

Minimax M2 est le dernier modèle de langage léger de pointe, conçu pour des workflows de codage et d’IA agentielle optimaux, alliant efficacité et capacités de raisonnement robustes. Mais une question essentielle se pose : quelle quantité de mémoire GPU est nécessaire pour l’exécuter efficacement ? La VRAM détermine si vous pouvez le déployer localement, sur du matériel d’entreprise ou via le cloud. Cet article explore les exigences en VRAM de Minimax M2 et compare les différentes options de déploiement, des configurations locales aux solutions basées sur API.
Minimax M2 : Bases et points forts
| Fonctionnalité | Minimax M2 |
|---|---|
| Paramètre | 230B avec 10B activés |
| Architecture | Mixure-of-Experts |
| Fenêtre de contexte | 204K Tokens |
| Open Source | Oui |
| Mode de réflexion | Think + Non-Think |
Benchmark de Minimax M2
Points clés
Intelligence exceptionnelle
MiniMax-M2 fait preuve d’une intelligence générale exceptionnelle dans des domaines tels que les mathématiques, les sciences, le raisonnement, le suivi des instructions, le codage et les tâches basées sur des agents. Il est actuellement classé premier modèle open source mondial par score composite.
Excellence en codage de bout en bout
Conçu pour des workflows de développement complets, MiniMax-M2 gère sans problème les modifications multi-fichiers, les cycles itératifs de codage-exécution-correction et les réparations automatisées de tests. Ses bons résultats sur les benchmarks de type Terminal-Bench et SWE-Bench confirment sa fiabilité dans des environnements de codage réels, des IDE aux systèmes CI, dans plusieurs langages de programmation.
Capacités agentielles robustes
MiniMax-M2 planifie et exécute efficacement des chaînes d’outils longues et multi-étapes couvrant des shells, des navigateurs, des systèmes de récupération et des exécuteurs de code. Lors d’évaluations de type BrowseComp, il trouve de manière fiable des informations difficiles d’accès, garde son raisonnement transparent et récupère sans problème des erreurs d’exécution partielles.
Architecture optimisée
Avec 10 milliards de paramètres actifs sur une architecture de 230 milliards de paramètres, MiniMax-M2 offre une latence réduite, des coûts moindres et un débit élevé pour les agents interactifs comme pour l’inférence par lots importante, incarnant une nouvelle génération de modèles déployables qui restent exceptionnels en matière de codage et de performances agentielles.
Qu’est-ce que la VRAM ?
La VRAM (mémoire vive vidéo) fait référence à la mémoire dédiée du GPU qui stocke les paramètres du modèle, les poids et les données de calcul intermédiaires. Pour les LLM (modèles de langage de grande taille), la VRAM joue un rôle décisif : elle détermine si un modèle peut être chargé, la longueur de sa fenêtre de contexte et les tailles de batch possibles. Contrairement à la RAM système classique, la VRAM offre une bande passante extrêmement élevée pour supporter les opérations matricielles intensives au cœur des architectures Transformer. Pour faire simple, la VRAM est le facteur limitant clé pour l’inférence comme pour l’entraînement : une capacité insuffisante entraîne des crashes de mémoire saturée, des contextes plus courts et une forte dépendance à des déchargements plus lents.
Exigences en VRAM de Minimax M2
| Quantification | Poids uniquement (approx.) | GPU recommandé |
| Q8_0 (8-bit) | 243 Go | Nvidia H100 ×4 |
| Q6_K (6-bit) | 188 Go | Nvidia H100 ×3 |
| Q4_0 (4-bit) | 130 Go | Nvidia A100 ×2 |
| Q2_K (2-bit) | 83,3 Go | RTX 6000 Ada ×2 |
| Aspect | Déploiement local | GPU cloud | Accès API |
|---|---|---|---|
| Investissement initial | >100 000 $ (cluster GPU NVIDIA, plus installation matérielle) | Modèle de paiement à l’heure sans frais initiaux importants | Tarification à l’usage sans aucun investissement matériel |
| Infrastructure | Nécessite des GPU, des systèmes de refroidissement et une alimentation électrique stable | Instances GPU (H100, A100, RTX 6000 Ada, etc.) disponibles à la demande via Novita AI | Entièrement gérée par l’infrastructure optimisée de Novita AI |
| Expertise technique | Nécessite une expertise ML/DevOps pour l’installation, les pilotes et la gestion de l’environnement | Installation basique seulement ; charge opérationnelle minimale par rapport au déploiement local | Seulement des connaissances basiques d’intégration API nécessaires |
| Maintenance | Surveillance continue, mises à jour des pilotes et maintenance matérielle | Novita AI gère les pilotes, les mises à jour et l’infrastructure ; les utilisateurs maintiennent leurs applications | Aucune maintenance requise |
| Scalabilité | Limitée par la capacité du matériel local | Scalabilité élastique : ajoutez ou libérez facilement des instances GPU selon l’évolution des charges | Instantanément scalable avec allocation flexible des ressources |
| Fiabilité | Dépend de la stabilité du matériel local | Garantie par des SLA et une infrastructure cloud robuste | SLA entreprise et runtime optimisé |
| Performance | Varie selon le modèle de GPU et la configuration | Performance de classe entreprise avec sélection flexible d’instances | Optimisée par le fournisseur pour des performances élevées constantes |
| Confidentialité des données | Contrôle local total sur les données | Dépend des politiques du fournisseur | Dépend des politiques du fournisseur |
Pour les utilisateurs qui préfèrent un contrôle direct et la flexibilité des GPU, Novita AI propose un service d’instances GPU cloud (y compris H100, A100, TX 6000 Ada, etc.) avec différents modes de facturation, permettant un déploiement haute performance sans la charge de l’installation de matériel local.
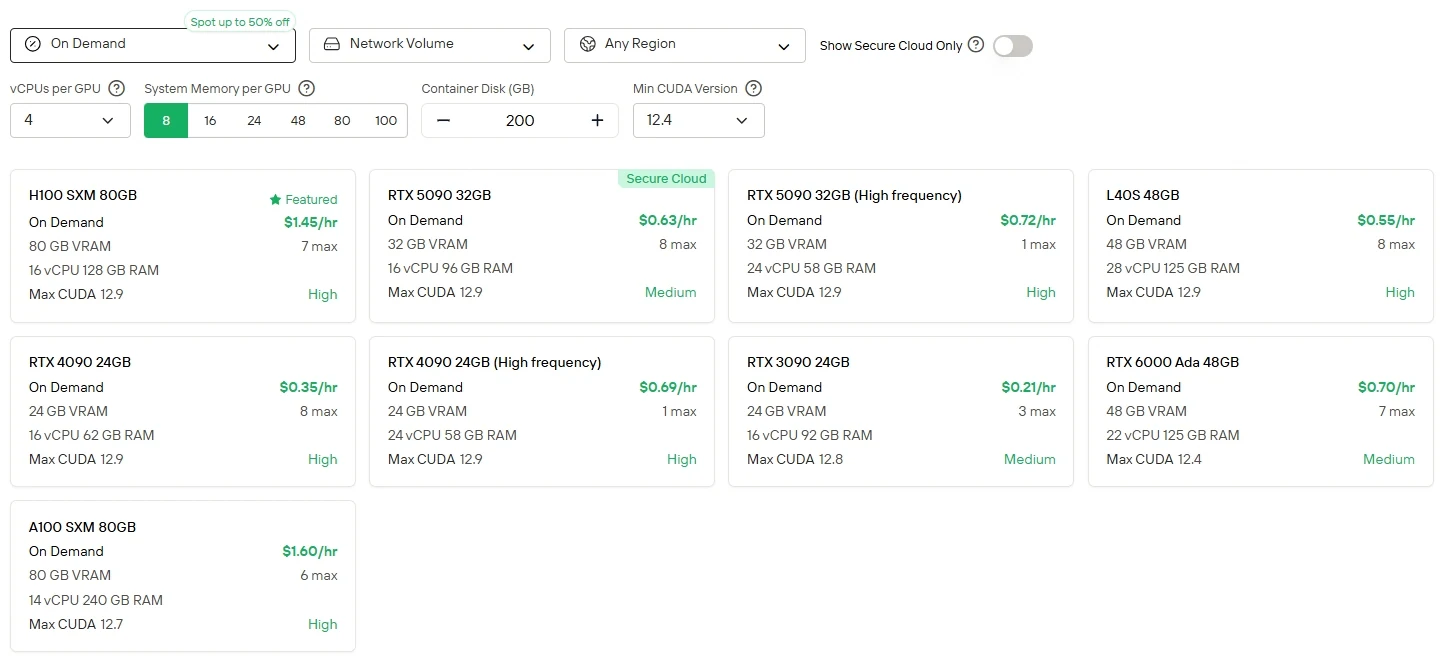
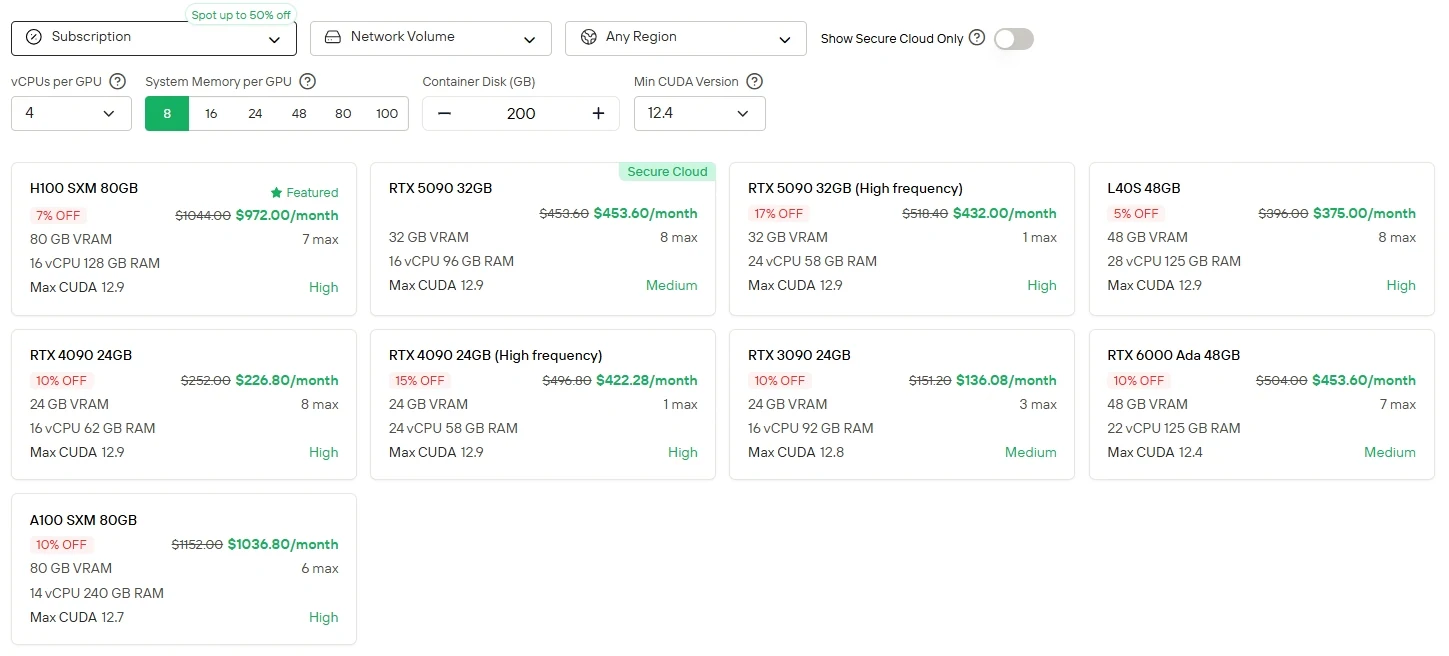
Novita AI fournit des API Minimax M2 avec une fenêtre de contexte de 204K au tarif de 0,3 $ par million de tokens en entrée et 1,2 $ par million de tokens en sortie, offrant un accès abordable à des capacités agentielles de pointe.
Comment accéder à Minimax M2 via l’API
Étape 1 : Se connecter et accéder à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.
Essayez Minimax M2 gratuitement dès maintenant !
Étape 2 : Démarrer votre essai gratuit
Sélectionnez votre modèle et commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 3 : Récupérer votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.
Étape 4 : Installer l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Conclusion
Minimax M2 repousse les limites des performances intelligentes grâce à sa conception de type Mixture-of-Experts, mais cette puissance s’accompagne d’exigences matérielles importantes. Même sous quantification agressive, le modèle nécessite toujours plus de 80 Go de VRAM, ce qui le rend inaccessible à la plupart des GPU grand public. Cela rend le déploiement local largement impraticable, tandis que les fournisseurs d’API basés sur le cloud comme Novita AI restent le moyen le plus fiable d’exploiter les capacités de Minimax M2.
Questions fréquemment posées
Qu’est-ce que Minimax M2 ?
Minimax M2 est un modèle de langage de grande échelle de type Mixture-of-Experts (MoE) développé par MiniMax AI, conçu pour des workflows de codage et d’IA agentielle optimaux.
Quelle quantité de VRAM est nécessaire pour exécuter Minimax M2 ?
Pour exécuter Minimax M2, vous avez besoin d’environ :
243 Go de VRAM en 8 bits
188 Go de VRAM en 6 bits
130 Go de VRAM en 4 bits
83 Go de VRAM en 2 bits
Puis-je accéder à Minimax M2 via une API ?
Oui. Vous pouvez accéder à Minimax M2 via l’API sur Novita AI avec une fenêtre de contexte de 204K au tarif de 0,3 $ par million de tokens en entrée et 0,12 $ par million de tokens en sortie
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour la construction et la mise à l’échelle.



