

Minimax M2 — это новейшая легкая передовая крупная языковая модель, созданная для оптимальной работы с кодом и агентными AI-рабочими процессами, сочетающая высокую эффективность и мощные возможности рассуждений. Однако остается важный вопрос: сколько видеопамяти (VRAM) требуется для её эффективной работы? Объем VRAM определяет, можно ли развернуть модель локально, на корпоративном оборудовании или через облако. В этой статье мы рассматриваем требования Minimax M2 к VRAM и сравниваем различные варианты развертывания: от локальных конфигураций до решений на основе API.
Minimax M2: Основные сведения и ключевые особенности
| Характеристика | Minimax M2 |
|---|---|
| Параметры | 230B, из них 10B активированных |
| Архитектура | Mixure-of-Experts |
| Контекстное окно | 204K токенов |
| Открытый исходный код | Да |
| Режим рассуждений | Think + Non-Think |
Бенчмарк Minimax M2
Ключевые особенности
Исключительный интеллект
MiniMax-M2 демонстрирует исключительный общий интеллект в таких областях, как математика, естественные науки, рассуждения, следование инструкциям, программирование и агентные задачи. В настоящее время модель занимает первое место в мировом рейтинге открытых моделей по совокупному баллу.
Экспертиза в программировании на всех этапах
Созданная для полных рабочих процессов разработчиков, MiniMax-M2 с легкостью справляется с редактированием нескольких файлов, итеративными циклами «запуск кода — исправление ошибок» и автоматическим восстановлением тестов. Её высокие результаты на бенчмарках Terminal-Bench и аналогичных SWE-Bench подтверждают надёжность в реальных средах программирования — от IDE до систем CI — на множестве языков программирования.
Мощные агентные возможности
MiniMax-M2 эффективно планирует и выполняет длинные многошаговые цепочки инструментов, включающие оболочки, браузеры, системы поиска информации и исполнители кода. В оценках в стиле BrowseComp модель надёжно находит труднодоступную информацию, сохраняет прозрачность рассуждений и плавно восстанавливается после частичных ошибок выполнения.
Оптимизированная архитектура
Благодаря 10 миллиардам активированных параметров из 230 миллиардов в архитектуре, MiniMax-M2 обеспечивает низкую задержку, сниженные затраты и высокую пропускную способность как для интерактивных агентов, так и для массового инференса, олицетворяя новое поколение развертываемых моделей, которые сохраняют выдающиеся показатели в программировании и агентных задачах.
Что такое VRAM?
VRAM (видеопамять с произвольным доступом) — это специализированная память GPU, в которой хранятся параметры модели, веса и промежуточные вычислительные данные. В крупных языковых моделях (LLM) VRAM играет решающую роль: она определяет, можно ли вообще загрузить модель, какого максимального размера может быть её контекстное окно и какие размеры пакетов данных возможны. В отличие от обычной оперативной памяти (RAM) системы, VRAM обеспечивает крайне высокую пропускную способность, необходимую для интенсивных матричных операций, лежащих в основе архитектур трансформеров. Проще говоря, VRAM является ключевым ограничивающим фактором как при инференсе, так и при обучении: недостаточный объём приводит к ошибкам нехватки памяти, сокращению контекста и сильной зависимости от более медленного выгрузки данных на внешнюю память.
Требования Minimax M2 к VRAM
| Квантизация | Только веса (приблизительно) | Рекомендуемый GPU |
| Q8_0 (8-бит) | 243 ГБ | Nvidia H100 ×4 |
| Q6_K (6-бит) | 188 ГБ | Nvidia H100 ×3 |
| Q4_0 (4-бит) | 130 ГБ | Nvidia A100 ×2 |
| Q2_K (2-бит) | 83,3 ГБ | RTX 6000 Ada ×2 |
| Параметр | Локальное развертывание | Облачный GPU | Доступ по API |
|---|---|---|---|
| Начальные инвестиции | >$100 000 (кластер GPU NVIDIA + дополнительное аппаратное оснащение) | Модель оплаты за час использования без крупных первоначальных вложений | Оплата по факту использования без каких-либо инвестиций в оборудование |
| Инфраструктура | Требуются GPU, системы охлаждения и стабильное электропитание | Экземпляры GPU (H100, A100, RTX 6000 Ada, TX 6000 Ada и др.) доступны по запросу через Novita AI | Полностью управляется оптимизированной инфраструктурой Novita AI |
| Технические компетенции | Требуются экспертные знания в области ML/DevOps для настройки, установки драйверов и управления окружением | Только базовая настройка; минимальные операционные затраты по сравнению с локальным развертыванием | Достаточно только базовых знаний интеграции с API |
| Техническое обслуживание | Непрерывный мониторинг, обновление драйверов и обслуживание оборудования | Novita AI управляет драйверами, обновлениями и инфраструктурой; пользователи поддерживают работу своих приложений | Техническое обслуживание не требуется |
| Масштабируемость | Ограничена возможностями локального оборудования | Эластичное масштабирование — легко добавляйте или освобождайте экземпляры GPU по мере изменения рабочей нагрузки | Мгновенно масштабируется с гибким распределением ресурсов |
| Надёжность | Зависит от стабильности локального оборудования | Поддерживается гарантиями SLA и надёжной облачной инфраструктурой | SLA корпоративного уровня и оптимизированная среда выполнения |
| Производительность | Зависит от модели и конфигурации GPU | Производительность корпоративного уровня с гибким выбором экземпляров | Оптимизирована провайдером для стабильно высокой производительности |
| Конфиденциальность данных | Полный локальный контроль над данными | Зависит от политик провайдера | Зависит от политик провайдера |
Для пользователей, которые предпочитают прямой контроль и гибкость в работе с GPU, Novita AI предлагает сервис облачных экземпляров GPU (в том числе H100, A100, TX 6000 Ada и др.) с разными режимами биллинга, что позволяет развертывать решения с высокой производительностью без затрат на настройку локального оборудования.
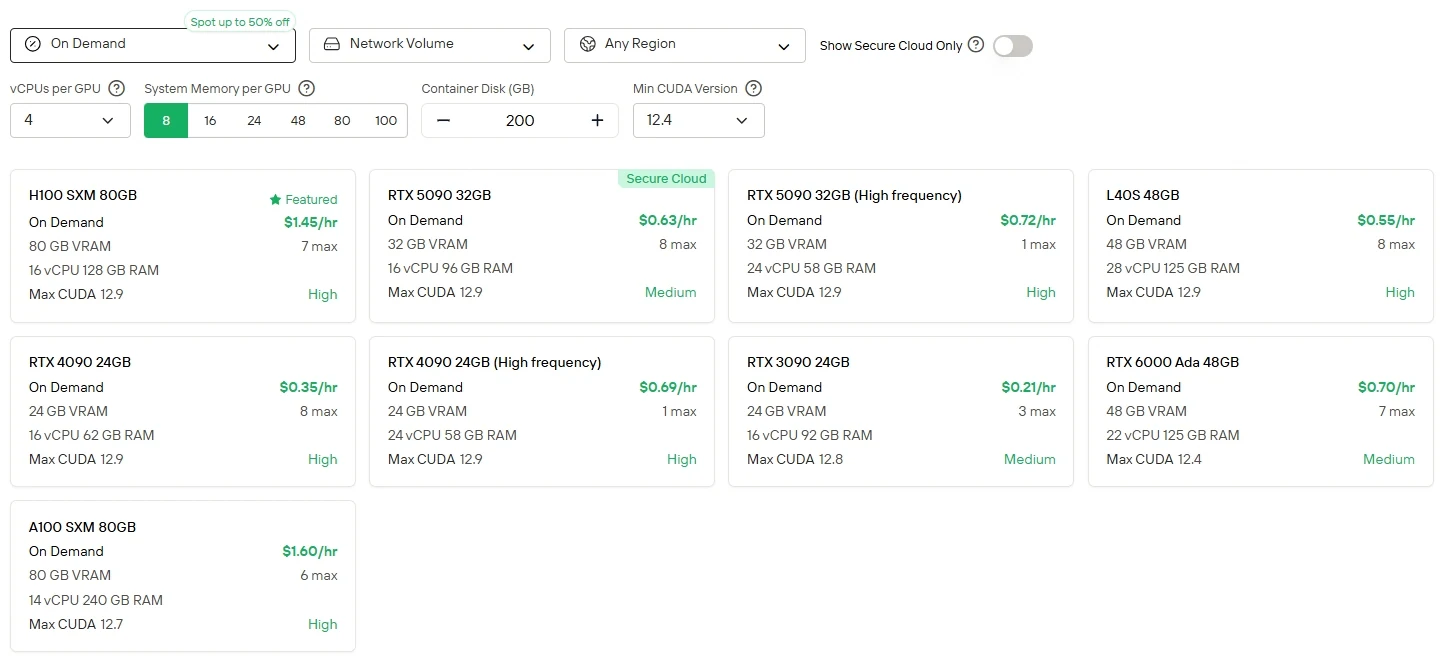
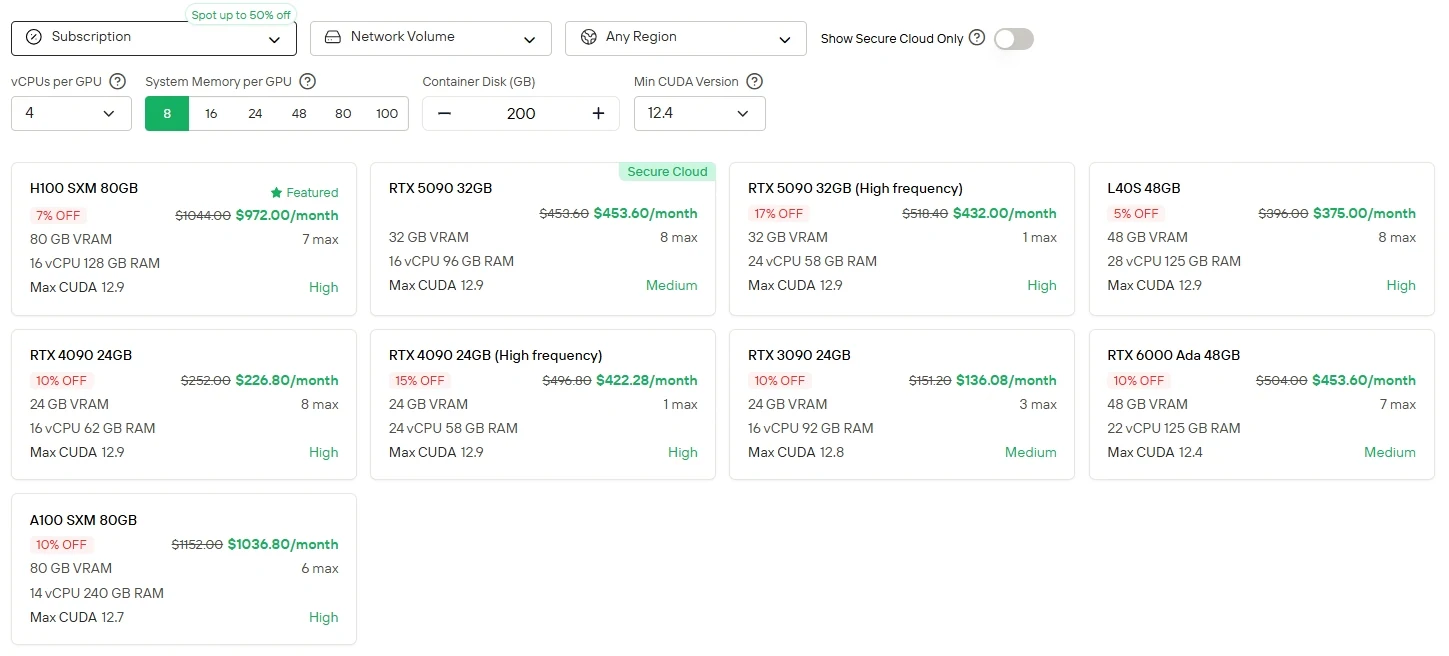
Novita AI предоставляет API для Minimax M2 с контекстным окном 204K токенов по стоимости $0,3 за 1M входных токенов и $1,2 за 1M выходных токенов, обеспечивая доступный доступ к передовым агентным возможностям.
Как получить доступ к Minimax M2 через API
Шаг 1: Войдите в аккаунт и перейдите в библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Библиотека моделей.
Попробуйте Minimax M2 бесплатно прямо сейчас!
Шаг 2: Начните бесплатный пробный период
Выберите модель и начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Шаг 3: Получите ваш API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдя на страницу «Настройки», вы можете скопировать API-ключ, как показано на изображении.
Шаг 4: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с помощью вашего API-ключа, чтобы начать взаимодействие с LLM Novita AI. Ниже приведён пример использования API завершения чата для пользователей Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Заключение
Minimax M2 расширяет границы интеллектуальной производительности благодаря архитектуре Mixture-of-Experts, но такая мощность сопряжена с серьёзными требованиями к оборудованию. Даже при агрессивной квантизации модели требуется более 80 ГБ VRAM, что выходит далеко за рамки возможностей большинства потребительских GPU. Это делает локальное развертывание в большинстве случаев нецелесообразным, поэтому облачные API-провайдеры, такие как Novita AI, остаются наиболее надёжным способом использовать возможности Minimax M2.
Часто задаваемые вопросы
Что такое Minimax M2?
Minimax M2 — это крупномасштабная языковая модель с архитектурой Mixture-of-Experts (MoE), разработанная компанией MiniMax AI для максимальной эффективности в программировании и агентных AI-рабочих процессах.
Сколько VRAM требуется для запуска Minimax M2?
Для запуска Minimax M2 вам потребуется приблизительно:
243 ГБ VRAM при 8-битной квантизации
188 ГБ VRAM при 6-битной квантизации
130 ГБ VRAM при 4-битной квантизации
83 ГБ VRAM при 2-битной квантизации
Можно ли получить доступ к Minimax M2 через API?
Да. Вы можете получить доступ к Minimax M2 через API на платформе Novita AI с контекстным окном 204K токенов по стоимости $0,3 за 1M входных токенов и $0,12 за 1M выходных токенов
Novita AI — это облачная AI-платформа, которая предлагает разработчикам простой способ развертывать AI-модели с помощью нашего простого API, а также предоставляет доступное и надёжное облако GPU для разработки и масштабирования решений.



