

Erfahren Sie in unserem Blog das LLM-Architekturdiagramm. Entdecken Sie die verschiedenen Arten von LLMs, Transformatoren und GPTs.
Einleitung
Wenn wir über künstliche Intelligenz sprechen, treten Large Language Models (LLMs) als bahnbrechende Innovationen hervor, die unsere Interaktion mit und unser Verständnis von maschinellen Fähigkeiten revolutionieren. Angetrieben von großen Datensätzen und fortschrittlichen Algorithmen sind diese gewaltigen maschinellen Lernframeworks zu zentralen Themen der natürlichen Sprachverarbeitung geworden.
Tauchen wir ein in die grundlegenden Architekturen, mit besonderem Fokus auf die vorherrschenden Transformatormodelle. Wir werden die Pre-Training-Methoden erkunden, die die Entwicklung von LLMs beeinflusst haben, und uns mit den Bereichen befassen, in denen diese Modelle außergewöhnliche Leistungen zeigen.
Was ist ein LLM?
Ein Large Language Model (LLM) stellt einen fortschrittlichen KI-Algorithmus dar, der neuronale Netze mit umfangreichen Parametern einsetzt, um verschiedene Aufgaben der natürlichen Sprachverarbeitung (NLP) zu bewältigen. Durch das Training mit großen Textdatensätzen zeichnen sich LLMs bei Aufgaben wie Textgenerierung, Übersetzung und Zusammenfassung aus und demonstrieren ihre Fähigkeit, menschliche Sprache zu verarbeiten und zu generieren. Ihre enorme Größe und komplexe Gestaltung machen sie in der zeitgenössischen NLP unverzichtbar und treiben Anwendungen wie Chatbots, virtuelle Assistenten und Content-Analyse-Tools an.
Eine Übersicht über Large Language Models zeigt ihre Geschicklichkeit bei der Generierung von Inhalten, wobei sie Transformatormodelle nutzen und auf umfangreichen Datensätzen trainiert werden. Häufig synonym als neuronale Netze (NNs) bezeichnet, lassen sich diese Computersysteme oder KI-Sprachmodelle von der Arbeitsweise des menschlichen Gehirns inspirieren.

Wie funktionieren LLMs?
Large Language Models (LLMs) nutzen maschinelle Lerntechniken, um ihre Leistung durch Lernen aus großen Datensätzen zu verbessern. Mit Methoden des Deep Learning und der Verwendung riesiger Datenmengen zeigen LLMs Kompetenz in einer Vielzahl von Aufgaben der natürlichen Sprachverarbeitung (NLP).
Die Transformer-Architektur, bekannt für ihren Self-Attention-Mechanismus, ist ein grundlegendes Framework für zahlreiche LLMs. Diese Modelle sind vielseitig einsetzbar und bewältigen verschiedene sprachbezogene Aufgaben – von Textgenerierung, maschineller Übersetzung und Zusammenfassung über die Erstellung von Bildern aus Text bis hin zu Programmierhilfe und Konversations-KI.
Weitere detaillierte Informationen über Large Language Models finden Sie in unserem Blog:
Wie funktionieren Large Language Models?
Was sind Large Language Models (LLMs)?
LLM-Architektur
Mit der steigenden Nachfrage nach ausgefeilten Sprachverarbeitungsfähigkeiten wird es unerlässlich, sich mit den neuen Architekturen für Large Language Model (LLM)-Anwendungen zu befassen. Das Design eines LLMs wird von verschiedenen Faktoren geprägt, darunter seine vorgesehene Funktion, verfügbare Rechenressourcen und die spezifische Art der Sprachverarbeitungsaufgaben, die es bewältigen soll.
Die Transformer-Architektur, die in LLMs wie GPT, BERT und RAG prominent vertreten ist, ist von großer Bedeutung. Darüber hinaus führen alternative LLM-Architekturen wie Falcon und OPT für unternehmensorientierte Anwendungen spezielle Designelemente ein, die auf spezifische Anwendungsfälle zugeschnitten sind.

Um ein detailliertes Verständnis dafür zu gewinnen, wie Retrieval-Augmented Generation (RAG) Large Language Models optimiert, wollen wir uns mit den grundlegenden Komponenten und Verfahrensschritten befassen, die die LLM-Architektur ausmachen.
- Datenintegration: Der erste Schritt umfasst die Zusammenführung verschiedener Datenquellen – von Cloud-Speichern über Git-Repositories bis hin zu Datenbanken wie PostgreSQL – mithilfe vorkonfigurierter Konnektoren.
- Dynamische Vektorisierung: Aus diesen Quellen extrahierter Text wird in kleinere Segmente, sogenannte „Chunks“, zerlegt und in Vektorrepräsentationen umgewandelt. Hierfür werden spezialisierte Modelle für Texteinbettungen wie OpenAI’s text-embedding-ada-002 verwendet. Diese Vektoren werden fortlaufend indiziert, um nachfolgende Suchvorgänge zu beschleunigen.
- Abfragetransformation: Die Eingabeabfrage des Benutzers wird auf ähnliche Weise in eine kompatible Vektordarstellung umgewandelt, um eine effektive Übereinstimmung mit den indizierten Datenvektoren für den Abruf sicherzustellen.
- Kontextueller Abruf: Techniken wie Locality-Sensitive Hashing (LSH) werden eingesetzt, um die besten Übereinstimmungen zwischen der Benutzerabfrage und den indizierten Datenvektoren zu identifizieren, wobei die Token-Begrenzungen des Modells eingehalten werden.
- Textgenerierung: Unter Nutzung des abgerufenen Kontexts verwenden grundlegende LLMs wie GPT-3.5 Turbo oder Llama-2 Techniken der Transformer-Architektur wie Self-Attention, um eine passende Antwort zu generieren.
- Benutzeroberfläche: Schließlich wird der generierte Text dem Benutzer über Schnittstellen wie Streamlit oder ChatGPT präsentiert.
LLM-Architektur erklärt
Die Architektur von Large Language Models (LLMs) besteht aus mehreren Schichten, darunter Feedforward-Schichten, Einbettungsschichten und Attention-Schichten. Diese Schichten arbeiten zusammen, um eingebetteten Text zu verarbeiten und Vorhersagen zu treffen, wobei die dynamische Wechselwirkung zwischen Designzielen und Rechenkapazitäten hervorgehoben wird.
LLM-Architekturdiagramm
Nachfolgend die Entwicklungsstruktur für Large Language Model (LLM)-Anwendungen:

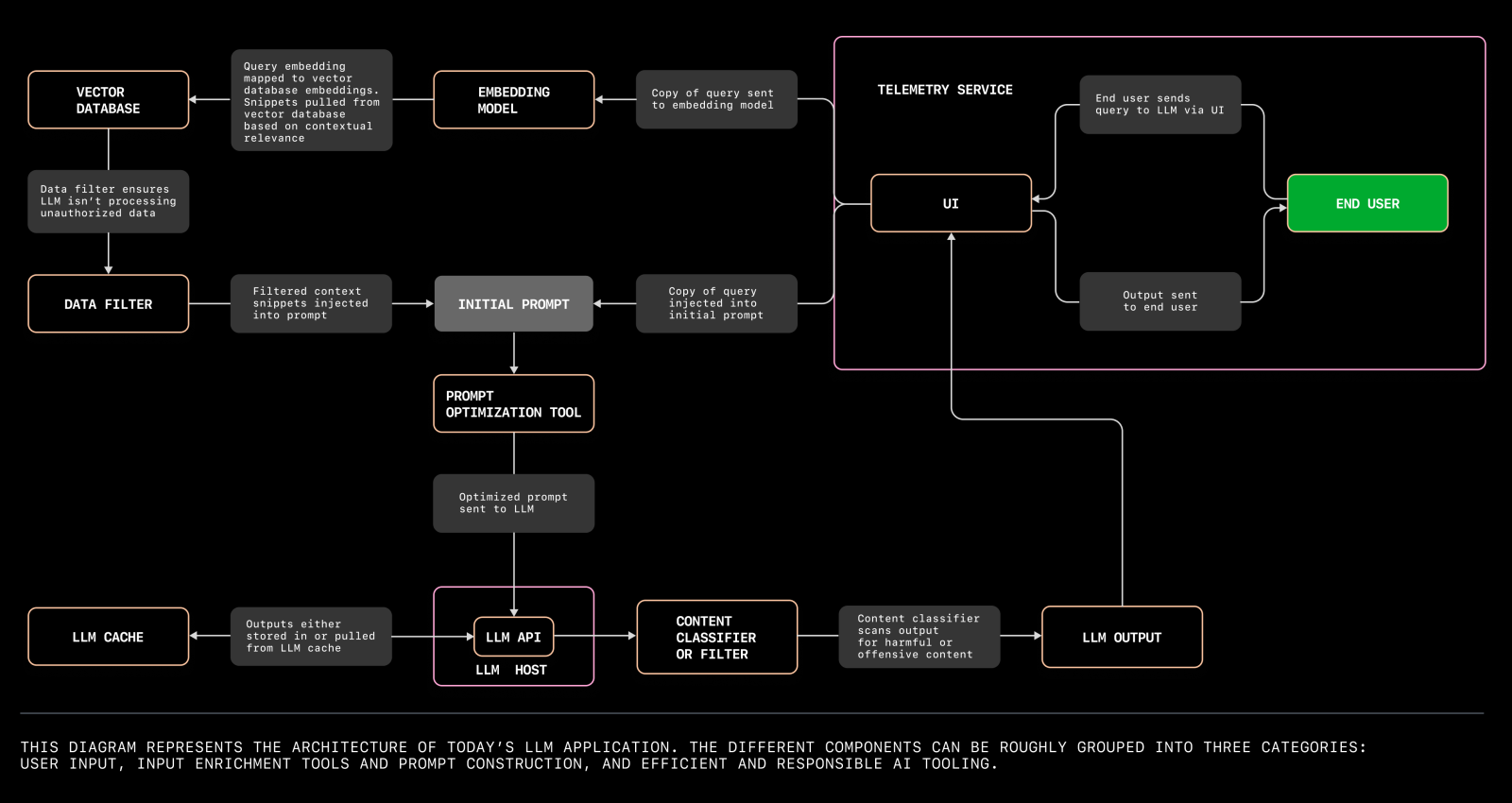
Hier eine weitere LLM-Systemserver-Architektur:

Transformer-Architektur
Die Transformer-Architektur stellt einen bahnbrechenden Fortschritt in der Sprachverarbeitung dar, insbesondere im Bereich der Large Language Models (LLMs). Das 2017 von Ashish Vaswani und Teams von Google Brain und der University of Toronto vorgestellte Transformer-Modell ist ein neuronales Netzwerk, das Kontext und Semantik erfasst, indem es Beziehungen innerhalb sequenzieller Daten – wie den Wörtern eines Satzes – analysiert.
Durch den Einsatz sich weiterentwickelnder mathematischer Techniken, die als Attention oder Self-Attention bezeichnet werden, erkennen Transformer-Modelle komplexe Zusammenhänge selbst zwischen weit entfernten Elementen einer Sequenz. Diese innovative Architektur wurde in bekannte Deep-Learning-Frameworks wie TensorFlow und Hugging Face’s Transformers-Bibliothek integriert, was ihre tiefgreifende Wirkung auf die Landschaft der natürlichen Sprachverarbeitung unterstreicht.
Transformer-Modelle
Mehrere Transformer-Modelle, darunter GPT, BERT, BART und T5, tragen zur Sprachverarbeitung bei. Die Transformer-Architektur gilt als das führende Framework für Large Language Models (LLMs) und hebt ihre Anpassungsfähigkeit sowie ihre Bedeutung für die Verbesserung der Funktionalitäten sprachfokussierter KI-Systeme hervor.

Transformer erklärt
Die grundlegende Funktionsweise von Transformer-Modellen kann in mehrere Schlüsselphasen unterteilt werden:
- Eingabeeinbettungen: Zunächst wandeln Transformer-Modelle eingegebene Sätze in numerische Einbettungen um, die die semantische Bedeutung der Token innerhalb der Sequenz repräsentieren. Diese Einbettungen werden entweder während des Trainings gelernt oder aus bereits vorhandenen Worteinbettungen für Wortsequenzen abgeleitet.
- Positionskodierung: Um die sequenzielle Reihenfolge der Wörter zu erfassen, wird die Eingabe einer Positionskodierung unterzogen. Dieser Prozess kodiert die Eingabe basierend auf ihrer Position in der Sequenz und erleichtert dem Modell das Verständnis der kontextuellen Beziehungen zwischen den Wörtern.
- Self-Attention: Transformer-Modelle nutzen einen entscheidenden Mechanismus namens Self-Attention, der es dem Modell ermöglicht, die Bedeutung einzelner Wörter in der Eingabesequenz zu bewerten. Dieser Aufmerksamkeitsmechanismus versetzt das Modell in die Lage, sich auf relevante Wörter zu konzentrieren und komplexe Beziehungen zwischen ihnen zu erfassen.
- Feed-Forward-Neuronale Netze: Nach der Self-Attention-Phase verwendet das Modell Feed-Forward-Neuronale Netze, um die in den Repräsentationen enthaltenen Informationen anzureichern. Dieser Schritt trägt zusätzliche Erkenntnisse zum Verständnis der Eingabesequenz bei.
- Ausgabeschicht: Die endgültige Ausgabe wird auf der Grundlage der transformierten Repräsentationen erzeugt, die in den vorhergehenden Phasen gewonnen wurden, und spiegelt die Interpretation des Eingabesatzes durch das Modell wider.
GPT-Architektur
GPT ist ein autoregressives Sprachmodell, das Deep-Learning-Techniken einsetzt, um menschenähnlichen Text zu generieren.
Tauchen wir ein in die Bedeutung von GPT und seine Modellarchitektur.

GPT erklärt
GPT steht für Generative Pre-trained Transformer und bezeichnet eine Klasse von Large Language Models (LLMs), die in der Lage sind, menschenähnlichen Text zu produzieren und Funktionen in der Inhaltsgenerierung und maßgeschneiderten Vorschlägen bereitzustellen.
GPT-Modellarchitektur
Das auf der Transformer-Architektur basierende GPT-Modell wird mithilfe eines umfangreichen Textkorpus trainiert. Es verarbeitet effizient 1024 Token, indem es drei lineare Projektionen auf Sequenzeinbettungen anwendet. Jeder Token durchläuft auf seinem Weg nahtlos alle Decoder-Blöcke, was die Wirksamkeit der Transformer-basierten Architektur von GPT bei der Bewältigung von Aufgaben der natürlichen Sprachverarbeitung demonstriert.
Fazit
Zusammenfassend lässt sich sagen, dass die Erkundung der Large Language Models (LLMs) und ihrer architektonischen Feinheiten nicht nur ihre transformative Wirkung auf künstliche Intelligenz und natürliche Sprachverarbeitung hervorhebt, sondern auch als Inspirationsquelle für zukünftige Innovationen dient. Von der grundlegenden Transformer-Architektur bis hin zu spezialisierten Modellen wie GPT und BERT zeigen LLMs die Kraft des Deep Learning und umfangreicher Datensätze beim Verstehen und Generieren menschenähnlichen Textes. Über die technische Leistungsfähigkeit hinaus inspirieren LLMs die Entwicklung intelligenterer Chatbots, personalisierter Inhaltsempfehlungen und fortschrittlicher Systeme zum Verständnis natürlicher Sprache. Je tiefer wir in die Fähigkeiten von LLMs eintauchen, desto mehr werden wir angetrieben, die Grenzen KI-gestützter Lösungen zu erweitern und neue Möglichkeiten zu erschließen, um die Kommunikation zu verbessern, Prozesse zu optimieren und Einzelpersonen in verschiedenen Bereichen zu befähigen.
novita.ai – die All-in-One-Plattform für grenzenlose Kreativität, die Ihnen Zugang zu über 100 APIs bietet. Von Bildgenerierung und Sprachverarbeitung bis hin zu Audioverbesserung und Videobearbeitung – zum günstigen Pay-as-you-go-Preis befreit sie Sie von GPU-Wartungsproblemen, während Sie Ihre eigenen Produkte entwickeln. Jetzt kostenlos testen.
Empfohlene Lektüre
Novita AI LLM Inference Engine: der größte Durchsatz und die günstigste Inferenz verfügbar



