

Minimax M2は、効率性と強力な推論能力を兼ね備えた、コーディングとエージェント型AIワークフローに最適化された最先端の軽量大規模言語モデルです。しかし、効率的に実行するにはどのくらいのGPUメモリが必要かという重要な疑問があります。VRAMは、ローカルでデプロイするか、エンタープライズハードウェアで実行するか、クラウド経由で利用するかを決定します。この記事では、Minimax M2のVRAM要件を詳しく説明し、ローカルセットアップからAPIベースのソリューションまで、さまざまなデプロイパスを比較します。
Minimax M2:基本とハイライト
| 機能 | Minimax M2 |
|---|---|
| パラメータ | 230B(10Bアクティブ) |
| アーキテクチャ | Mixture-of-Experts |
| コンテキストウィンドウ | 204Kトークン |
| オープンソース | はい |
| 思考モード | Think + Non-Think |
Minimax M2ベンチマーク
主なハイライト
優れたインテリジェンス
MiniMax-M2は、数学、科学、推論、指示追従、コーディング、エージェントベースのタスクなど、さまざまな領域で優れた汎用知能を示します。現在、複合スコアで世界一のオープンソースモデルにランクされています。
エンドツーエンドのコーディング優秀性
完全な開発者ワークフロー向けに構築されたMiniMax-M2は、複数ファイルの編集、反復的なコード実行・修正サイクル、自動テスト修復を容易に処理します。Terminal-BenchやSWE-Bench類似ベンチマークでの強力な結果は、複数のプログラミング言語にわたるIDEからCIシステムに至るまで、実際のコーディング環境での信頼性を裏付けています。
堅牢なエージェント能力
MiniMax-M2は、シェル、ブラウザ、検索システム、コードランナーにまたがる長く複数ステップのツールチェーンを効果的に計画し実行します。BrowseCompスタイルの評価では、困難な情報を確実に見つけ出し、推論を透明に保ち、部分的な実行エラーからスムーズに回復します。
最適化されたアーキテクチャ
230億パラメータのアーキテクチャのうち、アクティブパラメータは100億で、MiniMax-M2は低レイテンシ、低コスト、高スループットをインタラクティブエージェントと大バッチ推論の両方で提供し、コーディングとエージェント性能で卓越した展開可能なモデルの新世代を体現しています。
VRAMとは?
VRAM(ビデオランダムアクセスメモリ)とは、GPU専用のメモリで、モデルのパラメータ、重み、中間計算データを格納します。大規模言語モデル(LLM)において、VRAMは決定的な役割を果たし、モデルをロードできるかどうか、コンテキストウィンドウをどれだけ拡張できるか、どのバッチサイズが可能かを決定します。通常のシステムRAMとは異なり、VRAMはトランスフォーマーアーキテクチャの中核である集中的な行列演算を支えるために非常に高い帯域幅を提供します。簡単に言えば、VRAMは推論とトレーニングの両方における重要な制限要因であり、容量が不十分だとメモリ不足のクラッシュ、コンテキストの短縮、低速なオフロードへの依存が発生します。
Minimax M2のVRAM要件
| 量子化 | 重みのみ(概算) | 推奨GPU |
| Q8_0(8ビット) | 243 GB | Nvidia H100 ×4 |
| Q6_K(6ビット) | 188 GB | Nvidia H100 ×3 |
| Q4_0(4ビット) | 130 GB | Nvidia A100 ×2 |
| Q2_K(2ビット) | 83.3 GB | RTX 6000 Ada ×2 |
| 側面 | ローカルデプロイ | クラウドGPU | APIアクセス |
|---|---|---|---|
| 初期投資 | 10万ドル以上(NVIDIA GPUクラスター、ハードウェアセットアップ含む) | 時間課金制、大きな初期費用なし | 従量課金制、ハードウェア投資ゼロ |
| インフラストラクチャ | GPU、冷却システム、安定した電源供給が必要 | Novita AI経由でGPUインスタンス(H100、A100、RTX 6000 Adaなど)をオンデマンドで利用可能 | Novita AIの最適化されたインフラにより完全管理 |
| 技術的専門知識 | セットアップ、ドライバ、環境管理にML/DevOpsの専門知識が必要 | 基本的なセットアップのみ、ローカルデプロイに比べ運用オーバーヘッド最小 | 基本的なAPI統合知識のみ必要 |
| メンテナンス | 継続的な監視、ドライバ更新、ハードウェアメンテナンス | Novita AIがドライバ、更新、インフラを管理。ユーザーはアプリケーションを維持 | メンテナンス不要 |
| スケーラビリティ | ローカルハードウェア容量に制限 | 弾力的なスケーリング。ワークロードに応じてGPUインスタンスを簡単に追加・解放 | 即時スケーラブル、柔軟なリソース割り当て |
| 信頼性 | ローカルハードウェアの安定性に依存 | SLA保証と堅牢なクラウドインフラに裏付け | エンタープライズグレードのSLAと最適化されたランタイム |
| パフォーマンス | GPUモデルと構成により変動 | 柔軟なインスタンス選択によるエンタープライズ級のパフォーマンス | プロバイダによる最適化で一貫した高性能 |
| データプライバシー | データは完全にローカル制御 | プロバイダポリシーに依存 | プロバイダポリシーに依存 |
直接制御とGPUの柔軟性を好むユーザー向けに、Novita AIはクラウドGPUインスタンスサービス(H100、A100、RTX 6000 Adaなど)をさまざまな課金モードで提供しており、ローカルハードウェアのセットアップ負担なく高性能なデプロイを実現します。
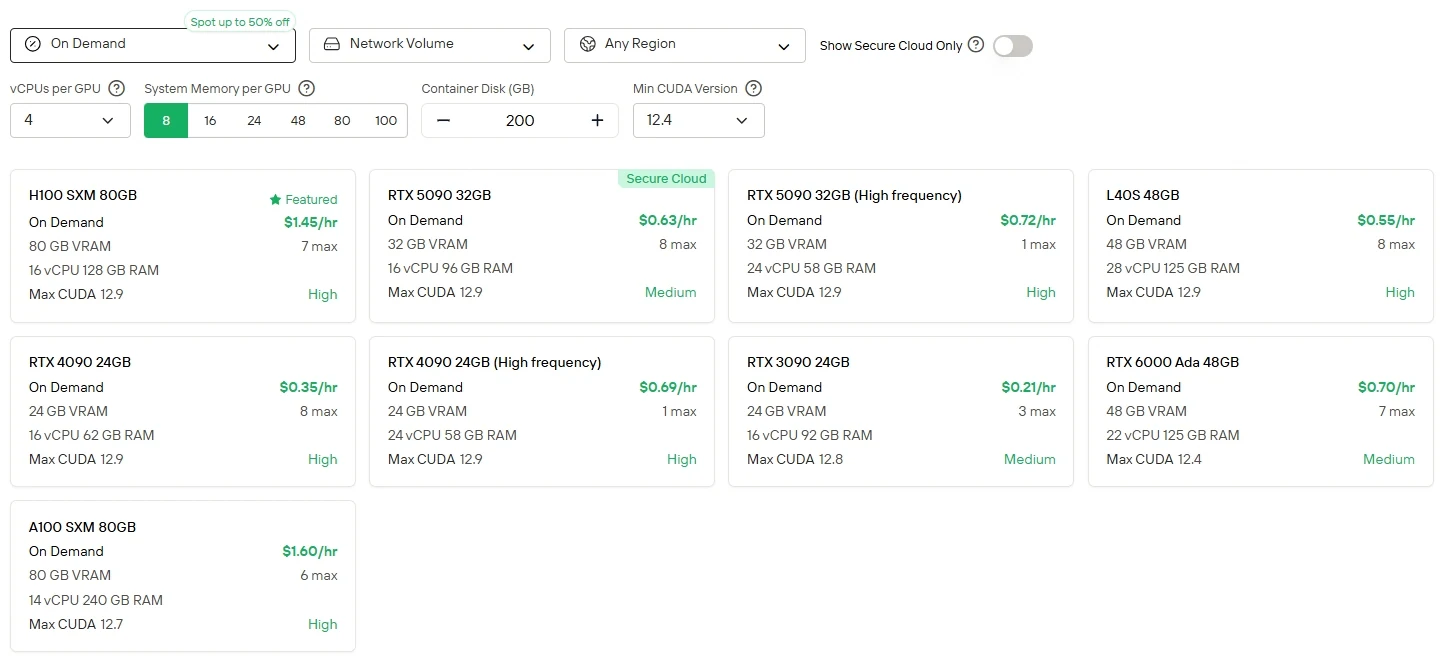
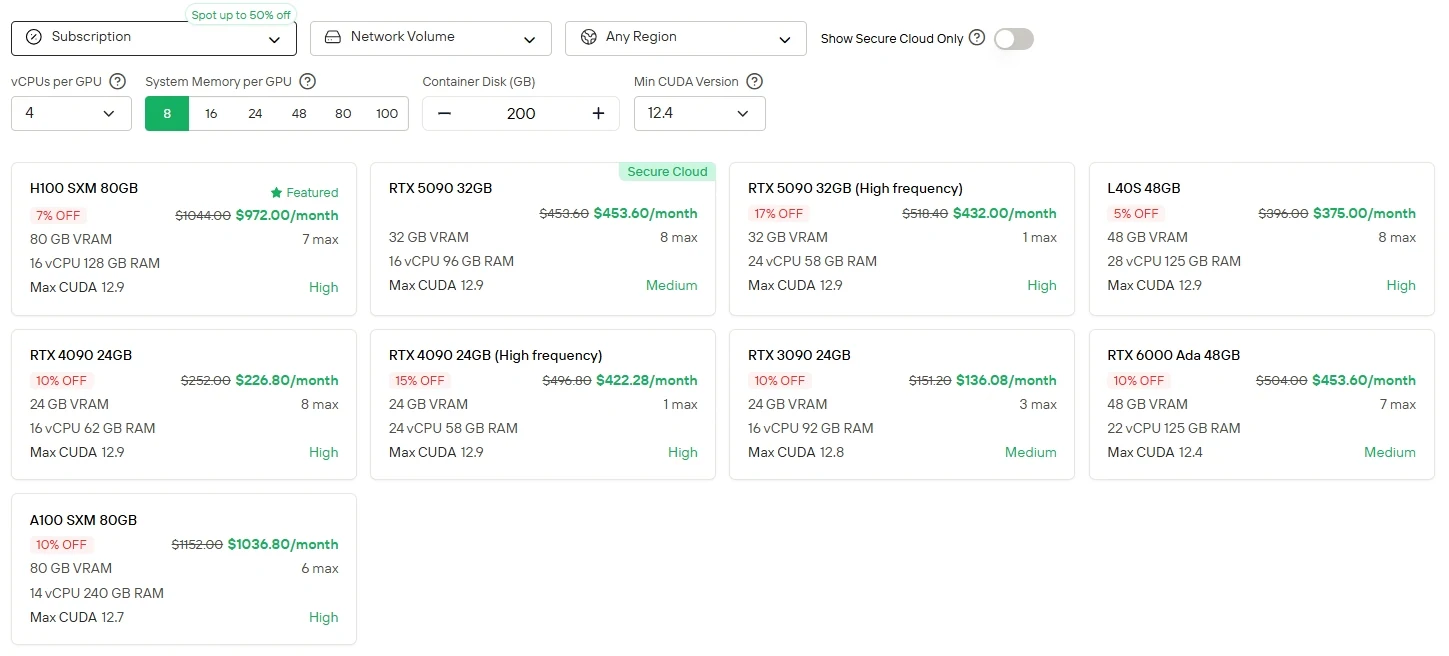
Novita AI は、204K コンテキストウィンドウのMinimax M2 APIを、入力1Mトークンあたり0.3ドル、出力1Mトークンあたり1.2ドル で提供し、最先端のエージェント能力への手頃なアクセスを実現します。
API経由でMinimax M2にアクセスする方法
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、Model Libraryボタンをクリックします。
ステップ2:無料トライアルを開始
モデルを選択し、無料トライアルを開始して選択したモデルの機能を試してみましょう。
ステップ3:APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「Settings」ページに移動し、画像のようにAPIキーをコピーします。
ステップ4:APIをインストール
使用するプログラミング言語に対応したパッケージマネージャーを使用してAPIをインストールします。
インストール後、開発環境に必要なライブラリをインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。以下は、Pythonユーザー向けのchat completions APIの使用例です。
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
結論
Minimax M2は、Mixture-of-Experts設計によりインテリジェントパフォーマンスの限界を押し広げていますが、その力には深刻なハードウェア要求が伴います。積極的な量子化を行っても、モデルには依然として80GB以上のVRAMが必要であり、ほとんどのコンシューマーGPUの能力をはるかに超えています。そのため、ローカルデプロイはほとんど非現実的であり、Novita AIのようなクラウドベースのAPIプロバイダーがMinimax M2の能力を活用する最も信頼性の高い方法です。
よくある質問
Minimax M2とは?
Minimax M2は、MiniMax AIが開発した大規模なMixture-of-Experts(MoE)言語モデルで、コーディングとエージェント型AIワークフローに最大限最適化されています。
Minimax M2を実行するにはどれくらいのVRAMが必要ですか?
Minimax M2 を実行するには、おおよそ以下のVRAMが必要です:
8ビット:243 GB
6ビット:188 GB
4ビット:130 GB
2ビット:83 GB
API経由でMinimax M2にアクセスできますか?
はい。Novita AIのAPIを通じてMinimax M2にアクセスでき、204K コンテキストウィンドウ、入力1Mトークンあたり0.3ドル、出力1Mトークンあたり0.12ドル で提供されています。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできると同時に、手頃で信頼性の高いGPUクラウドを構築・提供するAIクラウドプラットフォームです。



