестве резервного, чтобы обеспечить стабильность и справедливость маршрутизации.
Novita AI — это облачная ИИ-платформа, которая предоставляет разработчикам простой способ развертывать ИИ-модели с помощью нашего простого API, а также предлагает доступное и надежное облако GPU для разработки и масштабирования.



