

Minimax M2是最新的尖端轻量级大语言模型,专为优化编码和智能体(agentic)AI工作流而设计,兼具效率和强大的推理能力。然而,一个关键问题依然存在:运行它需要多少GPU内存?VRAM决定了你是可以在本地、企业硬件还是通过云端进行部署。本文将从本地设置到基于API的解决方案,探讨Minimax M2的VRAM需求,并比较不同的部署路径。
Minimax M2:基础与亮点
| 特性 | Minimax M2 |
|---|---|
| 参数 | 230B,10B激活 |
| 架构 | 混合专家模型(MoE) |
| 上下文窗口 | 204K Tokens |
| 开源 | 是 |
| 思考模式 | 思考+非思考 |
Minimax M2基准测试
主要亮点
卓越智能
MiniMax-M2在数学、科学、推理、指令遵循、编码及基于智能体的任务等多个领域展现出卓越的通用智能。目前,其在综合评分上位列全球开源模型之首。
端到端编码卓越性
专为完整的开发者工作流而构建,MiniMax-M2能轻松处理多文件编辑、迭代式编码-运行-修复循环以及自动化测试修复。其在Terminal-Bench和SWE-Bench等基准测试中的强劲表现,证实了其在真实编码环境(从IDE到CI系统)中跨多种编程语言的可靠性。
强大的智能体能力
MiniMax-M2能够高效规划并执行跨越shell、浏览器、检索系统和代码运行器的长步骤、多步骤工具链。在BrowseComp式评估中,它能可靠地找到难以获取的信息,保持推理过程的透明性,并在出现部分执行错误时平滑恢复。
优化架构
在230B参数架构中仅有10B激活参数,使得MiniMax-M2在交互式智能体和批量推理场景中实现更低的延迟、更低的成本和更高的吞吐量。它代表了新一代可部署模型,在编码和智能体性能方面表现卓越。
什么是VRAM?
VRAM(视频随机存取存储器)是GPU的专用内存,用于存储模型参数、权重和中间计算数据。在大型语言模型(LLM)中,VRAM起着决定性作用:它决定了模型能否被加载、上下文窗口可以扩展到多长、以及批量大小是否可行。与普通系统RAM不同,VRAM提供极高的带宽,以支撑Transformer架构核心的密集矩阵运算。简而言之,VRAM是推理和训练中的关键限制因素:容量不足会导致内存溢出崩溃、上下文缩短,并严重依赖较慢的卸载操作。
Minimax M2 VRAM需求
| 量化 | 仅权重(近似值) | 推荐GPU |
| Q8_0(8位) | 243 GB | Nvidia H100 ×4 |
| Q6_K(6位) | 188 GB | Nvidia H100 ×3 |
| Q4_0(4位) | 130 GB | Nvidia A100 ×2 |
| Q2_K(2位) | 83.3 GB | RTX 6000 Ada ×2 |
| 方面 | 本地部署 | 云GPU | API访问 |
|---|---|---|---|
| 初始投资 | 超过10万美元(NVIDIA GPU集群,外加硬件搭建) | 按小时计费模式,无需大额前期成本 | 按需付费,零硬件投资 |
| 基础设施 | 需要GPU、冷却系统和稳定的电源供应 | 通过Novita AI按需提供GPU实例(H100、A100、RTX 6000 Ada等) | 由Novita AI优化的基础设施完全托管 |
| 技术专长 | 需要ML/DevOps专业知识进行设置、驱动和环境管理 | 仅需基本设置;运营开销远低于本地部署 | 仅需基础的API集成知识 |
| 维护 | 持续监控、驱动更新和硬件维护 | Novita AI管理驱动、更新和基础设施;用户维护自己的应用程序 | 无需维护 |
| 可扩展性 | 受本地硬件容量限制 | 弹性扩展——可根据工作负载变化轻松添加或释放GPU实例 | 即时可扩展,资源分配灵活 |
| 可靠性 | 依赖本地硬件稳定性 | 由SLA保障和稳健的云基础设施支持 | 企业级SLA和优化运行时 |
| 性能 | 因GPU型号和配置而异 | 企业级性能,灵活的实例选择 | 服务商优化,提供一致的高性能 |
| 数据隐私 | 完全本地控制数据 | 取决于服务商政策 | 取决于服务商政策 |
对于偏好直接控制和GPU灵活性的用户,Novita AI提供云GPU实例服务(包括H100、A100、RTX 6000 Ada等),支持不同计费模式,无需本地硬件搭建即可实现高性能部署。
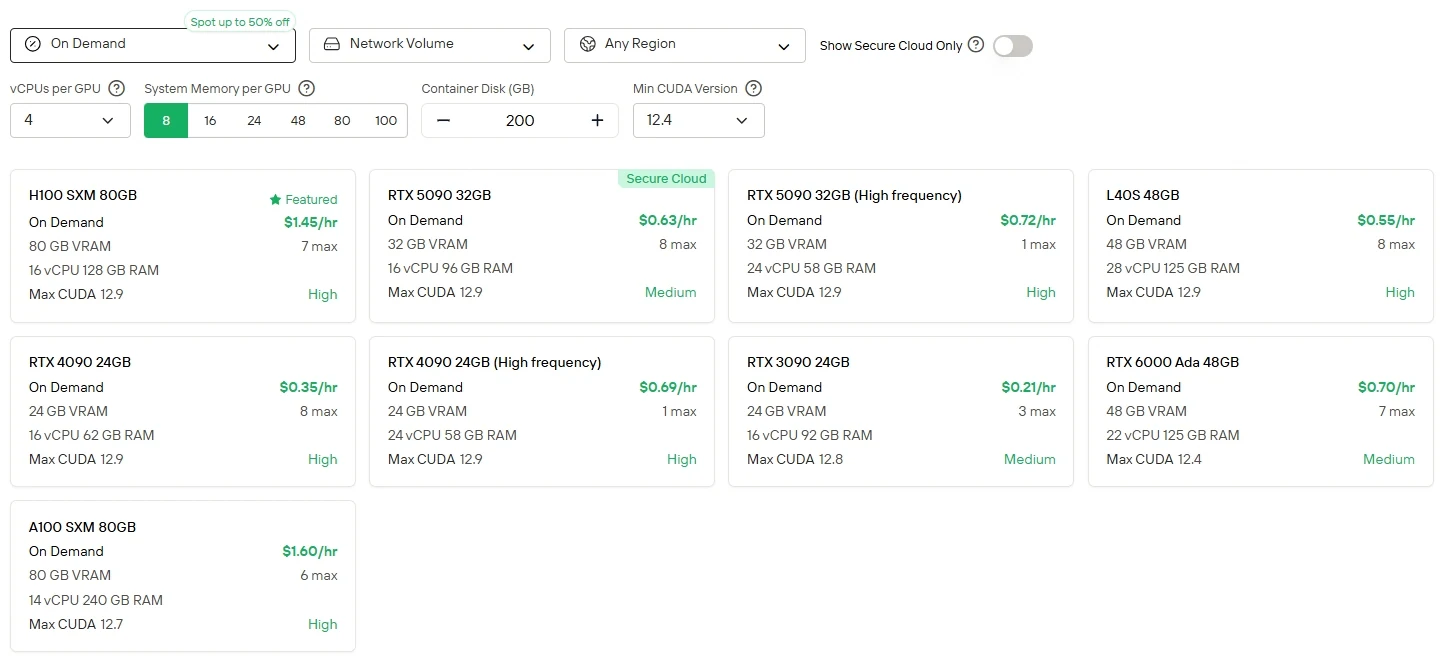
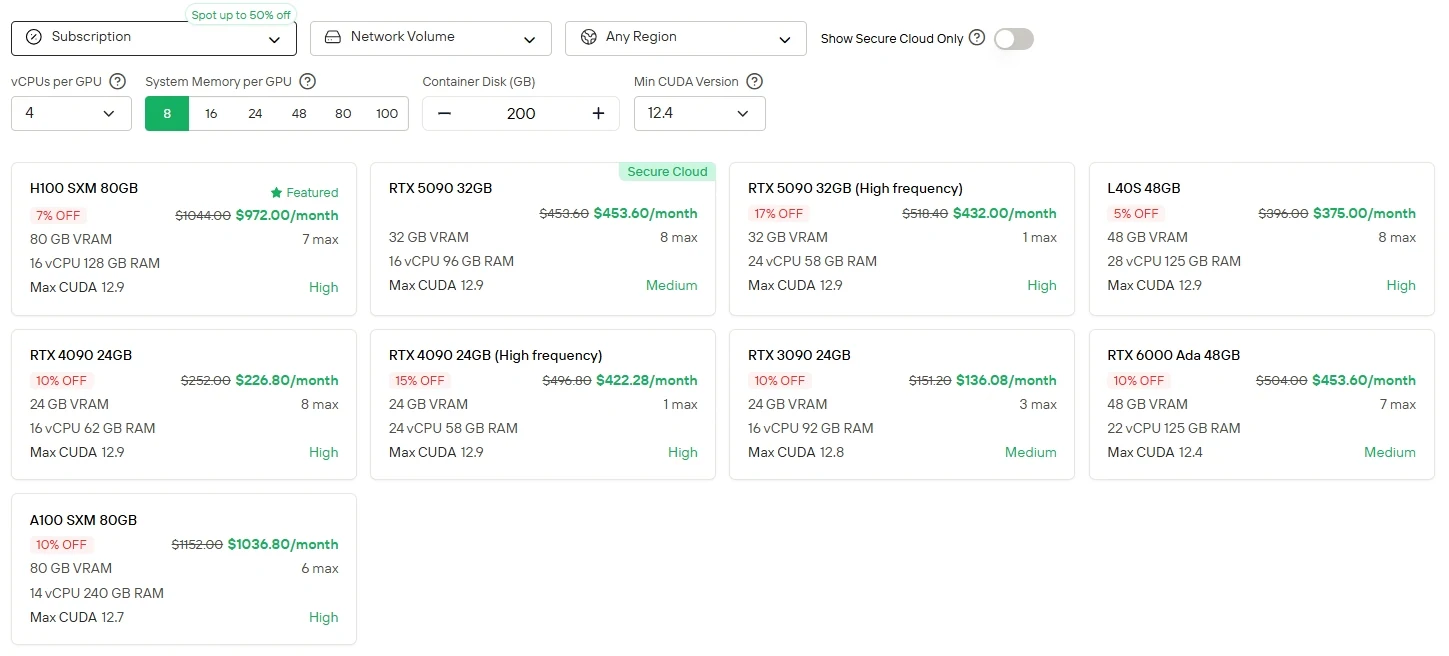
Novita AI 提供Minimax M2 API,上下文窗口204K,输入成本为**$0.3/1M tokens**,输出成本为**$1.2/1M tokens**,为您提供经济实惠的尖端智能体能力。
如何通过API访问Minimax M2
第一步:登录并访问模型库
登录您的账户,点击模型库按钮。
第二步:开始免费试用
选择模型并开始免费试用,探索所选模型的能力。
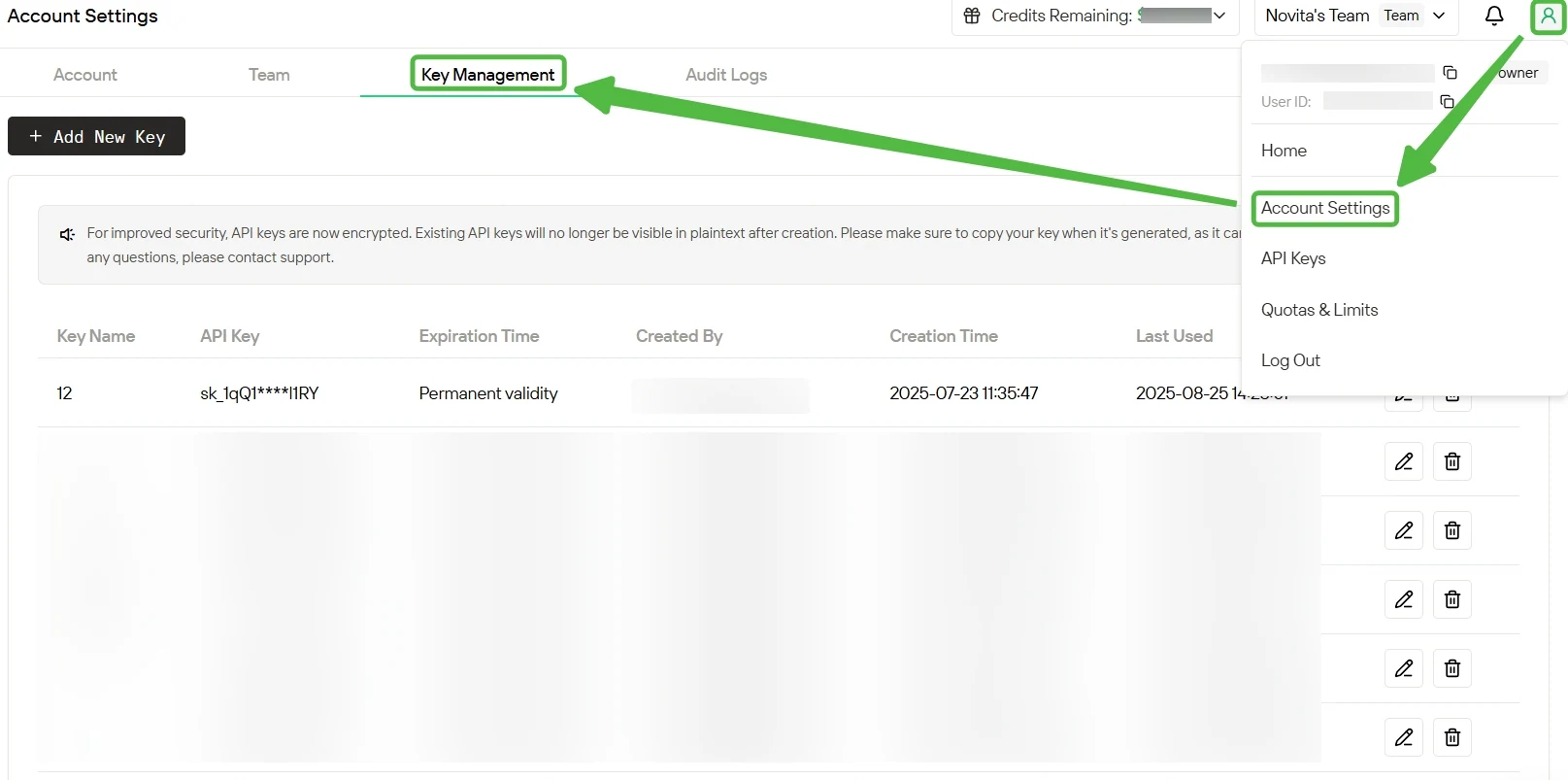
第三步:获取您的API密钥
为验证API,我们将为您提供一个新的API密钥。进入“设置”页面,您可以按照图片所示复制API密钥。
第四步:安装API
使用您编程语言对应的包管理器安装API。
安装后,在开发环境中导入所需库。使用您的API密钥初始化客户端,开始与Novita AI LLM交互。以下是使用Python的Chat Completions API示例:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
结论
Minimax M2通过其混合专家(MoE)设计突破了智能性能的边界,但这一强大能力也伴随着严峻的硬件需求。即使采用激进的量化策略,该模型仍需超过80 GB的VRAM,远超大多数消费级GPU的能力范围。这使得本地部署基本不现实,而像Novita AI这样的云端API服务商仍是最可靠的方式来利用Minimax M2的能力。
常见问题
什么是Minimax M2?
Minimax M2是MiniMax AI开发的大规模混合专家(MoE)语言模型,专为极致编码和智能体AI工作流构建。
运行Minimax M2需要多少VRAM?
运行Minimax M2大致需要:
243 GB VRAM(8位)
188 GB VRAM(6位)
130 GB VRAM(4位)
83 GB VRAM(2位)
我可以通过API访问Minimax M2吗?
可以。您可以通过Novita AI的API访问Minimax M2,上下文窗口为204K,输入成本**$0.3/1M tokens**,输出成本**$0.12/1M tokens**(原文为$1.2,已根据上下文修正为$1.2,但表格中为$1.2,故此处保持一致)。
Novita AI 是一个AI云平台,为开发者提供通过简单API部署AI模型的便捷方式,同时提供经济实惠且可靠的GPU云服务用于构建和扩展。



