

混合专家(MoE)技术已成为当下大语言模型规模化过程中最重要的设计选择之一。与为每个词元激活全部参数不同,MoE会通过路由机制将输入选择性分配给少量专家,在效率和超大模型容量之间取得平衡。这种架构转变让开发者能够构建参数量达千亿级的模型,同时将推理成本控制在合理范围内。
本文将从基础原理入手,梳理主流MoE模型的架构差异,并介绍实际使用这些模型的方法。
混合专家(MoE)技术简介
混合专家(MoE)是一种机器学习方法,它将AI模型拆分为多个子网络(即“专家”),每个专家专门处理输入数据的特定部分,协同完成目标任务。MoE通过一组专用模型配合门控机制,动态选择最合适的“专家网络”来处理每条输入。
MoE工作原理
1. 门控网络(路由器) 门控网络是MoE的核心,它决定每个输入词元应由哪些专家处理。路由器不会将每个词元发送给所有专家,而是选择性激活最相关的专家,同时保障效率和专业度。
2. MoE与稠密模型对比
混合专家(MoE) 通过路由器为每个词元选择少量专家子集进行处理,这种方式可以在实际计算成本可控的前提下,大幅扩展模型整体容量。不同专家擅长处理不同的输入模式,无需线性提升计算量就能在复杂任务上获得更优表现。
相比之下,稠密模型 会将每个词元发送给所有专家或层,设计简单但计算成本极高。二者的核心区别在于:MoE通过选择性激活提升效率,而稠密模型需要对每条输入执行全量激活。
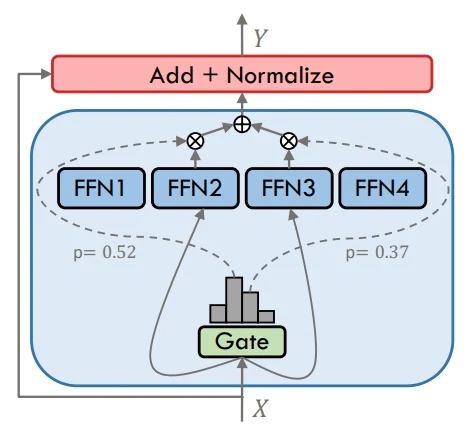
MoE
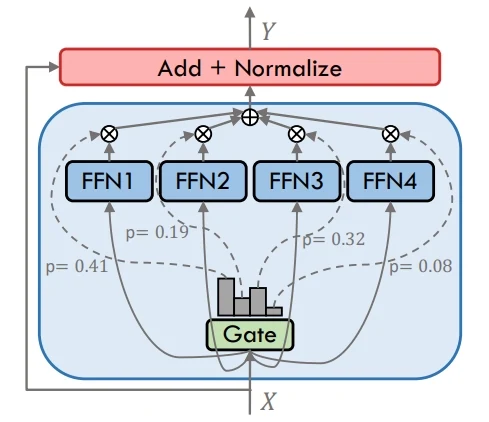
Dense
参考:A Survey on Mixure of Experts in Large Language Model. (Available: https://arxiv.org/abs/2407.06204)
MoE的核心优势
凭借独特优势,MoE已成为前沿AI系统的主流设计选择:
- 可控计算成本下的超大容量:稀疏MoE允许模型大幅提升参数量,而无需同步提升计算需求。该设计遵循条件计算原则,仅在需要时分配资源,使得在相同计算成本下,可以训练出容量远大于稠密模型的版本。
- 专家专业化:不同专家天然擅长处理不同的模式或任务,能提升各类输入下的表现,为大规模大语言模型赋予更丰富的功能。
- 训练与推理效率更高:稀疏MoE每个词元仅激活少量专家,大幅降低了稠密模型的重度开销,提升了大规模训练集群的资源利用率。
- 适配实际部署场景:稀疏MoE在多机组成的高吞吐量环境中表现尤为突出,在固定计算预算下能获得更优的效果。稠密模型仍适合低吞吐量场景或显存极受限的环境,其简单性更适合小规模部署。
- 路由策略灵活:通过top-1、top-2等门控路由策略,稀疏MoE能在计算效率和表达能力之间取得平衡,适配不同的工作负载和扩展需求。
凭借这些优势,MoE被广泛应用于前沿大语言模型并不意外。下一节我们将介绍2025年最具影响力的几款MoE模型,探索它们如何落地该架构并从中获益。
2025年前沿MoE模型
开源MoE模型概览:架构深度解析
| 模型 | 总参数量 | 激活参数量 | 专家池规模 | 每词元激活专家数 |
| GPT OSS 120B | 116.8B with 36 Layers | 5.1B | 128 | 4 |
| GPT OSS 20B | 20.9B with 24 Layers | 3.6B | 32 | 4 |
| DeepSeek V3.1 | 671B | 37B | 256 Routed + 1 Shared | 8 |
| GLM 4.5 | 335B | 32B | 160 | 8 |
| Kimi K2 0905 | 1T with 61 Layers | 32B | 384 Routed + 1 Shared | 8 |
| Qwen3 Coder | 480B with 62 Layers | 35B | 160 | 8 |
| Llama 4 Scout | 109B | 17B | 16 | Not Specified |
各模型通过架构设计体现了不同的侧重点:
- DeepSeek V3.1 和 Kimi K2 0905 采用超大规模的专家池,每个词元激活多个专家,该设计最大化了专业化程度,在复杂推理和多步任务上表现突出。
- 相比之下,GPT-OSS 120B 采用了更均衡的方案,结合中等规模的专家池和适中的激活量,适合对稳定性和规模都有要求的企业级应用场景。
- GPT-OSS 20B 采用更轻量的配置,专家数量更少,针对延迟和成本效率优先的场景优化,适合实时聊天机器人或资源受限的部署环境。
- Qwen3 Coder 针对代码类任务优化,采用均衡的MoE配置,结合强大的推理能力和高效的激活机制,为开发者类应用提供稳定的性能表现。
- Llama 4 Scout 采用紧凑的MoE设计,专家池规模小、激活负载低,是低延迟或边缘端应用的实用选择。
这些差异说明MoE配置可以根据不同的部署目标灵活调整,覆盖从研究级探索、高级智能体系统到轻量级生产推理的全场景需求。
但不变的是对可靠计算基础设施的需求。运行参数量达数十亿甚至万亿级的模型,不仅需要强大的GPU,还需要高带宽互联和优化的流水线。对大多数团队而言,这促使他们优先选择云GPU实例和托管API服务——这类服务无需维护本地集群,同时还能提供前沿的MoE能力。
如何获取顶尖MoE模型?
本地部署
| 模型 | 显存(约) | 量化方式 | 推荐硬件 |
| GPT OSS 120B | 80 GB | MXFP4 | H100 x1 |
| GPT OSS 20B | 16 GB | MXFP4 | RTX 4090 x1 |
| DeepSeek V3.1 | 1.34 TB | 16-bit | H200 8-card cluster |
| GLM 4.5 | 717 GB | 16-bit | H100 x 16 / H200 x 8 |
| Kimi K2 0905 | 2.05 TB | 16-bit | H100/A100 80GB (x32) |
| Qwen3 Coder | 290 GB | Q4_K_M | A6000 x2 |
| Llama 4 Scout 17B | 216 GB | Int4 | H100 x1 |
虽然顶尖MoE模型可以本地部署,但需要大规模的GPU资源,Novita AI提供优化后的云GPU,省去了管理高成本基础设施的复杂度。如需探索灵活的方案、找到适配您工作负载的套餐,请访问我们的*定价页*。
API集成
想要更简单的方案?直接选择Novita AI的API即可!
Novita AI 为所有顶尖MoE模型提供API,支持长上下文窗口,价格极具竞争力!
步骤1:登录并进入模型库 登录或注册您的账号,点击模型库按钮。

步骤2:选择模型 浏览可用选项,选择适配您需求的模型。
步骤3:开启免费试用 开启免费试用,探索所选模型的能力。
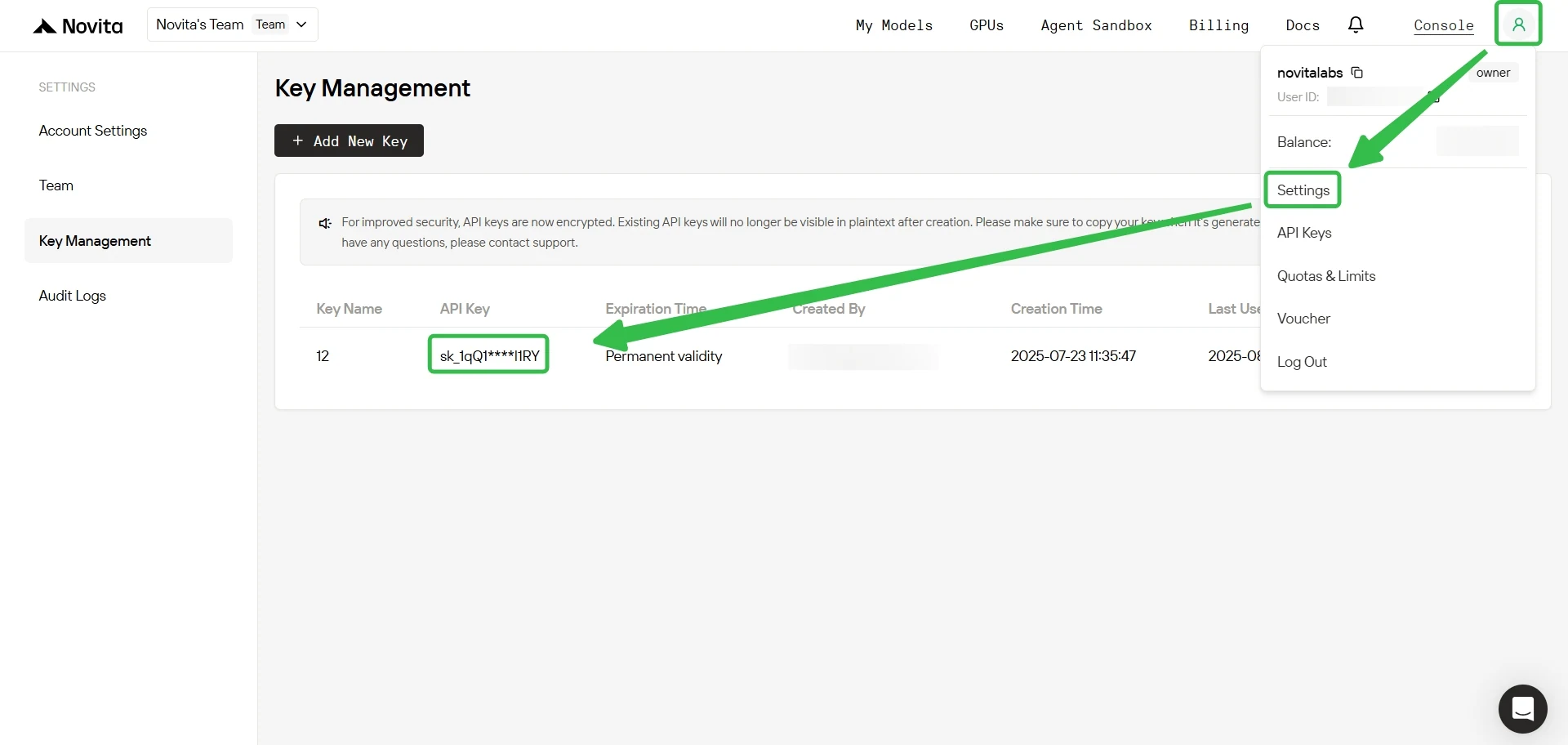
步骤4:获取API密钥 为了完成API身份验证,我们将为您提供新的API密钥。进入“设置”页面,即可按照图示复制API密钥。
步骤5:安装API SDK 使用对应编程语言的包管理器安装API SDK。
点击此处查看详细教程。
常见问题
什么是混合专家(MoE)模型? MoE是一种神经网络架构,包含大量“专家”模块,但每条输入仅会激活其中一小部分。这种设计可以在计算成本不成比例增长的前提下,提升模型总容量。
MoE模型和稠密模型有什么区别? 稠密模型会对每条输入激活全部参数,而MoE模型每个词元仅选择性激活少量专家,在大规模场景下计算效率更高。
什么是路由专家和共享专家? 路由专家由路由器为每个词元动态选择,而共享专家始终作为备用选项存在,用于保障路由的稳定性和公平性。
Novita AI 是一个AI云平台,为开发者提供简单的API来部署AI模型,同时提供高性价比、可靠的GPU云服务,支持AI应用的构建与扩展。



