

Minimax M2 ist das neueste hochmoderne, leichtgewichtige Large Language Model, das für optimale Codierungs- und agentische KI-Workflows entwickelt wurde und Effizienz mit robusten Schlussfolgerungsfähigkeiten kombiniert. Doch eine wesentliche Frage bleibt: Wie viel GPU-Speicher wird für einen effizienten Betrieb benötigt? VRAM bestimmt, ob Sie es lokal, auf Unternehmenshardware oder über die Cloud bereitstellen können. Dieser Artikel untersucht die VRAM-Anforderungen von Minimax M2 und vergleicht verschiedene Bereitstellungswege, von lokalen Einrichtungen bis hin zu API-basierten Lösungen.
Minimax M2: Grundlagen und Highlights
| Funktion | Minimax M2 |
|---|---|
| Parameter | 230B mit 10B aktivierten |
| Architektur | Mixture-of-Experts |
| Kontextfenster | 204K Tokens |
| Open Source | Ja |
| Denkmodus | Think + Non-Think |
Minimax M2 Benchmark
Hauptmerkmale
Außergewöhnliche Intelligenz
MiniMax-M2 zeigt außergewöhnliche allgemeine Intelligenz in Bereichen wie Mathematik, Naturwissenschaften, Schlussfolgerung, Anweisungsbefolgung, Codierung und agentenbasierten Aufgaben. Es belegt derzeit den ersten Platz unter den Open-Source-Modellen weltweit nach Gesamtpunktzahl.
Umfassende Codierungsleistung
Entwickelt für vollständige Entwickler-Workflows, bewältigt MiniMax-M2 mühelos Multi-Datei-Bearbeitungen, iterative Code-Ausführung-Fix-Zyklen und automatisierte Testreparaturen. Seine starken Ergebnisse bei Terminal-Bench und SWE-Bench-ähnlichen Benchmarks bestätigen seine Zuverlässigkeit in echten Codierungsumgebungen – von IDEs bis hin zu CI-Systemen – über mehrere Programmiersprachen hinweg.
Robuste agentische Fähigkeiten
MiniMax-M2 plant und führt effektiv lange, mehrstufige Toolchains, die Shells, Browser, Retrieval-Systeme und Code-Runner umfassen. In BrowseComp-ähnlichen Auswertungen findet es zuverlässig schwer zugängliche Informationen, hält seine Schlussfolgerungen transparent und erholt sich reibungslos von teilweisen Ausführungsfehlern.
Optimierte Architektur
Mit 10 Milliarden aktiven Parametern aus einer 230-Milliarden-Parameter-Architektur bietet MiniMax-M2 geringere Latenz, reduzierte Kosten und hohen Durchsatz sowohl für interaktive Agenten als auch für Masseninferenz – es verkörpert eine neue Generation bereitstellbarer Modelle, die in Codierungs- und agentischer Leistung herausragend bleiben.
Was ist VRAM?
VRAM (Video Random Access Memory) ist der dedizierte Speicher der GPU, der Modellparameter, Gewichte und zwischenliegende Berechnungsdaten speichert. Bei LLMs (Large Language Models) spielt VRAM eine entscheidende Rolle, die bestimmt, ob ein Modell überhaupt geladen werden kann, wie lang sein Kontextfenster sein kann und welche Batch-Größen möglich sind. Im Gegensatz zu normalem System-RAM bietet VRAM eine extrem hohe Bandbreite, um die intensiven Matrixoperationen aufrechtzuerhalten, die für Transformer-Architekturen zentral sind. Einfach ausgedrückt: VRAM ist der wichtigste limitierende Faktor sowohl für Inferenz als auch für Training: Unzureichende Kapazität führt zu Speicherüberläufen, kürzeren Kontexten und einer starken Abhängigkeit von langsamem Offloading.
Minimax M2 VRAM-Anforderungen
| Quantisierung | Nur Gewichte (ca.) | Empfohlene GPU |
| Q8_0 (8-bit) | 243 GB | Nvidia H100 ×4 |
| Q6_K (6-bit) | 188 GB | Nvidia H100 ×3 |
| Q4_0 (4-bit) | 130 GB | Nvidia A100 ×2 |
| Q2_K (2-bit) | 83,3 GB | RTX 6000 Ada ×2 |
| Aspekt | Lokale Bereitstellung | Cloud-GPU | API-Zugriff |
|---|---|---|---|
| Anfangsinvestition | >100.000 $ (NVIDIA-GPU-Cluster plus Hardware-Einrichtung) | Pay-per-Hour-Modell ohne erhebliche Vorabkosten | Pay-as-you-go-Preise ohne Hardware-Investitionen |
| Infrastruktur | Erfordert GPUs, Kühlsysteme und eine stabile Stromversorgung | GPU-Instanzen (H100, A100, RTX 6000 Ada usw.) sind auf Abruf über Novita AI verfügbar | Vollständig verwaltet durch die optimierte Infrastruktur von Novita AI |
| Technisches Fachwissen | Erfordert ML/DevOps-Fachwissen für Einrichtung, Treiber und Umgebungsverwaltung | Nur grundlegende Einrichtung; minimaler Betriebsaufwand im Vergleich zur lokalen Bereitstellung | Nur grundlegende Kenntnisse der API-Integration erforderlich |
| Wartung | Kontinuierliche Überwachung, Treiberaktualisierungen und Hardware-Wartung | Novita AI verwaltet Treiber, Aktualisierungen und Infrastruktur; Benutzer warten ihre Anwendungen | Keine Wartung erforderlich |
| Skalierbarkeit | Durch lokale Hardwarekapazität begrenzt | Elastische Skalierung – GPU-Instanzen können einfach hinzugefügt oder freigegeben werden, wenn sich die Arbeitslasten ändern | Sofort skalierbar mit flexibler Ressourcenzuweisung |
| Zuverlässigkeit | Abhängig von der Stabilität der lokalen Hardware | Unterstützt durch SLA-Garantien und robuste Cloud-Infrastruktur | Unternehmensgrade SLA und optimierte Laufzeit |
| Leistung | Variiert je nach GPU-Modell und Konfiguration | Unternehmensgrade Leistung mit flexibler Instanzauswahl | Vom Anbieter für konsistente Hochleistung optimiert |
| Datenschutz | Vollständige lokale Kontrolle über Daten | Abhängig von den Richtlinien des Anbieters | Abhängig von den Richtlinien des Anbieters |
Für Benutzer, die direkte Kontrolle und GPU-Flexibilität bevorzugen, bietet Novita AI einen Cloud-GPU-Instanzdienst (einschließlich H100, A100, TX 6000 Ada usw.) mit verschiedenen Abrechnungsmodellen an, der eine Hochleistungsbereitstellung ohne die Belastung durch lokale Hardware-Einrichtung ermöglicht.
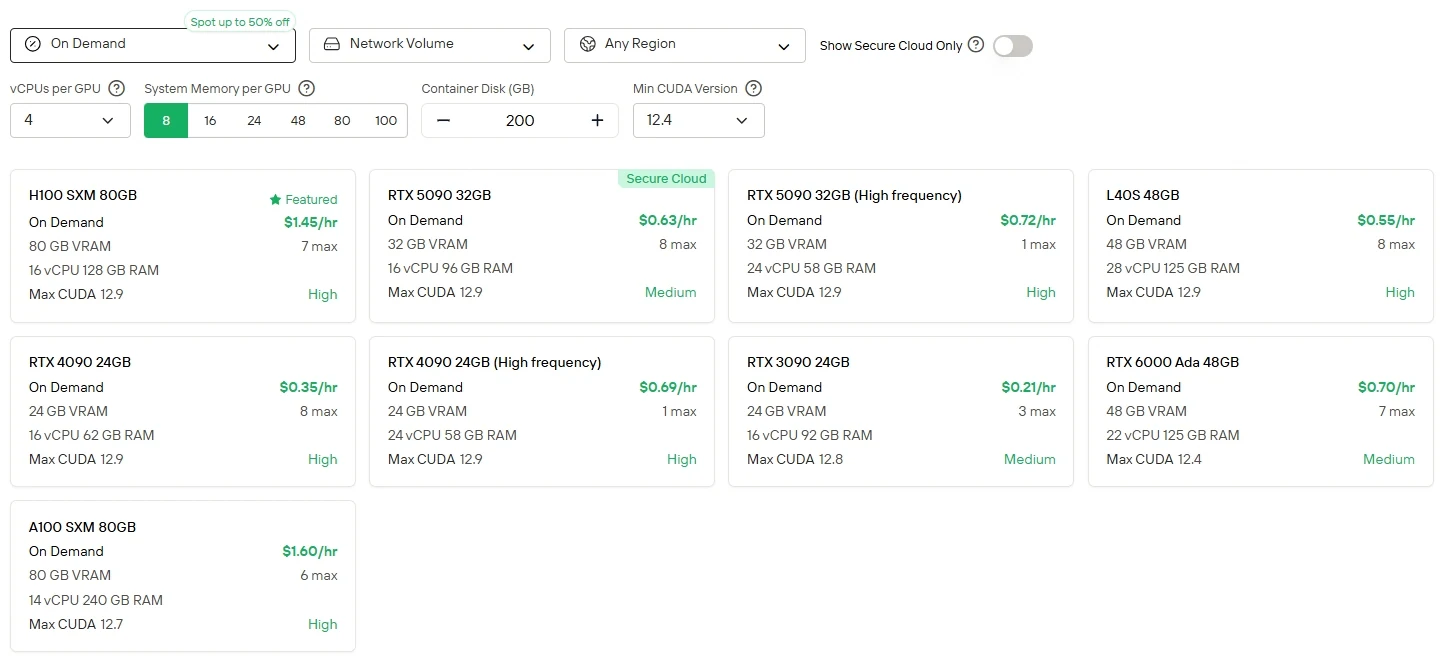
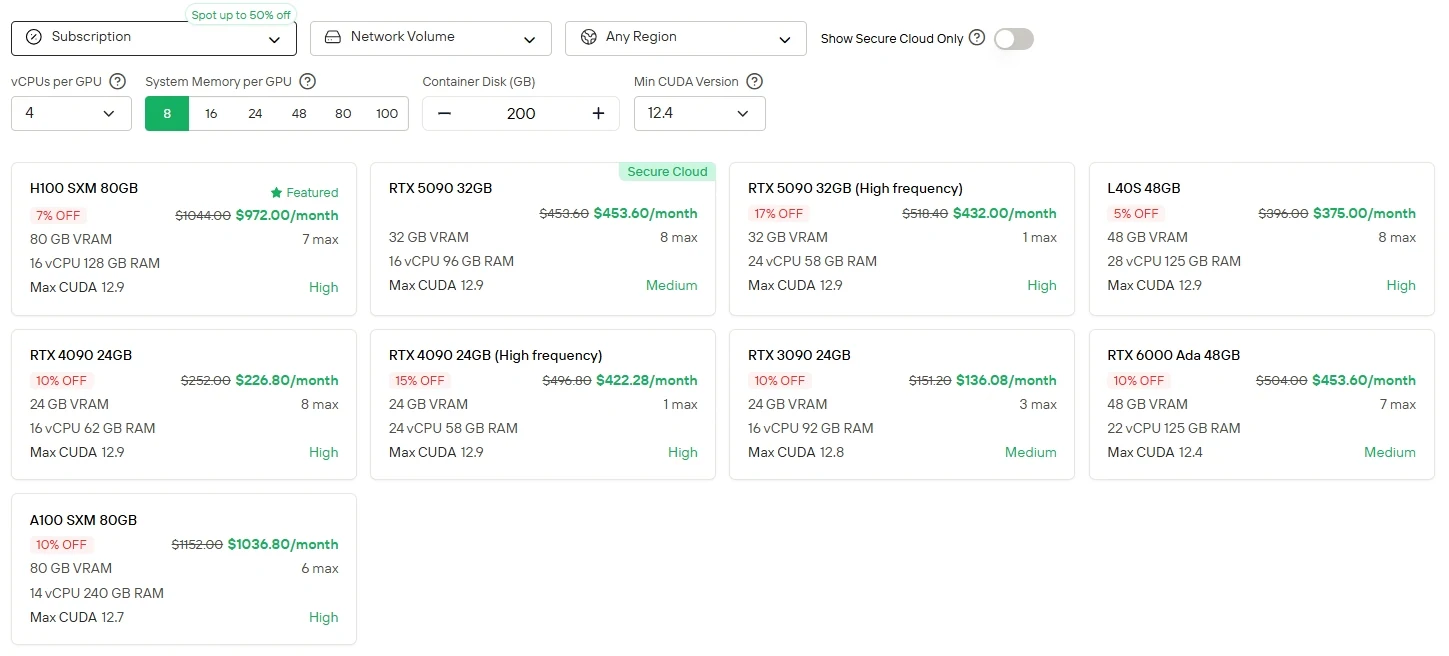
Novita AI bietet Minimax M2 APIs mit einem 204K-Kontextfenster zu Kosten von $0,3/1M Eingabe-Token und $1,2/1M Ausgabe-Token und ermöglicht so einen erschwinglichen Zugang zu modernsten agentischen Fähigkeiten.
So greifen Sie über API auf Minimax M2 zu
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.
Probieren Sie Minimax M2 jetzt kostenlos aus!
Schritt 2: Starten Sie Ihre kostenlose Testversion
Wählen Sie Ihr Modell aus und starten Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 3: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Wenn Sie die Seite „Einstellungen“ aufrufen, können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.
Schritt 4: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Fazit
Minimax M2 verschiebt die Grenzen der intelligenten Leistung durch sein Mixture-of-Experts-Design, aber diese Leistung geht mit erheblichen Hardware-Anforderungen einher. Selbst unter aggressiver Quantisierung benötigt das Modell noch über 80 GB VRAM, was es für die meisten Consumer-GPUs unerreichbar macht. Dies macht die lokale Bereitstellung weitgehend unpraktisch, während cloudbasierte API-Anbieter wie Novita AI der zuverlässigste Weg bleiben, um die Fähigkeiten von Minimax M2 zu nutzen.
Häufig gestellte Fragen
Was ist Minimax M2?
Minimax M2 ist ein groß angelegtes Mixture-of-Experts (MoE) Sprachmodell, das von MiniMax AI für maximale Codierungs- und agentische KI-Workflows entwickelt wurde.
Wie viel VRAM benötige ich, um Minimax M2 auszuführen?
Um Minimax M2 auszuführen, benötigen Sie ungefähr:
243 GB VRAM bei 8-Bit
188 GB VRAM bei 6-Bit
130 GB VRAM bei 4-Bit
83 GB VRAM bei 2-Bit
Kann ich über eine API auf Minimax M2 zugreifen?
Ja. Sie können über die API auf Novita AI auf Minimax M2 zugreifen, mit einem 204K-Kontextfenster zu Kosten von $0,3/1M Eingabe-Token und $0,12/1M Ausgabe-Token
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für Aufbau und Skalierung bereitstellt.



