

Find out the LLM architecture diagram in our blog. Explore the different types of LLMs, transformers, and GPTs.
Introduction
When discussing artificial intelligence, Large Language Models (LLMs) emerge as pivotal innovations, revolutionizing our interactions with and comprehension of machine capabilities. Driven by extensive datasets and advanced algorithms, these colossal machine-learning frameworks have become focal points in natural language processing.
Let’s delve into the fundamental architectures, with a particular focus on the prevalent transformer models. We’ll explore the pre-training methodologies that have influenced the development of LLMs and delve into the domains where these models demonstrate exceptional performance.
What is an LLM?
A Large Language Model (LLM) represents an advanced AI algorithm employing neural networks with extensive parameters to tackle various natural language processing (NLP) tasks. Through training on extensive text datasets, LLMs excel in tasks such as text generation, translation, and summarization, showcasing their prowess in processing and generating human language. Their vast scale and intricate design render them indispensable in contemporary NLP, powering applications like chatbots, virtual assistants, and content analysis tools.
A survey of large language models reveals their adeptness in content generation tasks, leveraging transformer models and training on substantial datasets. Frequently referred to interchangeably as neural networks (NNs), these computational systems or AI language models draw inspiration from the workings of the human brain.

How do LLMs work?
Large Language Models (LLMs) utilize machine learning techniques to improve their performance by learning from extensive datasets. Through deep learning methods and the utilization of vast data, LLMs demonstrate proficiency across a spectrum of Natural Language Processing (NLP) tasks.
The transformer architecture, renowned for its self-attention mechanism, stands as a fundamental framework for numerous LLMs. These models exhibit versatility in addressing various language-related tasks, ranging from text generation and machine translation to summarization, generating images from text, coding assistance, and conversational AI.
Check more detailed information about large language models in our blog:
How Large Language Models Work?
What Are Large Language Models (LLMs)?
LLM architecture
With the increasing demand for sophisticated language processing capabilities, it becomes essential to delve into emerging architectures for Large Language Model (LLM) applications. The design of an LLM is shaped by various factors, including its intended function, available computational resources, and the specific nature of language processing tasks it seeks to undertake.
The transformer architecture, prominently featured in LLMs like GPT, BERT, and RAG, holds significant importance. Moreover, for enterprise-oriented applications, alternative LLM architectures such as Falcon and OPT introduce specialized design elements tailored to address distinct use cases.

To gain a nuanced comprehension of how Retrieval-Augmented Generation (RAG) optimizes Large Language Models, let’s delve into the fundamental components and procedural stages constituting the LLM architecture.
- Data Integration: The initial step involves consolidating diverse data sources, ranging from cloud storage to Git repositories or databases like PostgreSQL, using pre-configured connectors.
- Dynamic Vectorization: Text extracted from these sources is fragmented into smaller segments, termed “chunks,” and transformed into vector representations. Specialized models for text embeddings, such as OpenAI’s text-embedding-ada-002, are utilized for this purpose. These vectors are continuously indexed to expedite subsequent search operations.
- Query Transformation: The user’s input query is similarly converted into a compatible vector representation, ensuring effective matching with the indexed data vectors for retrieval.
- Contextual Retrieval: Techniques like Locality-Sensitive Hashing (LSH) are employed to identify the closest matches between the user query and the indexed data vectors, adhering to the model’s token constraints.
- Text Generation: Leveraging the retrieved context, foundational LLMs like GPT-3.5 Turbo or Llama-2 utilize Transformer architecture techniques such as self-attention to generate an appropriate response.
- User Interface: Finally, the generated text is presented to the user through interfaces like Streamlit or ChatGPT.
LLM architecture explained
The architecture of Large Language Models (LLMs) consists of multiple layers, including feedforward layers, embedding layers, and attention layers. These layers work together to process embedded text and make predictions, highlighting the dynamic interaction between design goals and computational capacities.
LLM architecture diagram
Below is the developing structure for Large Language Model (LLM) applications:

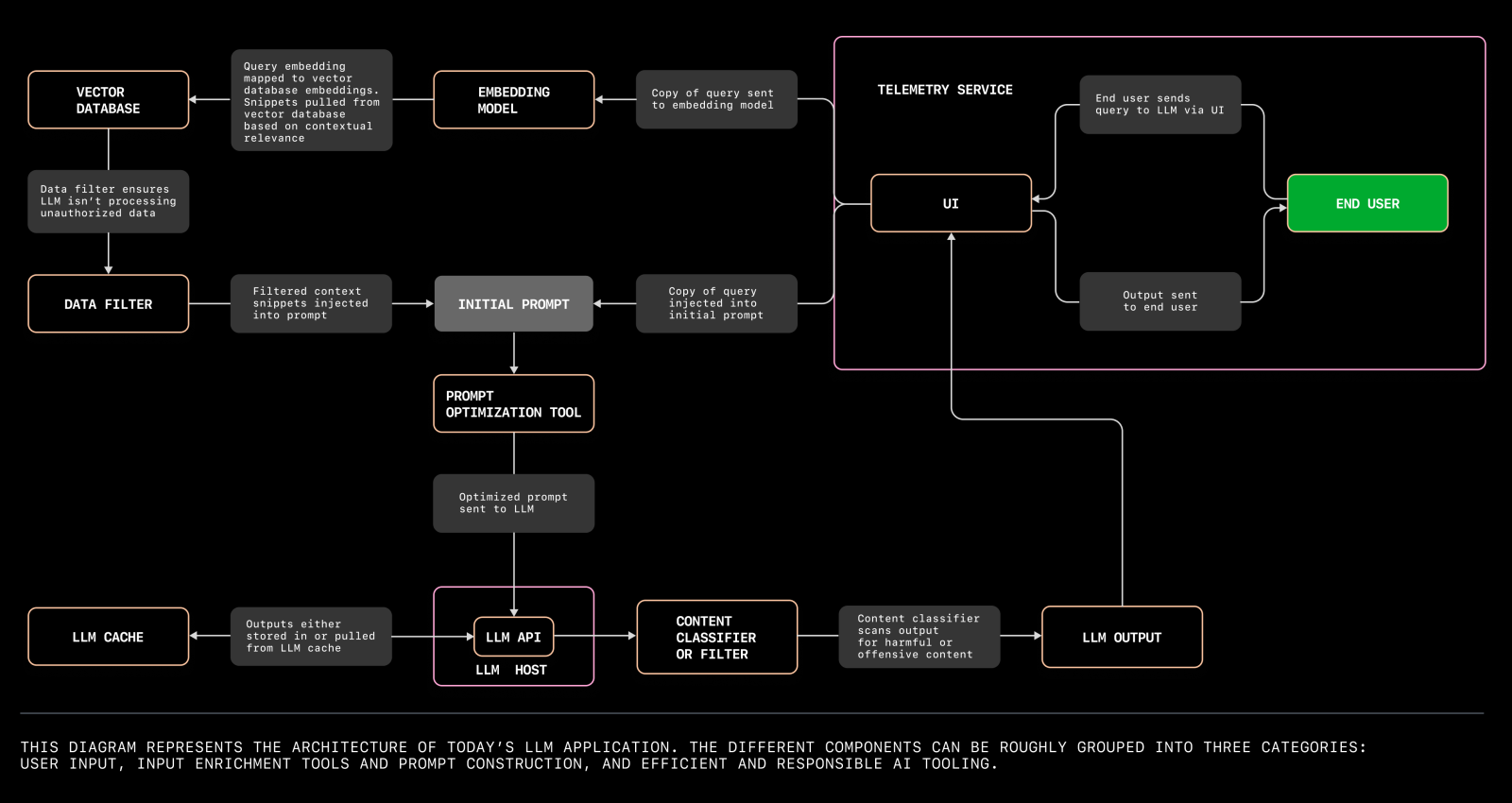
Here’s another LLM system server architecture:

Transformer architecture
The Transformer architecture stands as a groundbreaking advancement in language processing, particularly within the realm of Large Language Models (LLMs). Introduced in 2017 by Ashish Vaswani and teams from Google Brain and the University of Toronto, the Transformer model represents a neural network that grasps context and semantics by analyzing relationships within sequential data, such as the words in a sentence.
Utilizing evolving mathematical techniques termed attention or self-attention, Transformer models discern intricate connections among even distant elements in a sequence. This innovative architecture has been integrated into prominent deep learning frameworks like TensorFlow and Hugging Face’s Transformers library, underscoring its profound impact on the landscape of natural language processing.
Transformer models
Several transformer models, including GPT, BERT, BART, and T5, contribute to language processing. The transformer architecture, recognized as the leading framework for Large Language Models (LLMs), highlights its adaptability and significance in enhancing the functionalities of language-focused AI systems.

Transformer Explained
The fundamental operation of transformer models can be dissected into several key stages:
- Input Embeddings: Initially, transformer models convert input sentences into numerical embeddings, representing the semantic meaning of tokens within the sequence. These embeddings are either learned during training or derived from pre-existing word embeddings for sequences of words.
- Positional Encoding: To grasp the sequential order of words, the input undergoes positional encoding. This process encodes the input based on its position in the sequence, facilitating the model’s understanding of the contextual relationships between words.
- Self-Attention: Transformer models leverage a crucial mechanism called self-attention, allowing the model to assess the importance of individual words in the input sequence. This attention mechanism enables the model to concentrate on pertinent words and capture intricate relationships among them.
- Feed-Forward Neural Networks: Following the self-attention phase, the model employs feed-forward neural networks to enrich the information contained in the representations. This step contributes additional insights to the model’s comprehension of the input sequence.
- Output Layer: The final output is generated based on the transformed representations obtained through the preceding stages, reflecting the model’s interpretation of the input sentence.
GPT Architecture
GPT is an autoregressive language model that employs deep learning techniques to generate text resembling human-like quality.
Let’s delve into the significance of GPT and its model architecture.

GPT Explained
GPT, short for Generative Pre-trained Transformer, embodies a class of Large Language Models (LLMs) adept at producing human-like text, providing functionalities in content generation and tailored suggestions.
GPT Model Architecture
Built upon the transformer architecture, the GPT model undergoes training utilizing a vast text corpus. It efficiently handles 1024 tokens through the application of three linear projections to sequence embeddings. Each token seamlessly navigates through all decoder blocks along its trajectory, demonstrating the efficacy of GPT’s Transformer-based architecture in addressing natural language processing tasks.
Conclusion
In conclusion, the exploration of Large Language Models (LLMs) and their architectural intricacies not only highlights their transformative impact on artificial intelligence and natural language processing but also serves as a source of inspiration for future innovations. From the foundational Transformer architecture to specialized models like GPT and BERT, LLMs showcase the power of deep learning and extensive datasets in understanding and generating human-like text. Beyond technical prowess, LLMs inspire the development of smarter chatbots, personalized content recommendations, and advanced natural language understanding systems. As we delve deeper into the capabilities of LLMs, we are driven to push the boundaries of AI-driven solutions and unlock new possibilities for enhancing communication, streamlining processes, and empowering individuals across diverse domains.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
Novita AI LLM Inference Engine: the largest throughput and cheapest inference available



