

Discover what is llm and how Large Language Models are revolutionizing the field of artificial intelligence.
Introduction
Large language models (LLMs) have gained significant attention in recent years for their ability to process and understand natural language. These deep learning algorithms have revolutionized the field of natural language processing (NLP) and opened up new possibilities for applications like chatbots, translation services, sentiment analysis, and content creation.
LLMs are designed to mimic the human brain’s ability to understand and generate language. They use advanced techniques like transformer models and training on massive datasets to achieve this feat. The evolution of LLMs has paved the way for advancements in AI research and has the potential to reshape how we interact with technology.
In this blog, we will delve into the world of large language models, understanding their core components, how they work, and the applications that make them so valuable. We will also explore the impact of LLMs on society, the future directions for their development, and the limitations and challenges they face. By the end of this blog, you will have a comprehensive understanding of LLMs and their significance in the field of natural language processing.
Here is a video clip about what is a large language model:

What Are Large Language Models (LLMs)
Large language models (LLMs) are at the forefront of natural language processing (NLP) research and development. These models have the ability to understand, translate, predict, and generate text or other types of content. LLMs are a type of neural network, a computing system inspired by the human brain, and their training process involves using massive datasets to teach the model language patterns and relationships. LLMs have become an integral part of various NLP applications, enabling advancements in fields like healthcare, finance, and entertainment.

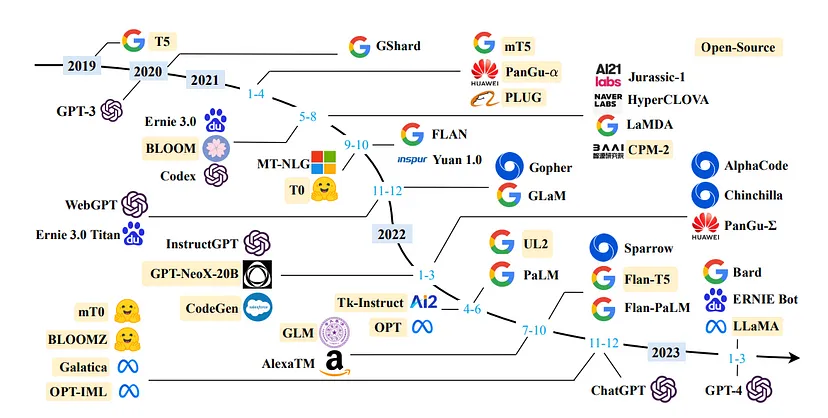
The Evolution History of Language Models
Language models have evolved significantly over the years, thanks to advancements in deep learning and generative AI. Traditional language models relied on statistical methods and rule-based approaches to process and generate text. However, the introduction of large language models (LLMs) marked a paradigm shift in the field of natural language processing (NLP).
LLMs leverage the power of deep learning and neural networks to process and understand natural language. The evolution of LLMs has propelled the field of NLP forward, creating opportunities for advancements in AI research and applications in various domains.
Core Components of LLMs
Large language models (LLMs) are composed of several core components that work together to process and generate text. These components include the architecture and design of the model, the training datasets used to train the model, and the neural network that powers the model’s functionality.
Architecture and Design
The architecture and design of large language models (LLMs) play a crucial role in their functionality and performance. LLMs often utilize transformer models, which are a type of neural network architecture that revolutionized the field of natural language processing (NLP). Transformer models leverage attention mechanisms to capture relationships between words and generate predictions.
The transformer model consists of an encoder and a decoder. The encoder processes the input text and converts it into a numerical representation, while the decoder generates the output prediction based on the encoded information. This architecture allows LLMs to efficiently process and understand natural language by considering the context and relationships between words. The attention mechanisms within the transformer model enable the model to focus on relevant parts of the input text and generate accurate predictions.
Training Datasets and Preparation
The training datasets used in large language models (LLMs) are crucial for their performance and ability to process natural language. These datasets are extensive and diverse, consisting of massive amounts of text data from sources like Wikipedia, GitHub, and other online platforms. The quality and diversity of the training data significantly impact the language model’s ability to learn patterns and relationships in text.
The training process for LLMs involves unsupervised learning, where the model processes the datasets without specific instructions. During this process, the LLM’s artificial intelligence (AI) algorithm learns the meaning of words, relationships between words, and various linguistic patterns. This pre-training phase enables the LLM to solve a wide range of text-based problems, such as text classification, question answering, document summarization, and text generation. The training datasets and the unsupervised learning approach are essential for equipping LLMs with a broad understanding of language and context.
How LLMs Work
Large language models (LLMs) work by going through a training process that enables them to process and generate text. The training process involves pre-training and fine-tuning.
Understanding the Training Process
Pre-training: LLMs are exposed to massive amounts of text data from diverse sources. This unsupervised learning phase allows the model to learn the meaning of words, relationships between words, and patterns in language. The large-scale pre-training process enables LLMs to develop a broad understanding of natural language and context.
Fine-tuning: Fine-tuning optimizes the LLM’s performance for specific applications, such as translation, sentiment analysis, or text generation. This stage involves training the model on labeled data or providing it with specific instructions to further refine its capabilities. The combination of pre-training and fine-tuning enables LLMs to perform a wide range of natural language processing tasks with remarkable accuracy.
Decoding Outputs: How LLMs Generate Text
Large language models (LLMs) generate text by decoding the inputs they receive based on their learned patterns and relationships. When given an input text, LLMs use their trained knowledge to predict the next word or phrase that is most likely to follow.
The decoding process involves leveraging the transformer architecture and attention mechanisms within LLMs. The transformer model allows the LLM to consider the entire context of a sentence or sequence of text, capturing relationships between words and generating accurate predictions. The attention mechanisms enable the model to focus on relevant parts of the input text and prioritize the most important information for generating the output.
By decoding the inputs and using their learned knowledge, LLMs can generate text that is coherent and contextually relevant. This ability makes them invaluable for tasks like text generation, language translation, and other natural language processing applications.

Key Technologies Behind LLMs
Several key technologies contribute to the development and functioning of large language models (LLMs). These technologies include transformer architecture, neural networks, and machine learning algorithms.
Transformer Models

Transformer models are a key technology behind large language models (LLMs), enabling them to process and understand natural language. These models revolutionized the field of natural language processing (NLP) by introducing the concept of self-attention mechanisms, which capture relationships between words and generate accurate predictions.
Transformer models consist of an encoder and a decoder. The encoder processes the input text, tokenizing it into numerical representations and capturing relationships between words. The decoder takes the encoded information and generates the output prediction based on the learned patterns and relationships.
The attention mechanisms within transformer models allow them to consider different parts of the sequence or the entire context of a sentence, enabling accurate predictions. This architecture and design make transformer models a powerful tool in NLP and the foundation for large language models.
Neural Networks and Machine Learning Algorithms
Neural networks and machine learning algorithms are fundamental technologies behind large language models (LLMs). Neural networks are computing systems inspired by the human brain, and they play a crucial role in the functionality of LLMs. These networks consist of multiple layers of interconnected nodes that process and generate text based on learned patterns and relationships.
Machine learning algorithms drive the training and fine-tuning process of LLMs. These algorithms enable the models to learn from massive datasets, recognize patterns in text data, and optimize their performance for specific tasks. Machine learning techniques, such as unsupervised learning, allow LLMs to process training data without specific instructions, uncovering the meaning of words and relationships between them.
The combination of neural networks and machine learning algorithms empowers LLMs to understand and generate text with remarkable accuracy, making them valuable tools in natural language processing and AI applications.
Applications of Large Language Models
Large language models (LLMs) have a wide range of applications in the field of natural language processing (NLP). LLMs are used in industries like healthcare, finance, marketing, and customer service to enhance communication and automate processes. They enable the development of chatbots, AI assistants, and other conversational interfaces. LLMs also have the potential to revolutionize content generation, enabling the creation of personalized and contextually relevant content.
Natural Language Processing (NLP) Tasks
Large language models (LLMs) excel in various natural language processing (NLP) tasks, such as sentiment analysis, language translation, and text summarization. Sentiment analysis is the process of determining the sentiment or opinion expressed in a piece of text. LLMs can analyze and classify text based on sentiment, enabling companies to gain insights into customer feedback and sentiment.

Language translation is another important NLP task where LLMs have made significant advancements. These models can translate text from one language to another with impressive accuracy, improving cross-cultural communication and accessibility.
Text summarization is the process of distilling the main points from a piece of text. LLMs can generate concise summaries that capture the essence of the original content, making them valuable tools for information retrieval and content curation.
Beyond Text: LLMs in Other Domains
While large language models (LLMs) are primarily used for text-related tasks, their capabilities extend beyond text processing. LLMs have been applied to domains like image generation, speech recognition, and information retrieval.
In image generation, LLMs can generate realistic images based on textual descriptions or prompts. This technology has applications in areas like computer graphics, virtual reality, and creative design.
Speech recognition is another domain in which LLMs have made advancements. These models can transcribe spoken language into written text, enabling technologies like voice assistants and transcription services.
LLMs are also employed in information retrieval, helping users find relevant information from large datasets or search engines. By understanding the context and intent of a search query, LLMs provide accurate and contextually relevant search results.
The Impact of LLMs on Society
Large language models (LLMs) have the potential to significantly impact society in various ways. Their advancements in AI research and natural language processing (NLP) have opened up new opportunities for applications in healthcare, finance, entertainment, and more. LLMs have the ability to automate processes, improve communication, and enhance decision-making in various industries. However, their widespread adoption also raises ethical considerations and challenges, such as privacy concerns, biases in data and model outputs, and potential job market disruptions. It is crucial to consider the societal impact of LLMs and address these challenges to ensure responsible use of this technology.
Advancements in AI Research
These models have pushed the boundaries of what is possible in natural language processing (NLP) and language generation. LLMs like GPT-3 and ChatGPT have demonstrated remarkable capabilities in understanding and generating human-like text. The open-source nature of LLMs has also fostered collaboration and innovation in the AI research community. Foundation models, which serve as the basis for many LLMs, have provided a starting point for researchers to build upon and develop more specialized models. LLMs have accelerated the progress in AI research and set the stage for future advancements in the field.
Ethical Considerations and Challenges
These models have the potential to amplify biases present in the data they are trained on, leading to biased outputs and reinforcing existing societal inequalities. LLMs can also raise privacy concerns, as they require vast amounts of data to be trained on, potentially compromising user privacy. Additionally, the automation of tasks through LLMs may lead to job market disruptions and the need for reskilling or upskilling of workers. It is crucial to address these challenges and ensure the responsible use of LLMs to minimize their negative impact and maximize their benefits for society.
Future Directions for LLM Development
Large language models (LLMs) are continuously evolving, and their future development holds exciting possibilities. Innovations in the field of natural language processing (NLP) and deep learning techniques are likely to drive advancements in LLMs. Research and development efforts are focused on scaling LLMs, improving their efficiency, and addressing their limitations. Innovations like more efficient transformer architectures, novel training techniques, and advancements in computational infrastructure will shape the future of LLM development. These developments will enable LLMs to tackle more complex tasks, improve their performance, and expand their applications in various domains.
Innovations on the Horizon
Researchers are actively working on developing more efficient transformer architectures that can handle larger models and process text more effectively. Additionally, advancements in deep learning techniques, such as unsupervised learning and reinforcement learning, will further enhance the capabilities of LLMs. The field of natural language processing (NLP) is also exploring novel training techniques that can improve the efficiency and performance of LLMs. These innovations will drive the development of LLMs that can perform more complex tasks, understand context in a more nuanced way, and generate more accurate and contextually relevant text.
Scaling and Efficiency Improvements
As LLMs continue to grow in size, researchers are exploring ways to make their training and processing more efficient. This includes optimizing computational requirements, reducing memory usage, and improving parallel processing capabilities. Scaling LLMs to handle massive amounts of data and increasing their computational efficiency will enable them to process and generate text more effectively. These improvements will have a significant impact on the performance and applicability of LLMs in various domains, from language translation to content generation. The scaling and efficiency improvements in LLMs will open up new possibilities for their use in real-world applications and drive advancements in the field of natural language processing.
Exploring the Limitations of LLMs
While large language models (LLMs) have made significant advancements in natural language processing (NLP), they are not without limitations. Understanding these limitations is crucial for optimizing their use and addressing potential challenges. LLMs rely heavily on vast amounts of data for training and may struggle with handling domain-specific or specialized contexts. The statistical relationships learned by LLMs may lead to “hallucinations” where the model produces false or incorrect outputs. Additionally, LLMs may face challenges related to security, bias in data and outputs, and copyright infringement issues. Exploring and addressing these limitations is essential for the responsible development and use of LLMs.
Understanding the Constraints
One key constraint is the availability and quality of training data. LLMs rely on vast amounts of text data for training, and the quality and diversity of this data significantly influence their ability to understand and generate text accurately. Another constraint is the statistical nature of LLMs, which means they learn from patterns and relationships in the data they are trained on. This constraint may lead to limitations in understanding nuanced or domain-specific language. Additionally, LLMs may face computational constraints due to the sheer size and complexity of their models, requiring significant computational resources for training and processing.
Addressing the Limitations
Researchers and developers are working on strategies to mitigate the challenges posed by constraints in training data, statistical relationships, and computational resources. Techniques like fine-tuning, prompt engineering, and human feedback are employed to refine the performance of LLMs and address limitations. Fine-tuning allows LLMs to adapt to specific tasks or domains, improving their accuracy and relevance. Prompt engineering involves optimizing the instructions or queries given to LLMs to generate more accurate and contextually relevant outputs. Human feedback is also crucial for refining LLMs and identifying and addressing biases or limitations. By actively addressing these limitations, researchers and developers aim to enhance the capabilities and performance of LLMs in real-world applications.
Conclusion
Large Language Models (LLMs) represent a significant leap in the field of artificial intelligence, transforming how we interact with technology. Their intricate architecture and advanced training mechanisms enable them to comprehend and generate complex text like never before. As these models continue to evolve, they hold immense potential for revolutionizing various sectors beyond natural language processing. However, alongside their benefits, it is crucial to address ethical considerations and scalability challenges to ensure responsible and efficient deployment. Embracing the future of LLMs entails exploring innovative applications while actively mitigating limitations for a more inclusive and sustainable AI landscape.
Frequently Asked Questions
How do LLMs differ from traditional models?
LLMs have a significantly higher number of parameters and can perform a variety of tasks due to their training on massive datasets. They also leverage transformer models and attention mechanisms, enabling them to generate more accurate predictions across a wide range of natural language processing tasks.
Can LLMs understand context beyond text?
Large language models (LLMs) have the ability to understand context beyond text to some extent. Through their training on massive datasets and attention mechanisms, LLMs can capture relationships between words and generate predictions based on the context of a sentence or sequence of text.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
Novita AI LLM Inference Engine: the largest throughput and cheapest inference available



