

Descubre el diagrama de la arquitectura de LLM en nuestro blog. Explora los diferentes tipos de LLMs, transformers y GPTs.
Introducción
Al hablar de inteligencia artificial, los Grandes Modelos de Lenguaje (LLMs) emergen como innovaciones fundamentales, revolucionando nuestras interacciones y comprensión de las capacidades de las máquinas. Impulsados por extensos conjuntos de datos y algoritmos avanzados, estos enormes marcos de aprendizaje automático se han convertido en puntos focales del procesamiento del lenguaje natural.
Profundicemos en las arquitecturas fundamentales, con un enfoque particular en los modelos transformer predominantes. Exploraremos las metodologías de preentrenamiento que han influido en el desarrollo de los LLM y nos adentraremos en los dominios donde estos modelos demuestran un rendimiento excepcional.
¿Qué es un LLM?
Un Gran Modelo de Lenguaje (LLM) representa un algoritmo de IA avanzado que emplea redes neuronales con extensos parámetros para abordar diversas tareas de procesamiento del lenguaje natural (NLP). Mediante el entrenamiento en conjuntos de datos de texto extensos, los LLM sobresalen en tareas como generación de texto, traducción y resumen, demostrando su destreza en el procesamiento y generación de lenguaje humano. Su vasta escala y diseño intrincado los hacen indispensables en el NLP contemporáneo, potenciando aplicaciones como chatbots, asistentes virtuales y herramientas de análisis de contenido.
Una encuesta sobre grandes modelos de lenguaje revela su habilidad en tareas de generación de contenido, aprovechando modelos transformer y entrenándose en conjuntos de datos sustanciales. A menudo denominados indistintamente como redes neuronales (NN), estos sistemas computacionales o modelos de lenguaje de IA se inspiran en el funcionamiento del cerebro humano.

¿Cómo funcionan los LLM?
Los Grandes Modelos de Lenguaje (LLM) utilizan técnicas de aprendizaje automático para mejorar su rendimiento aprendiendo de conjuntos de datos extensos. A través de métodos de aprendizaje profundo y la utilización de vastos datos, los LLM demuestran competencia en un espectro de tareas de Procesamiento del Lenguaje Natural (NLP).
La arquitectura transformer, reconocida por su mecanismo de autoatención, se erige como un marco fundamental para numerosos LLM. Estos modelos exhiben versatilidad al abordar diversas tareas relacionadas con el lenguaje, que van desde la generación de texto y la traducción automática hasta el resumen, la generación de imágenes a partir de texto, la asistencia en codificación y la IA conversacional.
Consulta información más detallada sobre los grandes modelos de lenguaje en nuestro blog:
¿Cómo funcionan los grandes modelos de lenguaje?
¿Qué son los grandes modelos de lenguaje (LLM)?
Arquitectura de LLM
Con la creciente demanda de capacidades sofisticadas de procesamiento del lenguaje, se vuelve esencial profundizar en las arquitecturas emergentes para aplicaciones de Grandes Modelos de Lenguaje (LLM). El diseño de un LLM está moldeado por varios factores, incluida su función prevista, los recursos computacionales disponibles y la naturaleza específica de las tareas de procesamiento del lenguaje que pretende abordar.
La arquitectura transformer, destacada prominentemente en LLM como GPT, BERT y RAG, tiene una importancia significativa. Además, para aplicaciones orientadas a empresas, arquitecturas alternativas de LLM como Falcon y OPT introducen elementos de diseño especializados para abordar casos de uso distintos.

Para obtener una comprensión matizada de cómo la Generación Aumentada por Recuperación (RAG) optimiza los Grandes Modelos de Lenguaje, profundicemos en los componentes fundamentales y las etapas procedimentales que constituyen la arquitectura del LLM.
- Integración de datos: El paso inicial implica consolidar diversas fuentes de datos, desde almacenamiento en la nube hasta repositorios Git o bases de datos como PostgreSQL, utilizando conectores preconfigurados.
- Vectorización dinámica: El texto extraído de estas fuentes se fragmenta en segmentos más pequeños, denominados «fragmentos» (chunks), y se transforma en representaciones vectoriales. Se utilizan modelos especializados para incrustaciones de texto (text embeddings), como text-embedding-ada-002 de OpenAI. Estos vectores se indexan continuamente para agilizar las operaciones de búsqueda posteriores.
- Transformación de consulta: La consulta de entrada del usuario se convierte de manera similar en una representación vectorial compatible, lo que garantiza una coincidencia efectiva con los vectores de datos indexados para su recuperación.
- Recuperación contextual: Se emplean técnicas como el Hash Sensible a la Localidad (LSH) para identificar las coincidencias más cercanas entre la consulta del usuario y los vectores de datos indexados, respetando las restricciones de tokens del modelo.
- Generación de texto: Aprovechando el contexto recuperado, los LLM fundamentales como GPT-3.5 Turbo o Llama-2 utilizan técnicas de la arquitectura Transformer, como la autoatención, para generar una respuesta adecuada.
- Interfaz de usuario: Finalmente, el texto generado se presenta al usuario a través de interfaces como Streamlit o ChatGPT.
Arquitectura de LLM explicada
La arquitectura de los Grandes Modelos de Lenguaje (LLM) consta de múltiples capas, incluidas capas feedforward, capas de incrustación y capas de atención. Estas capas trabajan juntas para procesar texto incrustado y hacer predicciones, destacando la interacción dinámica entre los objetivos de diseño y las capacidades computacionales.
Diagrama de arquitectura de LLM
A continuación se muestra la estructura en desarrollo para aplicaciones de Grandes Modelos de Lenguaje (LLM):

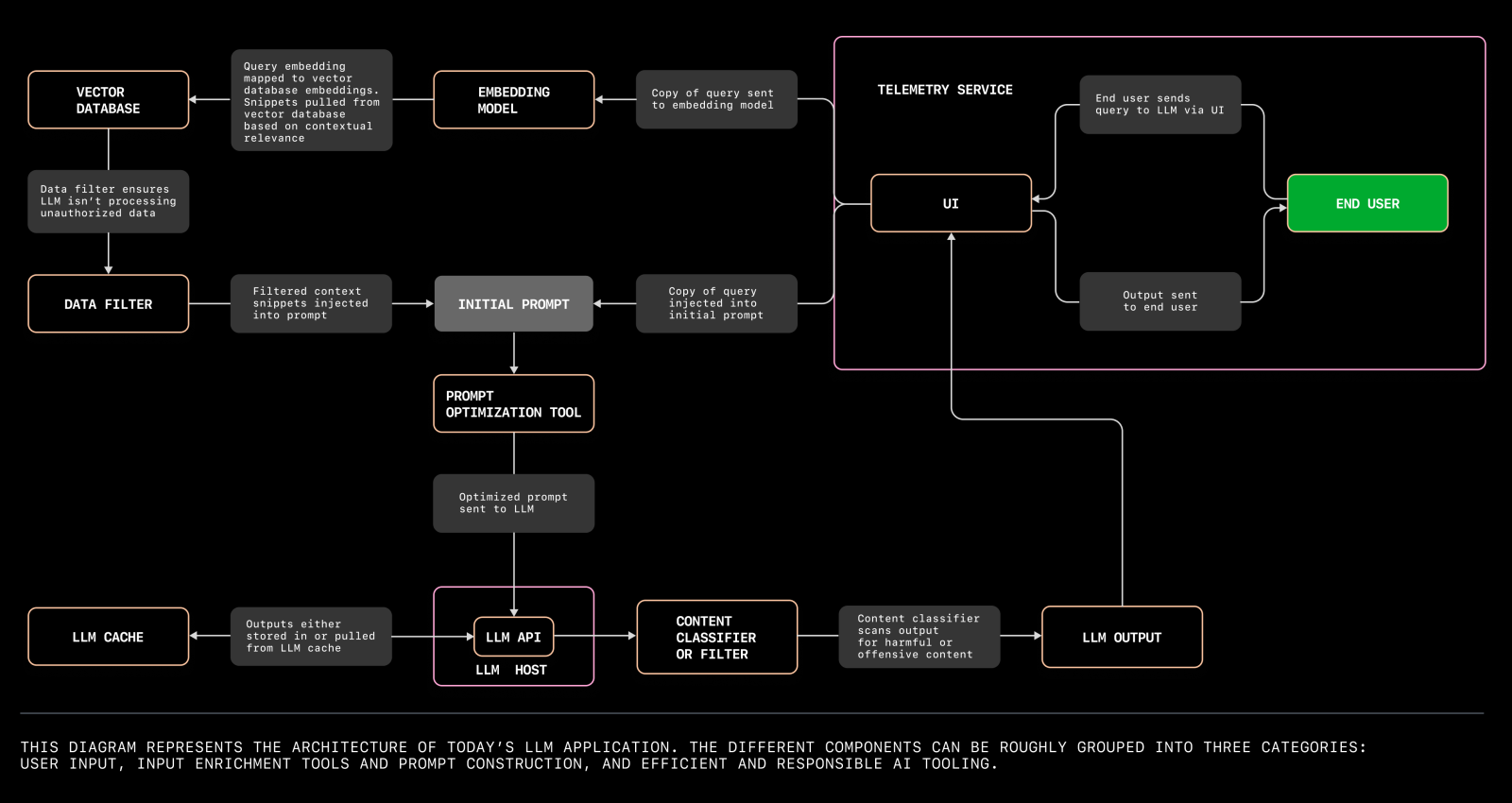
Aquí hay otra arquitectura de servidor de sistema LLM:

Arquitectura Transformer
La arquitectura Transformer se erige como un avance innovador en el procesamiento del lenguaje, particularmente en el ámbito de los Grandes Modelos de Lenguaje (LLM). Introducido en 2017 por Ashish Vaswani y equipos de Google Brain y la Universidad de Toronto, el modelo Transformer representa una red neuronal que comprende el contexto y la semántica mediante el análisis de relaciones dentro de datos secuenciales, como las palabras en una oración.
Utilizando técnicas matemáticas en evolución denominadas atención o autoatención, los modelos Transformer discernen conexiones intrincadas incluso entre elementos distantes en una secuencia. Esta innovadora arquitectura se ha integrado en marcos de aprendizaje profundo prominentes como TensorFlow y la biblioteca Transformers de Hugging Face, subrayando su profundo impacto en el panorama del procesamiento del lenguaje natural.
Modelos Transformer
Varios modelos transformer, incluidos GPT, BERT, BART y T5, contribuyen al procesamiento del lenguaje. La arquitectura transformer, reconocida como el marco principal para los Grandes Modelos de Lenguaje (LLM), destaca su adaptabilidad e importancia en la mejora de las funcionalidades de los sistemas de IA centrados en el lenguaje.

Transformer explicado
El funcionamiento fundamental de los modelos transformer se puede desglosar en varias etapas clave:
- Incrustaciones de entrada: Inicialmente, los modelos transformer convierten las oraciones de entrada en incrustaciones numéricas, que representan el significado semántico de los tokens dentro de la secuencia. Estas incrustaciones se aprenden durante el entrenamiento o se derivan de incrustaciones de palabras preexistentes para secuencias de palabras.
- Codificación posicional: Para comprender el orden secuencial de las palabras, la entrada se somete a una codificación posicional. Este proceso codifica la entrada en función de su posición en la secuencia, facilitando la comprensión del modelo de las relaciones contextuales entre las palabras.
- Autoatención: Los modelos transformer aprovechan un mecanismo crucial llamado autoatención, que permite al modelo evaluar la importancia de las palabras individuales en la secuencia de entrada. Este mecanismo de atención permite que el modelo se concentre en palabras pertinentes y capture relaciones intrincadas entre ellas.
- Redes neuronales feedforward: Después de la fase de autoatención, el modelo emplea redes neuronales feedforward para enriquecer la información contenida en las representaciones. Este paso aporta información adicional a la comprensión del modelo de la secuencia de entrada.
- Capa de salida: La salida final se genera en función de las representaciones transformadas obtenidas a través de las etapas anteriores, reflejando la interpretación del modelo de la oración de entrada.
Arquitectura GPT
GPT es un modelo de lenguaje autorregresivo que emplea técnicas de aprendizaje profundo para generar texto de calidad similar a la humana.
Profundicemos en la importancia de GPT y su arquitectura de modelo.

GPT explicado
GPT, acrónimo de Generative Pre-trained Transformer (Transformer preentrenado generativo), engloba una clase de Grandes Modelos de Lenguaje (LLM) capaces de producir texto similar al humano, proporcionando funcionalidades en la generación de contenido y sugerencias personalizadas.
Arquitectura del modelo GPT
Construido sobre la arquitectura transformer, el modelo GPT se entrena utilizando un vasto corpus de texto. Maneja eficientemente 1024 tokens mediante la aplicación de tres proyecciones lineales a las incrustaciones de secuencias. Cada token navega sin problemas a través de todos los bloques decodificadores a lo largo de su trayectoria, lo que demuestra la eficacia de la arquitectura basada en Transformer de GPT para abordar tareas de procesamiento del lenguaje natural.
Conclusión
En conclusión, la exploración de los Grandes Modelos de Lenguaje (LLM) y sus complejidades arquitectónicas no solo destaca su impacto transformador en la inteligencia artificial y el procesamiento del lenguaje natural, sino que también sirve como fuente de inspiración para futuras innovaciones. Desde la arquitectura Transformer fundamental hasta modelos especializados como GPT y BERT, los LLM muestran el poder del aprendizaje profundo y los conjuntos de datos extensos para comprender y generar texto similar al humano. Más allá de la destreza técnica, los LLM inspiran el desarrollo de chatbots más inteligentes, recomendaciones de contenido personalizadas y sistemas avanzados de comprensión del lenguaje natural. A medida que profundizamos en las capacidades de los LLM, nos impulsa a superar los límites de las soluciones impulsadas por IA y desbloquear nuevas posibilidades para mejorar la comunicación, optimizar procesos y empoderar a las personas en diversos dominios.
novita.ai, la plataforma integral para la creatividad ilimitada que te brinda acceso a más de 100 API. Desde generación de imágenes y procesamiento de lenguaje hasta mejora de audio y manipulación de video, con precios de pago por uso económicos, te libera de las molestias del mantenimiento de GPU mientras construyes tus propios productos. Pruébalo gratis.
Lectura recomendada
Motor de inferencia LLM de Novita AI: el mayor rendimiento y la inferencia más barata disponibles



