

Descubra o diagrama da arquitetura LLM em nosso blog. Explore os diferentes tipos de LLMs, transformers e GPTs.
Introdução
Ao discutir inteligência artificial, os Modelos de Linguagem de Grande Escala (LLMs) surgem como inovações fundamentais, revolucionando nossas interações e compreensão das capacidades das máquinas. Impulsionados por vastos conjuntos de dados e algoritmos avançados, esses enormes frameworks de aprendizado de máquina tornaram-se pontos focais no processamento de linguagem natural.
Vamos nos aprofundar nas arquiteturas fundamentais, com foco particular nos modelos transformer predominantes. Exploraremos as metodologias de pré-treinamento que influenciaram o desenvolvimento dos LLMs e nos aprofundaremos nos domínios onde esses modelos demonstram desempenho excepcional.
O que é um LLM?
Um Modelo de Linguagem de Grande Escala (LLM) representa um algoritmo avançado de IA que utiliza redes neurais com parâmetros extensos para realizar várias tarefas de processamento de linguagem natural (PLN). Através do treinamento em conjuntos de dados textuais extensos, os LLMs se destacam em tarefas como geração de texto, tradução e sumarização, demonstrando sua habilidade em processar e gerar linguagem humana. Sua vasta escala e design intrincado os tornam indispensáveis no PLN contemporâneo, alimentando aplicações como chatbots, assistentes virtuais e ferramentas de análise de conteúdo.
Um levantamento sobre modelos de linguagem de grande escala revela sua proficiência em tarefas de geração de conteúdo, utilizando modelos transformer e treinamento em conjuntos de dados substanciais. Frequentemente referidos de forma intercambiável como redes neurais (NNs), esses sistemas computacionais ou modelos de linguagem de IA se inspiram no funcionamento do cérebro humano.

Como os LLMs funcionam?
Os Modelos de Linguagem de Grande Escala (LLMs) utilizam técnicas de aprendizado de máquina para melhorar seu desempenho aprendendo a partir de vastos conjuntos de dados. Através de métodos de aprendizado profundo e da utilização de grandes volumes de dados, os LLMs demonstram proficiência em um espectro de tarefas de Processamento de Linguagem Natural (PLN).
A arquitetura transformer, renomada por seu mecanismo de autoatenção, é uma estrutura fundamental para inúmeros LLMs. Esses modelos exibem versatilidade em lidar com várias tarefas relacionadas à linguagem, que vão desde geração de texto e tradução automática até sumarização, geração de imagens a partir de texto, auxílio em codificação e IA conversacional.
Confira informações mais detalhadas sobre modelos de linguagem de grande escala em nosso blog:
Como funcionam os modelos de linguagem de grande escala?
O que são Modelos de Linguagem de Grande Escala (LLMs)?
Arquitetura LLM
Com a crescente demanda por capacidades sofisticadas de processamento de linguagem, torna-se essencial aprofundar-se em arquiteturas emergentes para aplicações de Modelos de Linguagem de Grande Escala (LLMs). O design de um LLM é moldado por vários fatores, incluindo sua função pretendida, recursos computacionais disponíveis e a natureza específica das tarefas de processamento de linguagem que pretende realizar.
A arquitetura transformer, proeminentemente presente em LLMs como GPT, BERT e RAG, possui importância significativa. Além disso, para aplicações voltadas para empresas, arquiteturas alternativas de LLM, como Falcon e OPT, introduzem elementos de design especializados para atender a casos de uso distintos.

Para obter uma compreensão mais sutil de como a Geração Aumentada por Recuperação (RAG) otimiza os Modelos de Linguagem de Grande Escala, vamos nos aprofundar nos componentes fundamentais e nas etapas processuais que constituem a arquitetura LLM.
- Integração de Dados: O passo inicial envolve consolidar diversas fontes de dados, desde armazenamento em nuvem até repositórios Git ou bancos de dados como PostgreSQL, usando conectores pré-configurados.
- Vetorização Dinâmica: O texto extraído dessas fontes é fragmentado em segmentos menores, chamados “chunks”, e transformado em representações vetoriais. Modelos especializados para embeddings de texto, como o text-embedding-ada-002 da OpenAI, são utilizados para esse fim. Esses vetores são indexados continuamente para acelerar operações de busca subsequentes.
- Transformação da Consulta: A consulta de entrada do usuário é similarmente convertida em uma representação vetorial compatível, garantindo correspondência eficaz com os vetores de dados indexados para recuperação.
- Recuperação Contextual: Técnicas como Hashing Sensível à Localidade (LSH) são empregadas para identificar as correspondências mais próximas entre a consulta do usuário e os vetores de dados indexados, respeitando as restrições de tokens do modelo.
- Geração de Texto: Utilizando o contexto recuperado, LLMs fundamentais como GPT-3.5 Turbo ou Llama-2 empregam técnicas da arquitetura Transformer, como autoatenção, para gerar uma resposta apropriada.
- Interface do Usuário: Finalmente, o texto gerado é apresentado ao usuário através de interfaces como Streamlit ou ChatGPT.
Arquitetura LLM explicada
A arquitetura dos Modelos de Linguagem de Grande Escala (LLMs) consiste em múltiplas camadas, incluindo camadas feedforward, camadas de embedding e camadas de atenção. Essas camadas trabalham juntas para processar texto embedado e fazer previsões, destacando a interação dinâmica entre objetivos de design e capacidades computacionais.
Diagrama da arquitetura LLM
Abaixo está a estrutura em desenvolvimento para aplicações de Modelos de Linguagem de Grande Escala (LLMs):

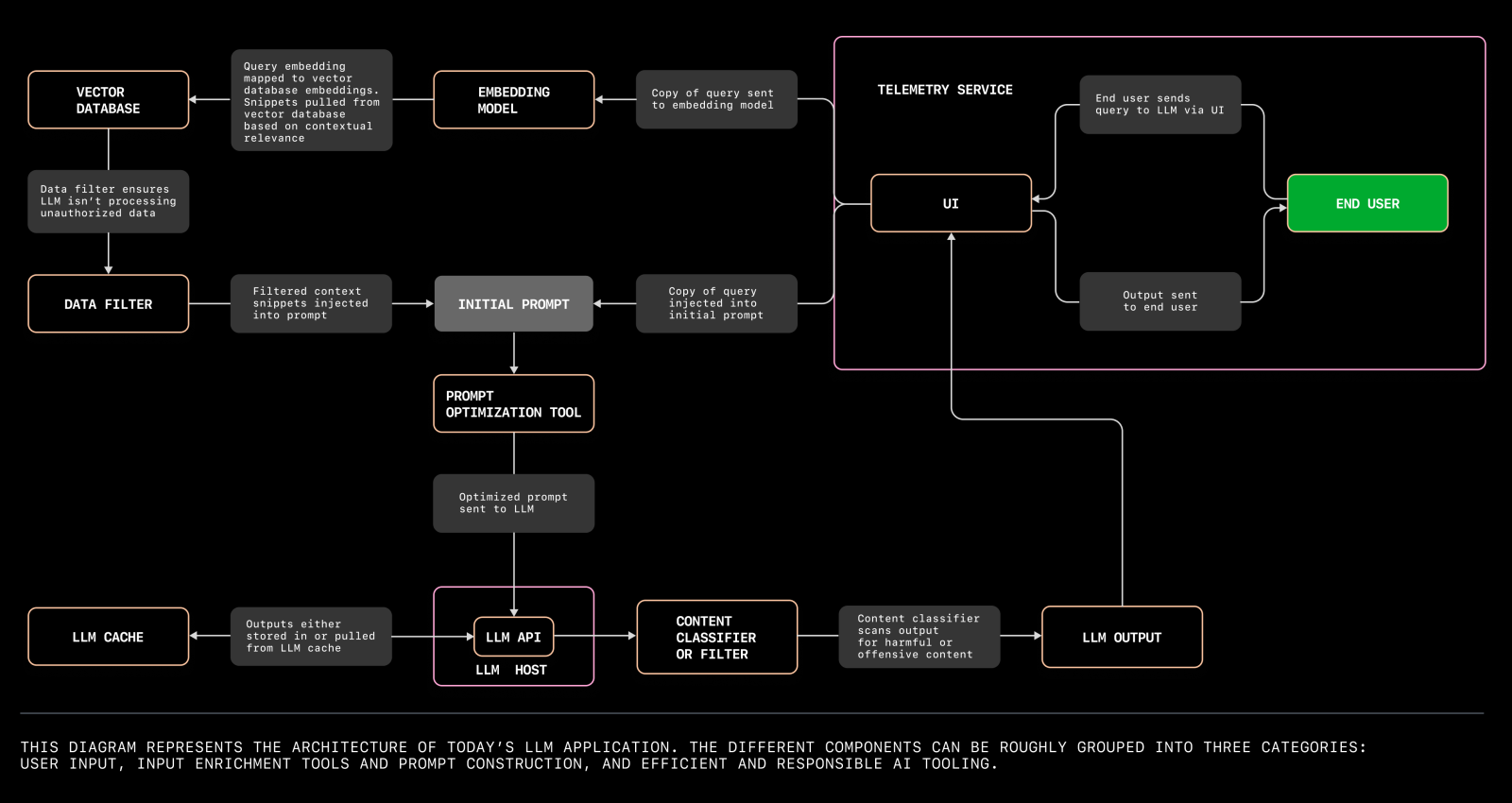
Aqui está outra arquitetura de servidor de sistema LLM:

Arquitetura Transformer
A arquitetura Transformer representa um avanço inovador no processamento de linguagem, particularmente no âmbito dos Modelos de Linguagem de Grande Escala (LLMs). Introduzido em 2017 por Ashish Vaswani e equipes do Google Brain e da Universidade de Toronto, o modelo Transformer é uma rede neural que compreende contexto e semântica analisando relações dentro de dados sequenciais, como as palavras em uma frase.
Utilizando técnicas matemáticas em evolução chamadas atenção ou autoatenção, os modelos Transformer discernem conexões intrincadas até mesmo entre elementos distantes em uma sequência. Essa arquitetura inovadora foi integrada a frameworks de aprendizado profundo proeminentes, como TensorFlow e a biblioteca Transformers da Hugging Face, ressaltando seu profundo impacto no panorama do processamento de linguagem natural.
Modelos Transformer
Vários modelos transformer, incluindo GPT, BERT, BART e T5, contribuem para o processamento de linguagem. A arquitetura transformer, reconhecida como o principal framework para Modelos de Linguagem de Grande Escala (LLMs), destaca sua adaptabilidade e importância na melhoria das funcionalidades de sistemas de IA focados em linguagem.

Transformer explicado
A operação fundamental dos modelos transformer pode ser dividida em várias etapas principais:
- Embeddings de Entrada: Inicialmente, os modelos transformer convertem sentenças de entrada em embeddings numéricos, representando o significado semântico dos tokens na sequência. Esses embeddings são aprendidos durante o treinamento ou derivados de embeddings de palavras pré-existentes para sequências de palavras.
- Codificação Posicional: Para compreender a ordem sequencial das palavras, a entrada passa por codificação posicional. Esse processo codifica a entrada com base em sua posição na sequência, facilitando a compreensão das relações contextuais entre palavras.
- Autoatenção: Os modelos transformer utilizam um mecanismo crucial chamado autoatenção, que permite ao modelo avaliar a importância de palavras individuais na sequência de entrada. Esse mecanismo de atenção permite que o modelo se concentre em palavras pertinentes e capture relações intrincadas entre elas.
- Redes Neurais Feedforward: Após a fase de autoatenção, o modelo emprega redes neurais feedforward para enriquecer a informação contida nas representações. Essa etapa contribui com insights adicionais para a compreensão da sequência de entrada pelo modelo.
- Camada de Saída: A saída final é gerada com base nas representações transformadas obtidas através das etapas anteriores, refletindo a interpretação do modelo sobre a sentença de entrada.
Arquitetura GPT
O GPT é um modelo de linguagem autoregressivo que utiliza técnicas de aprendizado profundo para gerar texto com qualidade semelhante à humana.
Vamos nos aprofundar na importância do GPT e sua arquitetura de modelo.

GPT explicado
GPT, abreviação de Generative Pre-trained Transformer (Transformer Pré-treinado Generativo), representa uma classe de Modelos de Linguagem de Grande Escala (LLMs) aptos a produzir texto semelhante ao humano, oferecendo funcionalidades em geração de conteúdo e sugestões personalizadas.
Arquitetura do modelo GPT
Construído sobre a arquitetura transformer, o modelo GPT é treinado utilizando um vasto corpus de texto. Ele lida eficientemente com 1024 tokens através da aplicação de três projeções lineares às embeddings de sequência. Cada token navega perfeitamente por todos os blocos decodificadores ao longo de sua trajetória, demonstrando a eficácia da arquitetura baseada em Transformer do GPT no tratamento de tarefas de processamento de linguagem natural.
Conclusão
Em conclusão, a exploração dos Modelos de Linguagem de Grande Escala (LLMs) e suas complexidades arquiteturais não apenas destaca seu impacto transformador na inteligência artificial e no processamento de linguagem natural, mas também serve como fonte de inspiração para inovações futuras. Desde a arquitetura Transformer fundamental até modelos especializados como GPT e BERT, os LLMs demonstram o poder do aprendizado profundo e de vastos conjuntos de dados na compreensão e geração de texto semelhante ao humano. Além da proeza técnica, os LLMs inspiram o desenvolvimento de chatbots mais inteligentes, recomendações de conteúdo personalizadas e sistemas avançados de compreensão de linguagem natural. À medida que nos aprofundamos nas capacidades dos LLMs, somos impulsionados a expandir os limites das soluções orientadas por IA e desbloquear novas possibilidades para melhorar a comunicação, otimizar processos e capacitar indivíduos em diversos domínios.
novita.ai, a plataforma única para criatividade ilimitada que oferece acesso a mais de 100 APIs. Desde geração de imagens e processamento de linguagem até aprimoramento de áudio e manipulação de vídeo, com pagamento conforme o uso acessível, ela libera você das preocupações com manutenção de GPU enquanto constrói seus próprios produtos. Experimente gratuitamente.
Leitura recomendada



